CTBENCH: A Library and Benchmark for Certified Training

0
🏋️
Sign in to get full access
Overview
- Developing certifiably robust neural networks is an important but challenging task
- Many algorithms for certified training have been proposed, but they are often evaluated under different conditions, making comparison difficult
- CTBENCH is a unified library and high-quality benchmark that evaluates all certified training algorithms under fair settings with systematically tuned hyperparameters
Plain English Explanation
Neural networks, the core technology behind many modern AI systems, are powerful but can sometimes be unreliable or vulnerable to attacks. Researchers have been working on developing "certifiably robust" neural networks, which are proven to be secure and behave consistently even when faced with small changes to their inputs.
Many different algorithms have been proposed for training these robust neural networks, but GNNBench, CausalBench, AccelNASBench, LLMQBench, and FusionBench have shown that it's often difficult to compare the performance of these algorithms because they are tested in different ways.
To address this challenge, the researchers created CTBENCH, a unified library and benchmark that evaluates all the certified training algorithms under the same fair conditions, with carefully tuned hyperparameters. This allows for a more apples-to-apples comparison of the algorithms' capabilities.
Technical Explanation
The researchers found that when all the algorithms are evaluated under these fair conditions, they actually perform much better than previously reported in the literature. This establishes a new state-of-the-art for certified training. However, they also found that the claimed advantages of some of the newer algorithms drop significantly when the older baseline algorithms are also updated with fair training schedules, certification methods, and well-tuned hyperparameters.
Based on the insights gained from CTBENCH, the researchers provide recommendations for future research directions in the field of certified training. They believe that CTBENCH will serve as an important benchmark and testbed for evaluating new certified training algorithms going forward.
Critical Analysis
The researchers acknowledge that CTBENCH is not a perfect solution and that there is still room for improvement. For example, the benchmark currently only focuses on evaluating certified training algorithms on a limited set of image classification tasks. Further work is needed to expand the benchmark to cover a wider range of applications and domains.
Additionally, the researchers note that the hyperparameter tuning process used in CTBENCH, while systematic, is still a labor-intensive and time-consuming task. Developing more efficient hyperparameter optimization techniques could help make the benchmark more scalable and accessible for researchers.
Despite these limitations, CTBENCH represents a significant step forward in providing a fair and comprehensive way to evaluate certified training algorithms. By establishing a new state-of-the-art and highlighting the importance of careful experimental design, the researchers have raised the bar for future research in this important area of AI safety and robustness.
Conclusion
The CTBENCH benchmark provides a much-needed framework for fairly evaluating certified training algorithms for neural networks. By testing all algorithms under the same conditions with carefully tuned hyperparameters, the researchers have uncovered new insights about the current state of the field and set the stage for future advancements in developing reliable and secure AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
CTBENCH: A Library and Benchmark for Certified Training
Yuhao Mao, Stefan Balauca, Martin Vechev
Training certifiably robust neural networks is an important but challenging task. While many algorithms for (deterministic) certified training have been proposed, they are often evaluated on different training schedules, certification methods, and systematically under-tuned hyperparameters, making it difficult to compare their performance. To address this challenge, we introduce CTBENCH, a unified library and a high-quality benchmark for certified training that evaluates all algorithms under fair settings and systematically tuned hyperparameters. We show that (1) almost all algorithms in CTBENCH surpass the corresponding reported performance in literature in the magnitude of algorithmic improvements, thus establishing new state-of-the-art, and (2) the claimed advantage of recent algorithms drops significantly when we enhance the outdated baselines with a fair training schedule, a fair certification method and well-tuned hyperparameters. Based on CTBENCH, we provide new insights into the current state of certified training and suggest future research directions. We are confident that CTBENCH will serve as a benchmark and testbed for future research in certified training.
Read more6/10/2024

0
CTBench: A Comprehensive Benchmark for Evaluating Language Model Capabilities in Clinical Trial Design
Nafis Neehal, Bowen Wang, Shayom Debopadhaya, Soham Dan, Keerthiram Murugesan, Vibha Anand, Kristin P. Bennett
CTBench is introduced as a benchmark to assess language models (LMs) in aiding clinical study design. Given study-specific metadata, CTBench evaluates AI models' ability to determine the baseline features of a clinical trial (CT), which include demographic and relevant features collected at the trial's start from all participants. These baseline features, typically presented in CT publications (often as Table 1), are crucial for characterizing study cohorts and validating results. Baseline features, including confounders and covariates, are also necessary for accurate treatment effect estimation in studies involving observational data. CTBench consists of two datasets: CT-Repo, containing baseline features from 1,690 clinical trials sourced from clinicaltrials.gov, and CT-Pub, a subset of 100 trials with more comprehensive baseline features gathered from relevant publications. Two LM-based evaluation methods are developed to compare the actual baseline feature lists against LM-generated responses. ListMatch-LM and ListMatch-BERT use GPT-4o and BERT scores (at various thresholds), respectively, for evaluation. To establish baseline results, advanced prompt engineering techniques using LLaMa3-70B-Instruct and GPT-4o in zero-shot and three-shot learning settings are applied to generate potential baseline features. The performance of GPT-4o as an evaluator is validated through human-in-the-loop evaluations on the CT-Pub dataset, where clinical experts confirm matches between actual and LM-generated features. The results highlight a promising direction with significant potential for improvement, positioning CTBench as a useful tool for advancing research on AI in CT design and potentially enhancing the efficacy and robustness of CTs.
Read more6/27/2024
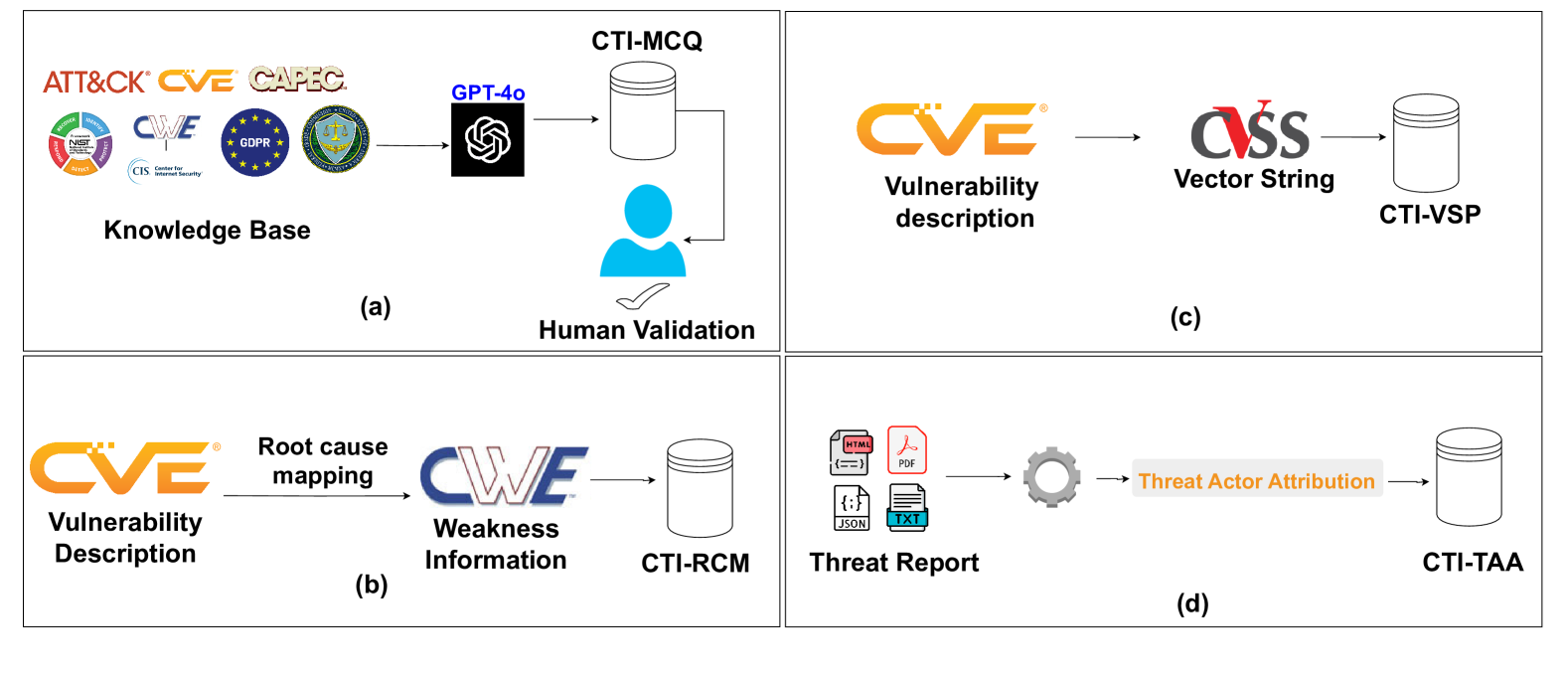
0
CTIBench: A Benchmark for Evaluating LLMs in Cyber Threat Intelligence
Md Tanvirul Alam, Dipkamal Bhusal, Le Nguyen, Nidhi Rastogi
Cyber threat intelligence (CTI) is crucial in today's cybersecurity landscape, providing essential insights to understand and mitigate the ever-evolving cyber threats. The recent rise of Large Language Models (LLMs) have shown potential in this domain, but concerns about their reliability, accuracy, and hallucinations persist. While existing benchmarks provide general evaluations of LLMs, there are no benchmarks that address the practical and applied aspects of CTI-specific tasks. To bridge this gap, we introduce CTIBench, a benchmark designed to assess LLMs' performance in CTI applications. CTIBench includes multiple datasets focused on evaluating knowledge acquired by LLMs in the cyber-threat landscape. Our evaluation of several state-of-the-art models on these tasks provides insights into their strengths and weaknesses in CTI contexts, contributing to a better understanding of LLM capabilities in CTI.
Read more6/26/2024

0
Enriching the Machine Learning Workloads in BigBench
Matthias Polag, Todor Ivanov, Timo Eichhorn
In the era of Big Data and the growing support for Machine Learning, Deep Learning and Artificial Intelligence algorithms in the current software systems, there is an urgent need of standardized application benchmarks that stress test and evaluate these new technologies. Relying on the standardized BigBench (TPCx-BB) benchmark, this work enriches the improved BigBench V2 with three new workloads and expands the coverage of machine learning algorithms. Our workloads utilize multiple algorithms and compare different implementations for the same algorithm across several popular libraries like MLlib, SystemML, Scikit-learn and Pandas, demonstrating the relevance and usability of our benchmark extension.
Read more6/18/2024