A Customer Level Fraudulent Activity Detection Benchmark for Enhancing Machine Learning Model Research and Evaluation

0
🔎
Sign in to get full access
Overview
- Addresses the need for comprehensive, privacy-compliant datasets for customer-level fraud detection
- Introduces a new benchmark that provides structured datasets with customer-centric features
- Aims to bridge the gap in data availability and empower the development of advanced fraud detection techniques
Plain English Explanation
The paper focuses on the challenge of detecting fraud at the customer level, where understanding broader customer behavior patterns is crucial. Traditionally, fraud detection datasets have focused on individual transactions, missing the bigger picture of customer behavior. However, this broader context is essential for detecting sophisticated fraud schemes.
The researchers recognized that the lack of comprehensive, privacy-compliant datasets has been a significant obstacle to advancing machine learning research and developing effective anti-fraud systems. To address this gap, they have developed a new benchmark that contains structured datasets specifically designed for customer-level fraud detection.
The key feature of this benchmark is that it adheres to strict privacy guidelines to ensure user confidentiality, while still providing a rich source of information by capturing customer-centric features. This allows researchers and practitioners to evaluate various machine learning models and gain a deeper understanding of their strengths and weaknesses in predicting fraudulent activities.
By making this benchmark available, the researchers aim to bridge the existing gap in data availability and empower the development of next-generation fraud detection techniques. This resource can help drive advancements in federated learning and other adversarially robust approaches to fraud detection.
Technical Explanation
The paper highlights the importance of having comprehensive and privacy-compliant datasets for advancing machine learning research in the field of fraud detection. Traditional datasets often focus on transaction-level information, which, while useful, fails to capture the broader context of customer behavior patterns that are essential for detecting sophisticated fraud schemes.
To address this gap, the researchers have developed a new benchmark that contains structured datasets specifically designed for customer-level fraud detection. The benchmark adheres to strict privacy guidelines to ensure user confidentiality, while providing a rich source of information by encapsulating customer-centric features.
The researchers have designed this benchmark to allow for the comprehensive evaluation of various machine learning models, facilitating a deeper understanding of their strengths and weaknesses in predicting fraudulent activities. This resource can be particularly valuable for researchers and practitioners working on federated learning and adversarially robust approaches to fraud detection.
Critical Analysis
The paper provides a valuable contribution to the field of fraud detection by addressing the critical issue of data availability and privacy concerns. The introduction of a benchmark with structured, customer-centric datasets is a significant step forward in empowering researchers and practitioners to develop more effective anti-fraud systems.
However, the paper does not delve into the specific details of the dataset, such as the types of customer-centric features included, the size and diversity of the dataset, or how the privacy-preserving measures were implemented. Additionally, the paper does not provide a comprehensive evaluation of the benchmark's performance or its impact on the development of new fraud detection techniques.
It would be interesting to see further research that explores the potential trade-offs between privacy and model performance when using this benchmark, as well as its applicability to different fraud detection scenarios and industry verticals.
Conclusion
This research paper highlights the importance of having comprehensive, privacy-compliant datasets for advancing machine learning research in the field of fraud detection. By introducing a new benchmark with structured, customer-centric datasets, the researchers have taken a significant step towards bridging the existing gap in data availability and empowering the development of next-generation fraud detection techniques.
The availability of this benchmark can drive further advancements in federated learning, adversarially robust approaches, and other innovative solutions to combat sophisticated fraud schemes. This resource can be a valuable tool for researchers and practitioners working towards more effective and privacy-preserving fraud detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
A Customer Level Fraudulent Activity Detection Benchmark for Enhancing Machine Learning Model Research and Evaluation
Phoebe Jing, Yijing Gao, Xianlong Zeng
In the field of fraud detection, the availability of comprehensive and privacy-compliant datasets is crucial for advancing machine learning research and developing effective anti-fraud systems. Traditional datasets often focus on transaction-level information, which, while useful, overlooks the broader context of customer behavior patterns that are essential for detecting sophisticated fraud schemes. The scarcity of such data, primarily due to privacy concerns, significantly hampers the development and testing of predictive models that can operate effectively at the customer level. Addressing this gap, our study introduces a benchmark that contains structured datasets specifically designed for customer-level fraud detection. The benchmark not only adheres to strict privacy guidelines to ensure user confidentiality but also provides a rich source of information by encapsulating customer-centric features. We have developed the benchmark that allows for the comprehensive evaluation of various machine learning models, facilitating a deeper understanding of their strengths and weaknesses in predicting fraudulent activities. Through this work, we seek to bridge the existing gap in data availability, offering researchers and practitioners a valuable resource that empowers the development of next-generation fraud detection techniques.
Read more4/24/2024

0
DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection
Joymallya Chakraborty, Wei Xia, Anirban Majumder, Dan Ma, Walid Chaabene, Naveed Janvekar
Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks. However, their practical application in high-stake domains, such as fraud and abuse detection, remains an area that requires further exploration. The existing applications often narrowly focus on specific tasks like toxicity or hate speech detection. In this paper, we present a comprehensive benchmark suite designed to assess the performance of LLMs in identifying and mitigating fraudulent and abusive language across various real-world scenarios. Our benchmark encompasses a diverse set of tasks, including detecting spam emails, hate speech, misogynistic language, and more. We evaluated several state-of-the-art LLMs, including models from Anthropic, Mistral AI, and the AI21 family, to provide a comprehensive assessment of their capabilities in this critical domain. The results indicate that while LLMs exhibit proficient baseline performance in individual fraud and abuse detection tasks, their performance varies considerably across tasks, particularly struggling with tasks that demand nuanced pragmatic reasoning, such as identifying diverse forms of misogynistic language. These findings have important implications for the responsible development and deployment of LLMs in high-risk applications. Our benchmark suite can serve as a tool for researchers and practitioners to systematically evaluate LLMs for multi-task fraud detection and drive the creation of more robust, trustworthy, and ethically-aligned systems for fraud and abuse detection.
Read more9/11/2024
0
Evaluating Fairness in Transaction Fraud Models: Fairness Metrics, Bias Audits, and Challenges
Parameswaran Kamalaruban, Yulu Pi, Stuart Burrell, Eleanor Drage, Piotr Skalski, Jason Wong, David Sutton
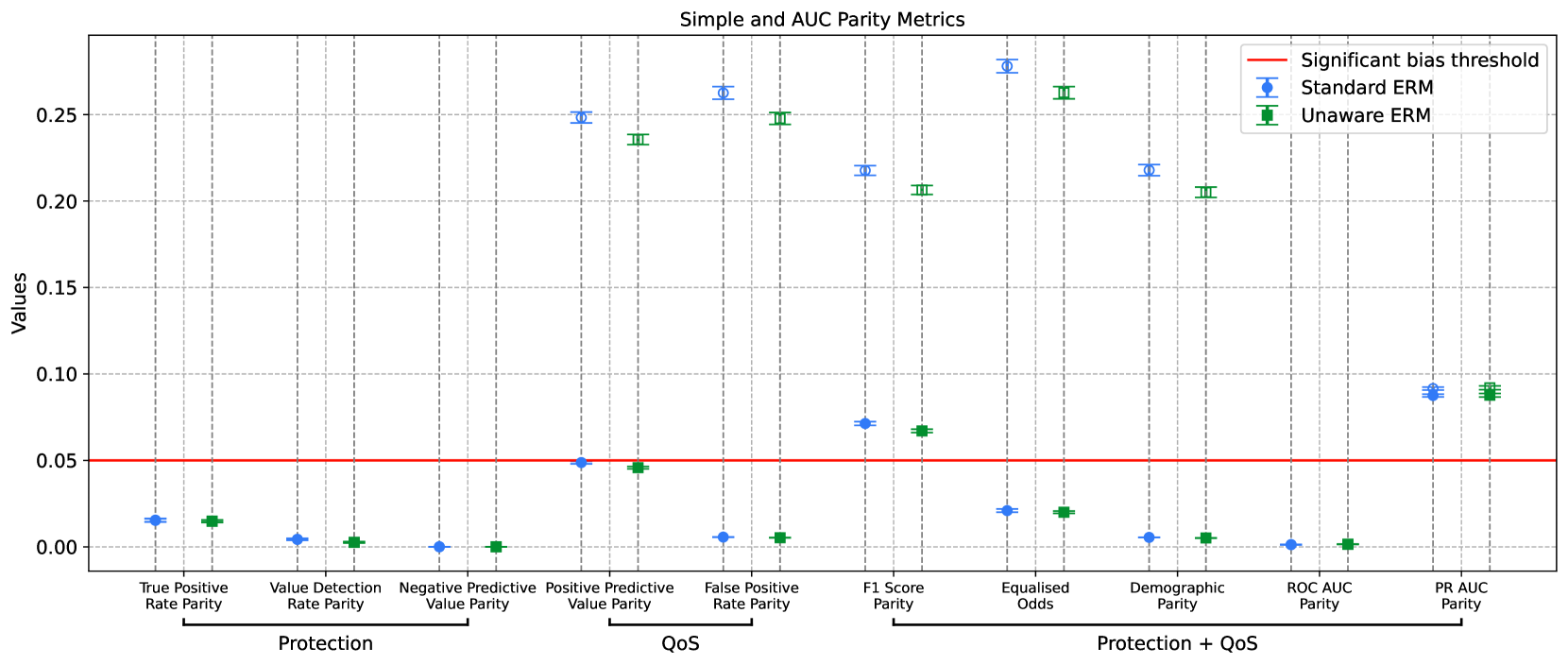
Ensuring fairness in transaction fraud detection models is vital due to the potential harms and legal implications of biased decision-making. Despite extensive research on algorithmic fairness, there is a notable gap in the study of bias in fraud detection models, mainly due to the field's unique challenges. These challenges include the need for fairness metrics that account for fraud data's imbalanced nature and the tradeoff between fraud protection and service quality. To address this gap, we present a comprehensive fairness evaluation of transaction fraud models using public synthetic datasets, marking the first algorithmic bias audit in this domain. Our findings reveal three critical insights: (1) Certain fairness metrics expose significant bias only after normalization, highlighting the impact of class imbalance. (2) Bias is significant in both service quality-related parity metrics and fraud protection-related parity metrics. (3) The fairness through unawareness approach, which involved removing sensitive attributes such as gender, does not improve bias mitigation within these datasets, likely due to the presence of correlated proxies. We also discuss socio-technical fairness-related challenges in transaction fraud models. These insights underscore the need for a nuanced approach to fairness in fraud detection, balancing protection and service quality, and moving beyond simple bias mitigation strategies. Future work must focus on refining fairness metrics and developing methods tailored to the unique complexities of the transaction fraud domain.
Read more9/9/2024
0
Credit Card Fraud Detection Using Advanced Transformer Model
Chang Yu, Yongshun Xu, Jin Cao, Ye Zhang, Yinxin Jin, Mengran Zhu
With the proliferation of various online and mobile payment systems, credit card fraud has emerged as a significant threat to financial security. This study focuses on innovative applications of the latest Transformer models for more robust and precise fraud detection. To ensure the reliability of the data, we meticulously processed the data sources, balancing the dataset to address the issue of data sparsity significantly. We also selected highly correlated vectors to strengthen the training process.To guarantee the reliability and practicality of the new Transformer model, we conducted performance comparisons with several widely adopted models, including Support Vector Machine (SVM), Random Forest, Neural Network, and Logistic Regression. We rigorously compared these models using metrics such as Precision, Recall, and F1 Score. Through these detailed analyses and comparisons, we present to the readers a highly efficient and powerful anti-fraud mechanism with promising prospects. The results demonstrate that the Transformer model not only excels in traditional applications but also shows great potential in niche areas like fraud detection, offering a substantial advancement in the field.
Read more7/29/2024