CTBench: A Comprehensive Benchmark for Evaluating Language Model Capabilities in Clinical Trial Design

0

Sign in to get full access
Overview
- This paper introduces CTBench, a comprehensive benchmark for evaluating the capabilities of large language models (LLMs) in the context of clinical trial design.
- CTBench covers a diverse range of tasks, including protocol generation, feasibility assessment, and patient recruitment, aiming to provide a holistic assessment of an LLM's suitability for clinical trial-related applications.
- The benchmark is designed to be challenging and realistic, drawing upon real-world clinical trial data and industry best practices.
Plain English Explanation
CTBench is a tool that helps researchers and developers understand how well large language models (LLMs) can perform tasks related to designing clinical trials. Clinical trials are important scientific studies that test new treatments or drugs to see if they are safe and effective.
Designing a successful clinical trial involves many complex steps, such as creating a detailed protocol, assessing the feasibility of the trial, and recruiting the right patients. CTBench is a comprehensive set of these types of tasks that can be used to evaluate how well an LLM can handle the challenges of clinical trial design.
The tasks in CTBench are based on real-world clinical trial data and industry best practices, making them highly relevant and representative of the kinds of challenges that researchers face in the real world. By using CTBench, researchers can get a better idea of which LLMs are most capable of assisting with the various aspects of clinical trial design, potentially leading to more efficient and effective trials.
Technical Explanation
The paper introduces CTBench, a benchmark designed to evaluate the capabilities of large language models (LLMs) in the context of clinical trial design. CTBench covers a diverse range of tasks, including protocol generation, feasibility assessment, and patient recruitment, with the goal of providing a comprehensive assessment of an LLM's suitability for clinical trial-related applications.
The benchmark is constructed using real-world clinical trial data and industry best practices, ensuring that the tasks are both challenging and representative of the actual challenges faced by researchers and clinicians. The paper details the process of dataset curation, task design, and evaluation metrics, highlighting the rigor and attention to detail in the benchmark's development.
Critical Analysis
The authors of the paper have made a strong case for the importance of comprehensive benchmarks like CTBench in evaluating the capabilities of LLMs for clinical applications. The inclusion of realistic tasks and real-world data sets the benchmark apart from more synthetic or simplified alternatives, such as CTIBench for cybersecurity or CS-Bench for general language understanding.
However, one potential limitation of the study is the reliance on human-annotated ground truth data for evaluation. While this approach ensures the relevance and validity of the benchmark, it may also introduce biases or inconsistencies that could impact the reliability of the results. Future work could explore the use of automated or semi-automated evaluation methods to address this concern.
Additionally, the paper does not discuss the potential ethical implications of using LLMs for clinical trial design, such as concerns around data privacy, algorithmic bias, or the potential for misuse. As these models become more integrated into healthcare workflows, it will be crucial for researchers to consider these broader societal impacts as part of their ongoing work.
Conclusion
The CTBench benchmark introduced in this paper represents a significant step forward in the evaluation of LLM capabilities for clinical applications. By providing a comprehensive and realistic set of tasks, the authors have created a valuable tool for researchers and developers to assess the suitability of these models for the complex challenges of clinical trial design.
The rigorous approach to dataset curation and task design, coupled with the emphasis on real-world relevance, sets CTBench apart as a benchmark of choice for researchers and clinicians looking to leverage the power of LLMs in their work. As the field of clinical AI continues to evolve, tools like CTBench will play an increasingly important role in ensuring that these technologies are developed and deployed in a responsible and effective manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CTBench: A Comprehensive Benchmark for Evaluating Language Model Capabilities in Clinical Trial Design
Nafis Neehal, Bowen Wang, Shayom Debopadhaya, Soham Dan, Keerthiram Murugesan, Vibha Anand, Kristin P. Bennett
CTBench is introduced as a benchmark to assess language models (LMs) in aiding clinical study design. Given study-specific metadata, CTBench evaluates AI models' ability to determine the baseline features of a clinical trial (CT), which include demographic and relevant features collected at the trial's start from all participants. These baseline features, typically presented in CT publications (often as Table 1), are crucial for characterizing study cohorts and validating results. Baseline features, including confounders and covariates, are also necessary for accurate treatment effect estimation in studies involving observational data. CTBench consists of two datasets: CT-Repo, containing baseline features from 1,690 clinical trials sourced from clinicaltrials.gov, and CT-Pub, a subset of 100 trials with more comprehensive baseline features gathered from relevant publications. Two LM-based evaluation methods are developed to compare the actual baseline feature lists against LM-generated responses. ListMatch-LM and ListMatch-BERT use GPT-4o and BERT scores (at various thresholds), respectively, for evaluation. To establish baseline results, advanced prompt engineering techniques using LLaMa3-70B-Instruct and GPT-4o in zero-shot and three-shot learning settings are applied to generate potential baseline features. The performance of GPT-4o as an evaluator is validated through human-in-the-loop evaluations on the CT-Pub dataset, where clinical experts confirm matches between actual and LM-generated features. The results highlight a promising direction with significant potential for improvement, positioning CTBench as a useful tool for advancing research on AI in CT design and potentially enhancing the efficacy and robustness of CTs.
Read more6/27/2024
0
CliBench: Multifaceted Evaluation of Large Language Models in Clinical Decisions on Diagnoses, Procedures, Lab Tests Orders and Prescriptions
Mingyu Derek Ma, Chenchen Ye, Yu Yan, Xiaoxuan Wang, Peipei Ping, Timothy S Chang, Wei Wang
The integration of Artificial Intelligence (AI), especially Large Language Models (LLMs), into the clinical diagnosis process offers significant potential to improve the efficiency and accessibility of medical care. While LLMs have shown some promise in the medical domain, their application in clinical diagnosis remains underexplored, especially in real-world clinical practice, where highly sophisticated, patient-specific decisions need to be made. Current evaluations of LLMs in this field are often narrow in scope, focusing on specific diseases or specialties and employing simplified diagnostic tasks. To bridge this gap, we introduce CliBench, a novel benchmark developed from the MIMIC IV dataset, offering a comprehensive and realistic assessment of LLMs' capabilities in clinical diagnosis. This benchmark not only covers diagnoses from a diverse range of medical cases across various specialties but also incorporates tasks of clinical significance: treatment procedure identification, lab test ordering and medication prescriptions. Supported by structured output ontologies, CliBench enables a precise and multi-granular evaluation, offering an in-depth understanding of LLM's capability on diverse clinical tasks of desired granularity. We conduct a zero-shot evaluation of leading LLMs to assess their proficiency in clinical decision-making. Our preliminary results shed light on the potential and limitations of current LLMs in clinical settings, providing valuable insights for future advancements in LLM-powered healthcare.
Read more6/17/2024
0
CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Md Tanvirul Alam, Dipkamal Bhusal, Le Nguyen, Nidhi Rastogi
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
Read more6/26/2024
0
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
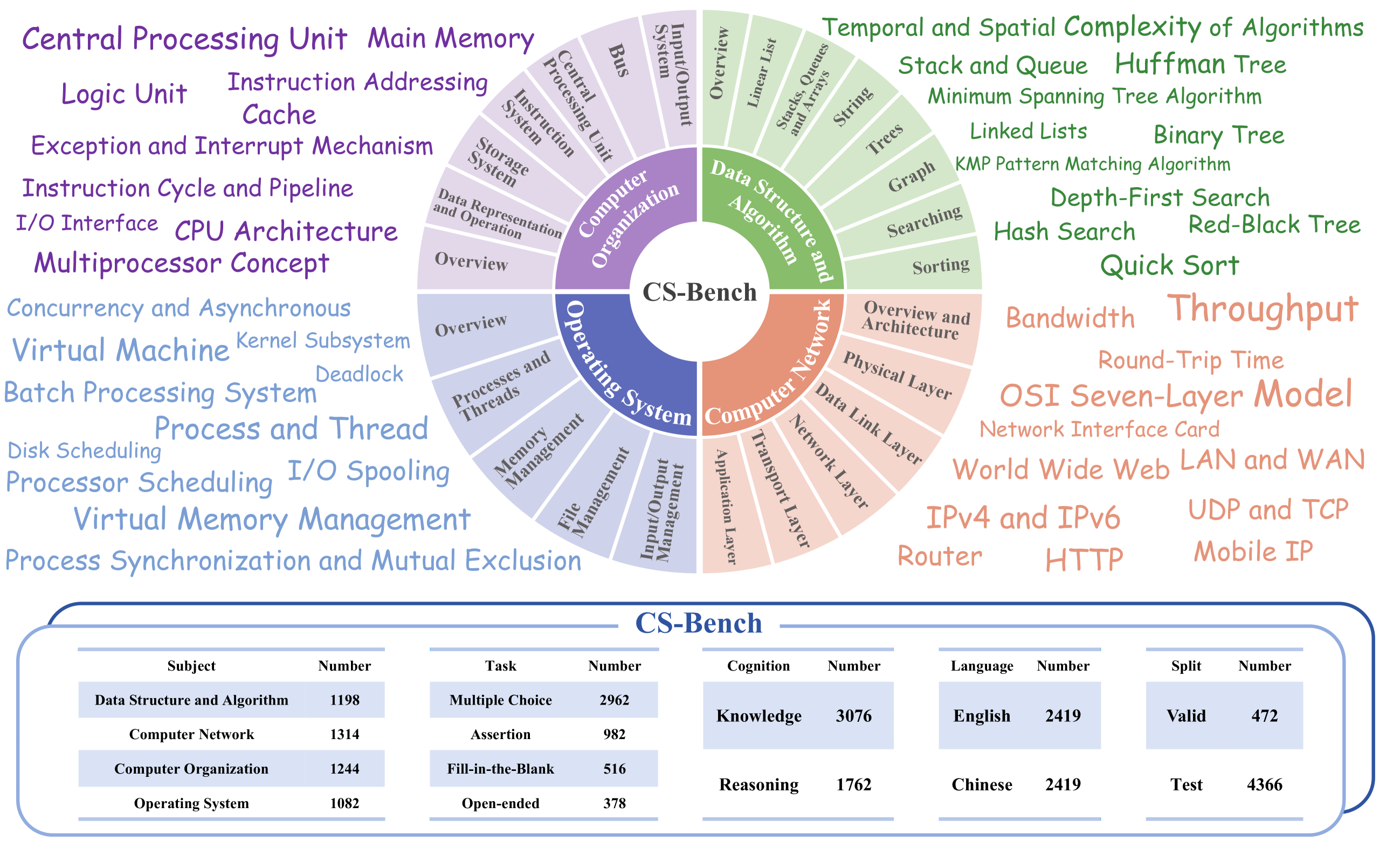
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024