SimPO: Simple Preference Optimization with a Reference-Free Reward
2405.14734
0
1
🛠️
Abstract
Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance simplicity and training stability. In this work, we propose SimPO, a simpler yet more effective approach. The effectiveness of SimPO is attributed to a key design: using the average log probability of a sequence as the implicit reward. This reward formulation better aligns with model generation and eliminates the need for a reference model, making it more compute and memory efficient. Additionally, we introduce a target reward margin to the Bradley-Terry objective to encourage a larger margin between the winning and losing responses, further enhancing the algorithm's performance. We compare SimPO to DPO and its latest variants across various state-of-the-art training setups, including both base and instruction-tuned models like Mistral and Llama3. We evaluated on extensive instruction-following benchmarks, including AlpacaEval 2, MT-Bench, and the recent challenging Arena-Hard benchmark. Our results demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length. Specifically, SimPO outperforms DPO by up to 6.4 points on AlpacaEval 2 and by up to 7.5 points on Arena-Hard. Our top-performing model, built on Llama3-8B-Instruct, achieves a remarkable 44.7 length-controlled win rate on AlpacaEval 2 -- surpassing Claude 3 Opus on the leaderboard, and a 33.8 win rate on Arena-Hard -- making it the strongest 8B open-source model.
Create account to get full access
Overview
- The paper proposes a new offline preference optimization algorithm called SimPO that outperforms the widely used Direct Preference Optimization (DPO) approach.
- SimPO uses the average log probability of a sequence as the implicit reward, which better aligns with model generation and is more efficient.
- The paper also introduces a target reward margin to the Bradley-Terry objective to further enhance the algorithm's performance.
- SimPO is evaluated on extensive instruction-following benchmarks and consistently outperforms existing approaches without substantially increasing response length.
Plain English Explanation
In the field of reinforcement learning, researchers often use feedback from humans to help train AI models. Direct Preference Optimization (DPO) is a popular algorithm that has been used for this purpose. However, the authors of this paper believe they can improve upon DPO with a simpler yet more effective approach called SimPO.
The key innovation in SimPO is the way it calculates the reward signal. Instead of the complex process used by DPO, SimPO simply takes the average log probability of the model's generated sequence as the reward. This reward formulation aligns better with how the model actually generates text, making the optimization process more straightforward and efficient.
Additionally, SimPO introduces a "target reward margin" into the training objective. This encourages the model to have a larger gap between its preferred responses and less preferred ones, further improving the algorithm's performance.
The authors test SimPO against DPO and its variants on a range of challenging benchmarks for instruction-following AI models. The results show that SimPO consistently outperforms the existing approaches, sometimes by a significant margin, without making the model's responses substantially longer.
For example, SimPO outperformed DPO by up to 6.4 points on the AlpacaEval 2 benchmark and by up to 7.5 points on the Arena-Hard benchmark. The authors also trained a top-performing model using Llama3-8B-Instruct, which achieved a 44.7% length-controlled win rate on AlpacaEval 2 and a 33.8% win rate on Arena-Hard, making it the strongest 8 billion parameter open-source model on these tasks.
Technical Explanation
The paper introduces a new offline preference optimization algorithm called SimPO that builds upon the widely used Direct Preference Optimization (DPO) approach. DPO is a technique used in reinforcement learning from human feedback (RLHF) to reparameterize reward functions and enhance training stability and simplicity.
SimPO's key innovation is its reward formulation. Instead of the complex process used by DPO, SimPO simply takes the average log probability of the model's generated sequence as the implicit reward. This reward formulation better aligns with model generation and eliminates the need for a reference model, making the algorithm more compute and memory efficient.
Additionally, the authors introduce a target reward margin to the Bradley-Terry objective used in SimPO. This encourages a larger margin between the winning and losing responses, further enhancing the algorithm's performance.
The authors compare SimPO to DPO and its latest variants, such as Filtered DPO, Curriculum DPO, and D2PO, across various state-of-the-art training setups. This includes both base models and instruction-tuned models like Mistral and Llama3.
The evaluation is performed on extensive instruction-following benchmarks, including AlpacaEval 2, MT-Bench, and the recent challenging Arena-Hard benchmark. The results demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length.
Specifically, SimPO outperforms DPO by up to 6.4 points on AlpacaEval 2 and by up to 7.5 points on Arena-Hard. The authors' top-performing model, built on Llama3-8B-Instruct, achieves a remarkable 44.7% length-controlled win rate on AlpacaEval 2 -- surpassing Claude 3 Opus on the leaderboard -- and a 33.8% win rate on Arena-Hard, making it the strongest 8 billion parameter open-source model on these tasks.
Critical Analysis
The paper presents a compelling case for the effectiveness of the SimPO algorithm, with extensive experimental results demonstrating its superior performance compared to existing approaches. However, the authors do acknowledge some potential limitations and areas for further research.
One potential concern is the reliance on the average log probability of the generated sequence as the reward signal. While this formulation is more efficient and aligns better with model generation, it may not capture all the nuances of human preferences. The authors suggest exploring alternative reward formulations that could further improve performance.
Additionally, the paper focuses on instruction-following benchmarks, which may not fully represent the breadth of real-world applications for these types of models. Further evaluation on a wider range of tasks and domains could provide a more comprehensive understanding of SimPO's strengths and limitations.
The authors also note that their top-performing model, built on Llama3-8B-Instruct, may not be directly applicable to all users due to potential licensing or availability restrictions. Exploring the transferability of SimPO to other model architectures and sizes could broaden its practical applicability.
Overall, the paper presents a well-designed and thoroughly evaluated approach that significantly advances the state of the art in offline preference optimization for language models. The insights and techniques developed in this work could have important implications for aligning large language models with human preferences and creating more effective and trustworthy AI systems.
Conclusion
The paper introduces a new offline preference optimization algorithm called SimPO that outperforms the widely used Direct Preference Optimization (DPO) approach. SimPO's key innovation is its use of the average log probability of a sequence as the implicit reward, which better aligns with model generation and is more efficient.
The authors also introduce a target reward margin to the training objective, further enhancing SimPO's performance. Extensive evaluations on challenging instruction-following benchmarks demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length.
The top-performing model built on Llama3-8B-Instruct achieved remarkable results, surpassing the leaderboard-leading Claude 3 Opus model. This work represents an important advancement in the field of aligning large language models with human preferences, paving the way for more effective and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
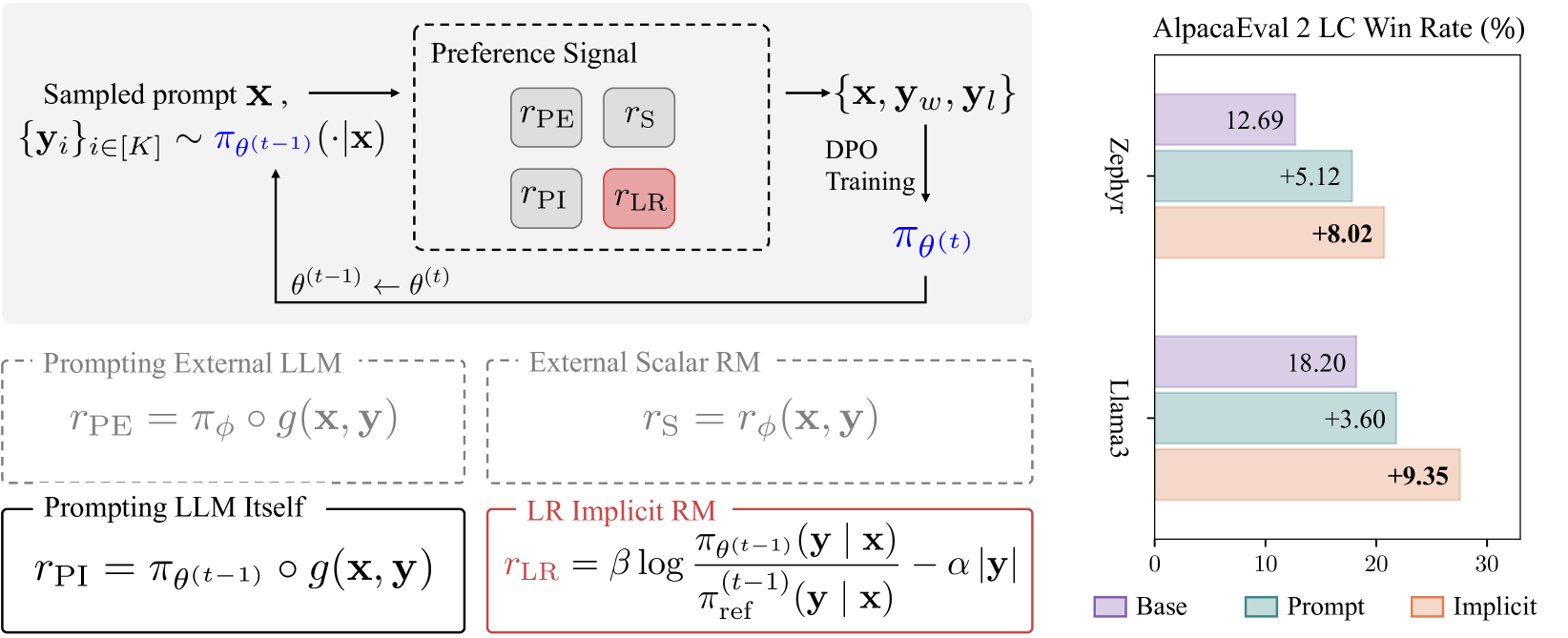
Bootstrapping Language Models with DPO Implicit Rewards
Changyu Chen, Zichen Liu, Chao Du, Tianyu Pang, Qian Liu, Arunesh Sinha, Pradeep Varakantham, Min Lin
0
0
Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.
6/17/2024

Robust Preference Optimization through Reward Model Distillation
Adam Fisch, Jacob Eisenstein, Vicky Zayats, Alekh Agarwal, Ahmad Beirami, Chirag Nagpal, Pete Shaw, Jonathan Berant
0
0
Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
5/30/2024
🛠️
Direct Multi-Turn Preference Optimization for Language Agents
Wentao Shi, Mengqi Yuan, Junkang Wu, Qifan Wang, Fuli Feng
0
0
Adapting Large Language Models (LLMs) for agent tasks is critical in developing language agents. Direct Preference Optimization (DPO) is a promising technique for this adaptation with the alleviation of compounding errors, offering a means to directly optimize Reinforcement Learning (RL) objectives. However, applying DPO to multi-turn tasks presents challenges due to the inability to cancel the partition function. Overcoming this obstacle involves making the partition function independent of the current state and addressing length disparities between preferred and dis-preferred trajectories. In this light, we replace the policy constraint with the state-action occupancy measure constraint in the RL objective and add length normalization to the Bradley-Terry model, yielding a novel loss function named DMPO for multi-turn agent tasks with theoretical explanations. Extensive experiments on three multi-turn agent task datasets confirm the effectiveness and superiority of the DMPO loss.
6/24/2024
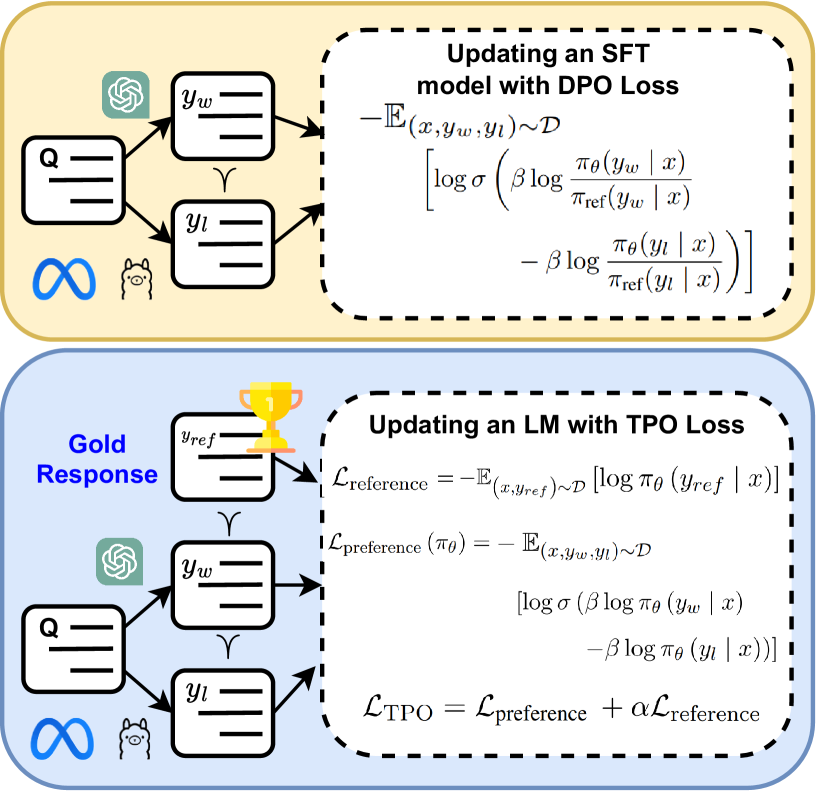
Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
Amir Saeidi, Shivanshu Verma, Aswin RRV, Chitta Baral
0
0
Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
5/28/2024