Curriculum Direct Preference Optimization for Diffusion and Consistency Models
2405.13637
0
0
🛠️
Abstract
Direct Preference Optimization (DPO) has been proposed as an effective and efficient alternative to reinforcement learning from human feedback (RLHF). In this paper, we propose a novel and enhanced version of DPO based on curriculum learning for text-to-image generation. Our method is divided into two training stages. First, a ranking of the examples generated for each prompt is obtained by employing a reward model. Then, increasingly difficult pairs of examples are sampled and provided to a text-to-image generative (diffusion or consistency) model. Generated samples that are far apart in the ranking are considered to form easy pairs, while those that are close in the ranking form hard pairs. In other words, we use the rank difference between samples as a measure of difficulty. The sampled pairs are split into batches according to their difficulty levels, which are gradually used to train the generative model. Our approach, Curriculum DPO, is compared against state-of-the-art fine-tuning approaches on three benchmarks, outperforming the competing methods in terms of text alignment, aesthetics and human preference. Our code is available at https://anonymous.4open.science/r/Curriculum-DPO-EE14.
Create account to get full access
Overview
- This paper proposes a novel and enhanced version of Direct Preference Optimization (DPO) for text-to-image generation.
- The method, called Curriculum DPO, uses a two-stage training approach with curriculum learning.
- In the first stage, a reward model is used to rank the generated examples based on their quality.
- In the second stage, the generative model is trained on increasingly difficult pairs of examples, where difficulty is measured by the rank difference between the samples.
- The authors show that their Curriculum DPO approach outperforms state-of-the-art fine-tuning methods on text alignment, aesthetics, and human preference.
Plain English Explanation
The paper introduces an improved version of a machine learning technique called Direct Preference Optimization (DPO). DPO is an alternative to a more common approach called reinforcement learning from human feedback (RLHF).
The key idea behind the new method, called Curriculum DPO, is to use a "curriculum learning" approach. This means the model is trained on increasingly difficult examples, starting with easy ones and gradually moving to harder ones.
Here's how it works:
- First, a "reward model" is used to rank the quality of the text-to-image examples generated by the system. The best examples get a high rank, and the worse ones get a low rank.
- Then, the generative model (the one that creates the images) is trained on pairs of examples. The pairs that are far apart in the ranking are considered "easy", while the pairs that are close in the ranking are "hard".
- The easy and hard pairs are split into batches and used to train the generative model, with the difficulty level gradually increasing over time.
By using this curriculum learning approach, the authors show that their Curriculum DPO method outperforms other state-of-the-art techniques when it comes to creating text-to-image examples that are well-aligned with the text, aesthetically pleasing, and preferred by humans.
Technical Explanation
The paper proposes a novel and enhanced version of Direct Preference Optimization (DPO) for text-to-image generation, called Curriculum DPO. The method is divided into two training stages.
In the first stage, a reward model is used to obtain a ranking of the examples generated for each prompt. This reward model is trained to predict the quality of the generated images based on their text alignment and aesthetics.
In the second stage, the generative model (either a diffusion or consistency model) is trained on increasingly difficult pairs of examples. The difficulty of the pairs is determined by the rank difference between the samples - pairs that are far apart in the ranking are considered easy, while those that are close in the ranking are considered hard.
The sampled pairs are split into batches according to their difficulty levels, and these batches are gradually used to train the generative model. This curriculum learning approach, where the model is exposed to increasingly challenging examples, is the key innovation of the Curriculum DPO method.
The authors compare their Curriculum DPO approach to state-of-the-art fine-tuning methods on three benchmarks for text-to-image generation. They demonstrate that Curriculum DPO outperforms the competing methods in terms of text alignment, aesthetics, and human preference.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Curriculum DPO method, comparing it to several state-of-the-art approaches on multiple benchmarks. The authors acknowledge some limitations of their work, such as the need for a separate reward model and the potential for the curriculum learning approach to be sensitive to hyperparameter choices.
One area that could be further explored is the generalization of the Curriculum DPO method to other generative tasks beyond text-to-image, such as text-to-motion alignment or simple preference optimization. Additionally, the paper does not address the potential issues of robustness or the use of discriminator-guided DPO approaches, which could be interesting avenues for future research.
Overall, the Curriculum DPO method presented in this paper represents a significant contribution to the field of text-to-image generation and demonstrates the potential of combining DPO with curriculum learning techniques.
Conclusion
The paper introduces a novel and enhanced version of Direct Preference Optimization (DPO) called Curriculum DPO, which uses a two-stage training approach with curriculum learning for text-to-image generation. The authors show that their method outperforms state-of-the-art fine-tuning approaches on text alignment, aesthetics, and human preference.
The key innovation of Curriculum DPO is the use of a reward model to rank the generated examples, and then training the generative model on increasingly difficult pairs of examples based on their rank difference. This curriculum learning approach helps the model learn more effectively and produce higher-quality text-to-image outputs.
The paper's findings suggest that incorporating curriculum learning into DPO-based methods can be a promising direction for advancing the state of the art in text-to-image generation and potentially other generative tasks as well.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion-RPO: Aligning Diffusion Models through Relative Preference Optimization
Yi Gu, Zhendong Wang, Yueqin Yin, Yujia Xie, Mingyuan Zhou
0
0
Aligning large language models with human preferences has emerged as a critical focus in language modeling research. Yet, integrating preference learning into Text-to-Image (T2I) generative models is still relatively uncharted territory. The Diffusion-DPO technique made initial strides by employing pairwise preference learning in diffusion models tailored for specific text prompts. We introduce Diffusion-RPO, a new method designed to align diffusion-based T2I models with human preferences more effectively. This approach leverages both prompt-image pairs with identical prompts and those with semantically related content across various modalities. Furthermore, we have developed a new evaluation metric, style alignment, aimed at overcoming the challenges of high costs, low reproducibility, and limited interpretability prevalent in current evaluations of human preference alignment. Our findings demonstrate that Diffusion-RPO outperforms established methods such as Supervised Fine-Tuning and Diffusion-DPO in tuning Stable Diffusion versions 1.5 and XL-1.0, achieving superior results in both automated evaluations of human preferences and style alignment. Our code is available at https://github.com/yigu1008/Diffusion-RPO
6/11/2024
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
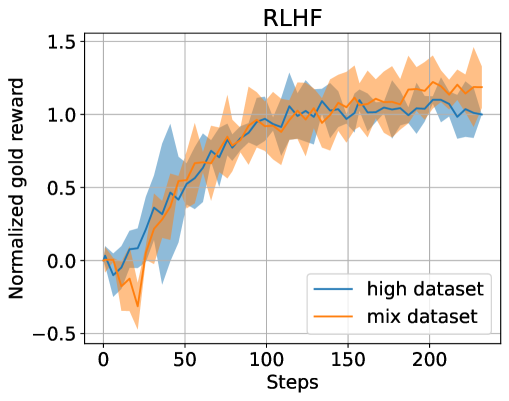
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024
Mallows-DPO: Fine-Tune Your LLM with Preference Dispersions
Haoxian Chen, Hanyang Zhao, Henry Lam, David Yao, Wenpin Tang
0
0
Direct Preference Optimization (DPO) has recently emerged as a popular approach to improve reinforcement learning with human feedback (RLHF), leading to better techniques to fine-tune large language models (LLM). A weakness of DPO, however, lies in its lack of capability to characterize the diversity of human preferences. Inspired by Mallows' theory of preference ranking, we develop in this paper a new approach, the Mallows-DPO. A distinct feature of this approach is a dispersion index, which reflects the dispersion of human preference to prompts. We show that existing DPO models can be reduced to special cases of this dispersion index, thus unified with Mallows-DPO. More importantly, we demonstrate (empirically) how to use this dispersion index to enhance the performance of DPO in a broad array of benchmark tasks, from synthetic bandit selection to controllable generations and dialogues, while maintaining great generalization capabilities.
5/27/2024

Direct Preference Optimization With Unobserved Preference Heterogeneity
Keertana Chidambaram, Karthik Vinay Seetharaman, Vasilis Syrgkanis
0
0
RLHF has emerged as a pivotal step in aligning language models with human objectives and values. It typically involves learning a reward model from human preference data and then using reinforcement learning to update the generative model accordingly. Conversely, Direct Preference Optimization (DPO) directly optimizes the generative model with preference data, skipping reinforcement learning. However, both RLHF and DPO assume uniform preferences, overlooking the reality of diverse human annotators. This paper presents a new method to align generative models with varied human preferences. We propose an Expectation-Maximization adaptation to DPO, generating a mixture of models based on latent preference types of the annotators. We then introduce a min-max regret ensemble learning model to produce a single generative method to minimize worst-case regret among annotator subgroups with similar latent factors. Our algorithms leverage the simplicity of DPO while accommodating diverse preferences. Experimental results validate the effectiveness of our approach in producing equitable generative policies.
5/27/2024