CVE-LLM : Automatic vulnerability evaluation in medical device industry using large language models

0
Sign in to get full access
Overview
- Automatic vulnerability evaluation in the medical device industry using large language models
- Proposed system called CVE-LLM to identify vulnerabilities in medical device software
- Leverages the capabilities of large language models for security assessment tasks
Plain English Explanation
The paper introduces a system called CVE-LLM that uses large language models to automatically evaluate the security vulnerabilities in medical device software. Large language models are powerful artificial intelligence systems that can understand and generate human-like text. The researchers saw an opportunity to apply these language models to the important task of identifying security weaknesses in medical devices, which can have serious consequences for patient safety if exploited by malicious actors.
The key idea behind CVE-LLM is to use the language understanding and generation capabilities of large models to scan medical device software code and documentation, and then detect and classify potential vulnerabilities. This could allow security assessments to be carried out more efficiently and comprehensively compared to manual approaches.
Technical Explanation
The paper first outlines the problem statement, highlighting the critical need for robust security practices in the medical device industry to protect patient safety. It then provides an overview of how large language models can be leveraged for vulnerability evaluation tasks.
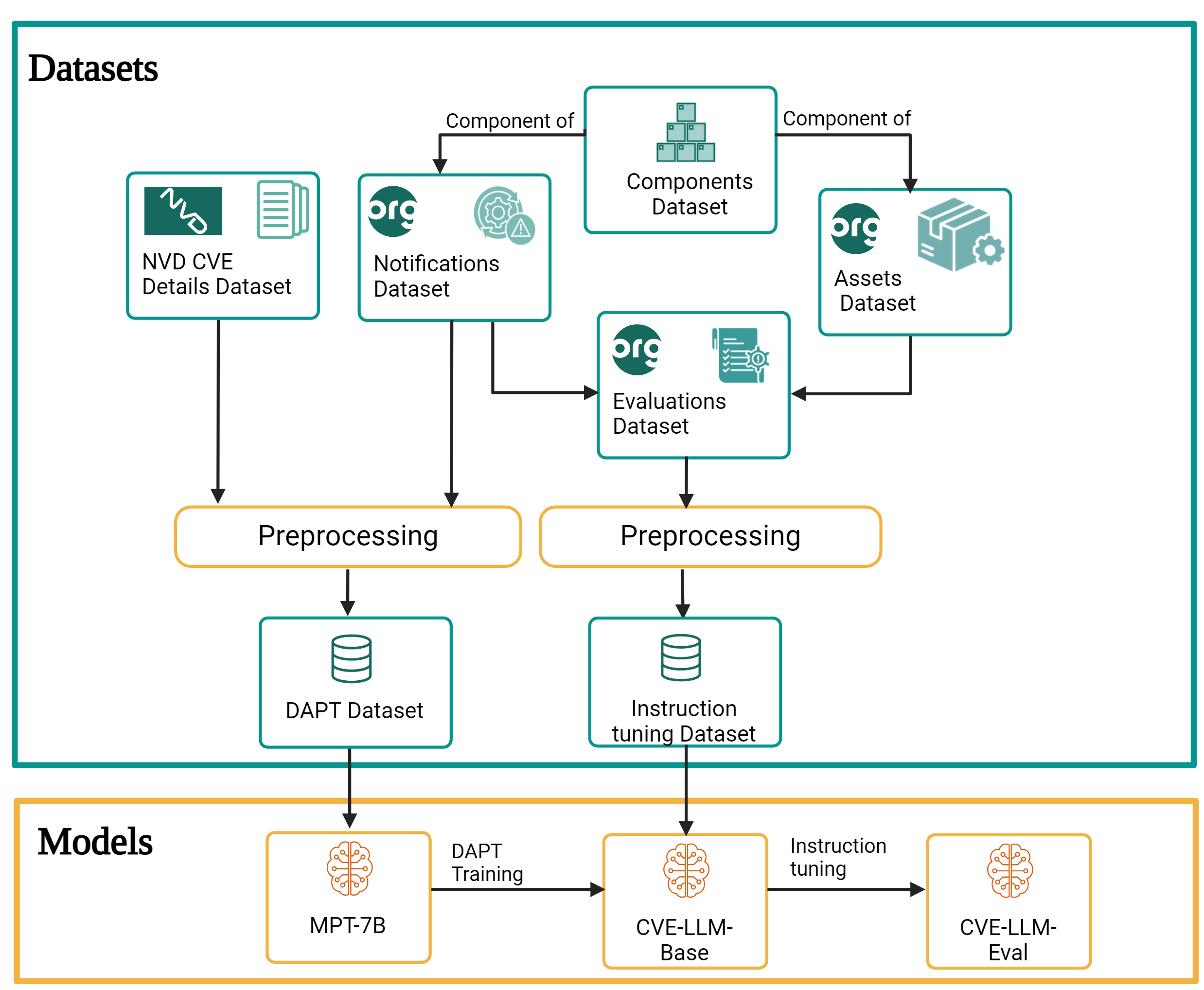
The authors describe the architecture and workflow of the CVE-LLM system, which involves:
- Pre-training the language model: Starting with a large, general-purpose language model, the researchers further train it on a corpus of software vulnerability data to specialize its understanding of security concepts.
- Vulnerability detection: The pre-trained model is then used to analyze medical device software code and documentation, identifying potential vulnerabilities based on its learned patterns.
- Vulnerability classification: The detected vulnerabilities are categorized into different types (e.g., buffer overflow, SQL injection) using the language model's understanding of vulnerability taxonomies.
The paper also outlines the experimental setup used to evaluate the performance of CVE-LLM, including the datasets, baseline methods, and evaluation metrics. The results demonstrate the system's effectiveness in detecting and classifying vulnerabilities in medical device software, outperforming traditional vulnerability scanning tools.
Critical Analysis
The paper acknowledges several limitations and areas for further research:
- The pre-training dataset may not cover all possible types of vulnerabilities, so the language model's knowledge could be incomplete.
- The system's performance may be sensitive to the specific medical device software and documentation being analyzed, requiring further testing and adaptation.
- Integrating CVE-LLM with existing security assessment workflows in the medical device industry would require additional work and validation.
Additionally, the paper does not address potential ethical concerns around the use of AI systems for security assessment, such as the risk of false positives, the need for human oversight, and the potential for misuse by bad actors.
Conclusion
The CVE-LLM system demonstrates the potential of large language models to enhance security assessment practices in the medical device industry. By automating the detection and classification of vulnerabilities, the approach could lead to more comprehensive and efficient security evaluations, ultimately improving patient safety.
However, the research also highlights the need for continued development, testing, and careful consideration of the societal implications of using such AI-powered tools in this critical domain. As the medical device industry increasingly embraces digital technologies, innovative solutions like CVE-LLM can play a vital role, but must be accompanied by robust security measures and responsible deployment practices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CVE-LLM : Automatic vulnerability evaluation in medical device industry using large language models
Rikhiya Ghosh, Oladimeji Farri, Hans-Martin von Stockhausen, Martin Schmitt, George Marica Vasile
The healthcare industry is currently experiencing an unprecedented wave of cybersecurity attacks, impacting millions of individuals. With the discovery of thousands of vulnerabilities each month, there is a pressing need to drive the automation of vulnerability assessment processes for medical devices, facilitating rapid mitigation efforts. Generative AI systems have revolutionized various industries, offering unparalleled opportunities for automation and increased efficiency. This paper presents a solution leveraging Large Language Models (LLMs) to learn from historical evaluations of vulnerabilities for the automatic assessment of vulnerabilities in the medical devices industry. This approach is applied within the portfolio of a single manufacturer, taking into account device characteristics, including existing security posture and controls. The primary contributions of this paper are threefold. Firstly, it provides a detailed examination of the best practices for training a vulnerability Language Model (LM) in an industrial context. Secondly, it presents a comprehensive comparison and insightful analysis of the effectiveness of Language Models in vulnerability assessment. Finally, it proposes a new human-in-the-loop framework to expedite vulnerability evaluation processes.
Read more7/23/2024
💬
0
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
Read more5/27/2024

0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024
💬
0
Towards Leveraging Large Language Models for Automated Medical Q&A Evaluation
Jack Krolik, Herprit Mahal, Feroz Ahmad, Gaurav Trivedi, Bahador Saket
This paper explores the potential of using Large Language Models (LLMs) to automate the evaluation of responses in medical Question and Answer (Q&A) systems, a crucial form of Natural Language Processing. Traditionally, human evaluation has been indispensable for assessing the quality of these responses. However, manual evaluation by medical professionals is time-consuming and costly. Our study examines whether LLMs can reliably replicate human evaluations by using questions derived from patient data, thereby saving valuable time for medical experts. While the findings suggest promising results, further research is needed to address more specific or complex questions that were beyond the scope of this initial investigation.
Read more9/4/2024