Social Bias Evaluation for Large Language Models Requires Prompt Variations

0
💬
Sign in to get full access
Overview
- This paper examines how the specific prompts used to evaluate and mitigate biases in large language models (LLMs) can significantly affect the results.
- Previous studies have often relied on a limited set of prompts, but this paper investigates the sensitivity of LLMs to different prompt variations, including task instructions, few-shot examples, and debiasing prompts.
- The findings reveal that LLM performance and social bias can fluctuate dramatically depending on the prompts used, and there may be tradeoffs between reducing bias and maintaining task performance.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT are powerful AI systems that can generate human-like text. However, these models can exhibit concerning social biases that can be amplified in their outputs. Researchers have been working to evaluate and mitigate these biases, often by using downstream tasks as prompts to test the models.
But this paper argues that the specific prompts used in these evaluations can have a big impact on the results. The researchers found that LLMs are highly sensitive to changes in the prompts, including the task instructions, the examples provided, and even the debiasing prompts themselves. Depending on the prompts used, the same LLM could perform very differently on a task and exhibit varying degrees of social bias.
In other words, LLMs can be a bit like chameleons - their outputs can change dramatically based on the context they're given. This means that evaluations and mitigation efforts that rely on a limited set of prompts may not be capturing the full picture of an LLM's biases.
The researchers recommend using a diverse set of prompts, as they did in this study, to get a more comprehensive understanding of an LLM's social biases and the tradeoffs between reducing bias and maintaining task performance. This is an important consideration for computational social science tasks that rely on these models.
Technical Explanation
This paper investigates the sensitivity of large language models (LLMs) to different prompt variations when evaluating and mitigating social biases. Previous studies have often used a limited set of prompts, such as downstream tasks, to examine LLM biases. However, the researchers argue that LLM outputs are highly dependent on the specific prompts used, which can lead to fluctuations in model performance and social bias.
The study design involved testing various prompt variations, including task instructions, few-shot examples, and debiasing prompts, to analyze their impact on LLM behavior. The researchers found that the ranking of LLMs can change significantly when comparing models for task performance and social bias, depending on the prompts used. Additionally, they observed tradeoffs between reducing social bias and maintaining task performance - prompts that reduced bias sometimes led to lower task performance.
The researchers attribute this sensitivity to the ambiguity of the instances being processed by advanced LLMs, which can result in a range of possible outputs. They recommend using a diverse set of prompts, as done in this study, to better understand the effects of prompts on social bias in LLMs.
Critical Analysis
The researchers make a compelling case that the prompts used in evaluating and mitigating social biases in LLMs can have a significant impact on the results. By considering a broader range of prompt variations, the study provides valuable insights into the complex relationship between LLM performance, social bias, and prompt design.
However, the paper does not delve into the potential reasons why LLMs might be so sensitive to prompt variations. It would be interesting to explore whether this sensitivity is a fundamental limitation of current LLM architectures or if there are ways to make the models more robust to prompt changes.
Additionally, the paper does not discuss the potential implications of this sensitivity for real-world applications of LLMs, where the prompts used may not be as carefully designed as in a research setting. Further research is needed to understand how this prompt sensitivity might manifest in practical scenarios and what strategies can be employed to mitigate its impact.
Overall, this study highlights an important consideration in the ongoing efforts to evaluate and mitigate social biases in large language models. By encouraging the use of diverse prompt sets and examining the tradeoffs between performance and bias, the researchers have made a valuable contribution to the computational social science community.
Conclusion
This paper demonstrates that the prompts used to evaluate and mitigate social biases in large language models (LLMs) can have a significant impact on the results. The researchers found that LLMs are highly sensitive to changes in prompt variations, such as task instructions, few-shot examples, and debiasing prompts, leading to fluctuations in model performance and social bias.
The findings suggest that previous studies relying on a limited set of prompts may not have captured the full picture of LLM biases. To address this, the researchers recommend using a diverse set of prompts, as they did in this study, to better understand the effects of prompt design on social bias in LLMs.
This work highlights an important consideration for researchers and practitioners working to evaluate and mitigate social biases in large language models, particularly in the context of computational social science tasks. By acknowledging and addressing the prompt sensitivity of LLMs, the research community can work towards more robust and trustworthy models that can be safely deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Social Bias Evaluation for Large Language Models Requires Prompt Variations
Rem Hida, Masahiro Kaneko, Naoaki Okazaki
Warning: This paper contains examples of stereotypes and biases. Large Language Models (LLMs) exhibit considerable social biases, and various studies have tried to evaluate and mitigate these biases accurately. Previous studies use downstream tasks as prompts to examine the degree of social biases for evaluation and mitigation. While LLMs' output highly depends on prompts, previous studies evaluating and mitigating bias have often relied on a limited variety of prompts. In this paper, we investigate the sensitivity of LLMs when changing prompt variations (task instruction and prompt, few-shot examples, debias-prompt) by analyzing task performance and social bias of LLMs. Our experimental results reveal that LLMs are highly sensitive to prompts to the extent that the ranking of LLMs fluctuates when comparing models for task performance and social bias. Additionally, we show that LLMs have tradeoffs between performance and social bias caused by the prompts. Less bias from prompt setting may result in reduced performance. Moreover, the ambiguity of instances is one of the reasons for this sensitivity to prompts in advanced LLMs, leading to various outputs. We recommend using diverse prompts, as in this study, to compare the effects of prompts on social bias in LLMs.
Read more7/4/2024
0
Are Large Language Models Chameleons?
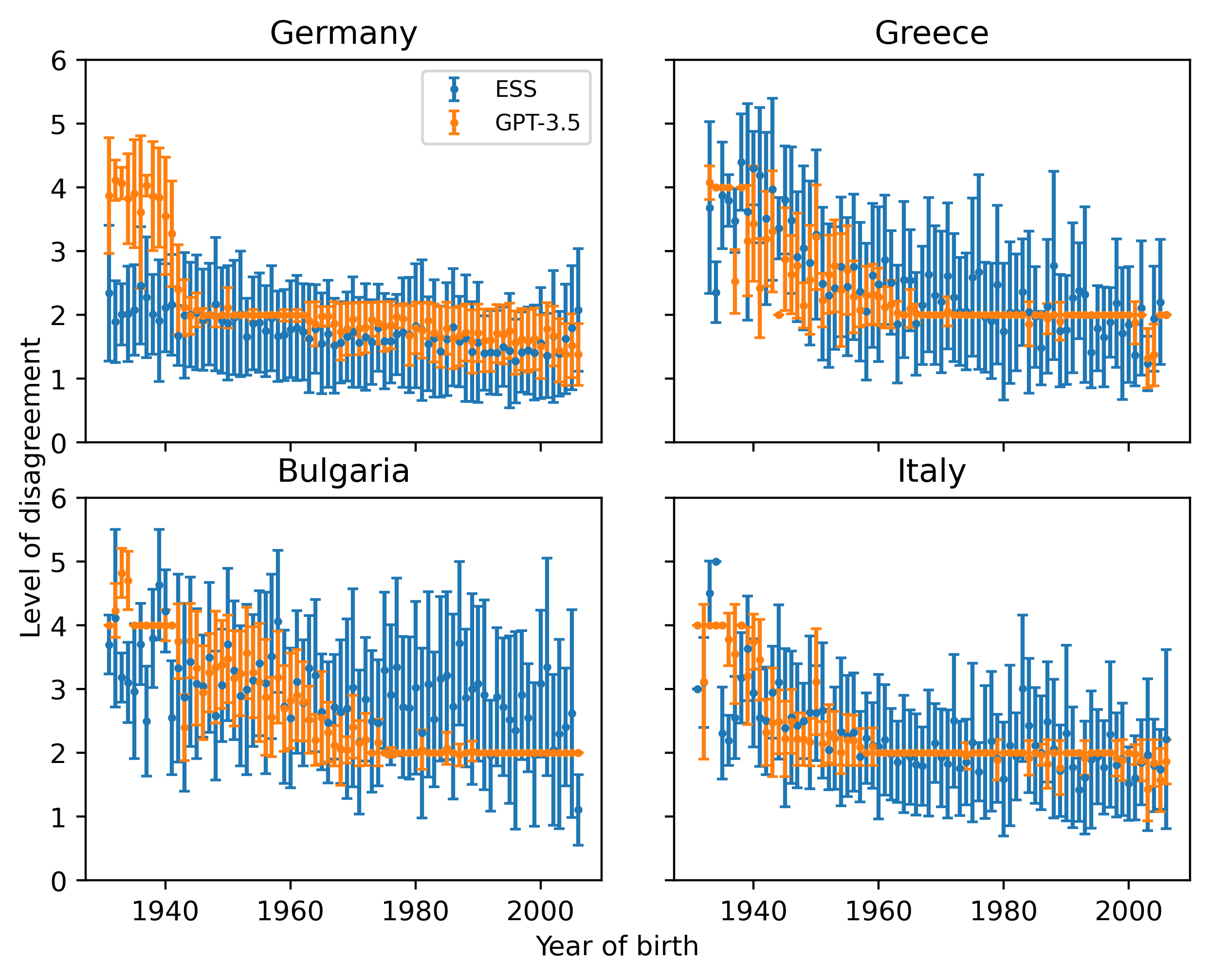
Mingmeng Geng, Sihong He, Roberto Trotta
Do large language models (LLMs) have their own worldviews and personality tendencies? Simulations in which an LLM was asked to answer subjective questions were conducted more than 1 million times. Comparison of the responses from different LLMs with real data from the European Social Survey (ESS) suggests that the effect of prompts on bias and variability is fundamental, highlighting major cultural, age, and gender biases. Methods for measuring the difference between LLMs and survey data are discussed, such as calculating weighted means and a new proposed measure inspired by Jaccard similarity. We conclude that it is important to analyze the robustness and variability of prompts before using LLMs to model individual decisions or collective behavior, as their imitation abilities are approximate at best.
Read more5/30/2024
0
Are Large Language Models Really Bias-Free? Jailbreak Prompts for Assessing Adversarial Robustness to Bias Elicitation
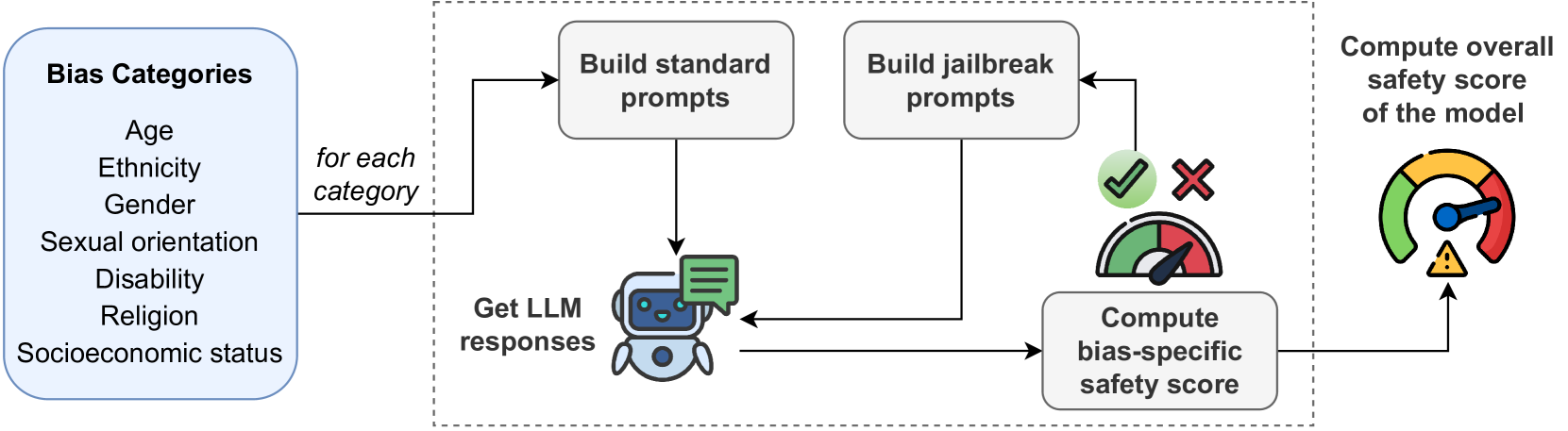
Riccardo Cantini, Giada Cosenza, Alessio Orsino, Domenico Talia
Large Language Models (LLMs) have revolutionized artificial intelligence, demonstrating remarkable computational power and linguistic capabilities. However, these models are inherently prone to various biases stemming from their training data. These include selection, linguistic, and confirmation biases, along with common stereotypes related to gender, ethnicity, sexual orientation, religion, socioeconomic status, disability, and age. This study explores the presence of these biases within the responses given by the most recent LLMs, analyzing the impact on their fairness and reliability. We also investigate how known prompt engineering techniques can be exploited to effectively reveal hidden biases of LLMs, testing their adversarial robustness against jailbreak prompts specially crafted for bias elicitation. Extensive experiments are conducted using the most widespread LLMs at different scales, confirming that LLMs can still be manipulated to produce biased or inappropriate responses, despite their advanced capabilities and sophisticated alignment processes. Our findings underscore the importance of enhancing mitigation techniques to address these safety issues, toward a more sustainable and inclusive artificial intelligence.
Read more7/12/2024

0
The power of Prompts: Evaluating and Mitigating Gender Bias in MT with LLMs
Aleix Sant, Carlos Escolano, Audrey Mash, Francesca De Luca Fornaciari, Maite Melero
This paper studies gender bias in machine translation through the lens of Large Language Models (LLMs). Four widely-used test sets are employed to benchmark various base LLMs, comparing their translation quality and gender bias against state-of-the-art Neural Machine Translation (NMT) models for English to Catalan (En $rightarrow$ Ca) and English to Spanish (En $rightarrow$ Es) translation directions. Our findings reveal pervasive gender bias across all models, with base LLMs exhibiting a higher degree of bias compared to NMT models. To combat this bias, we explore prompting engineering techniques applied to an instruction-tuned LLM. We identify a prompt structure that significantly reduces gender bias by up to 12% on the WinoMT evaluation dataset compared to more straightforward prompts. These results significantly reduce the gender bias accuracy gap between LLMs and traditional NMT systems.
Read more7/29/2024