Can LLMs be Fooled? Investigating Vulnerabilities in LLMs

0

Sign in to get full access
Overview
- Large language models (LLMs) have become increasingly powerful, but they may also be vulnerable to adversarial attacks
- The paper investigates the vulnerabilities of LLMs and how they can be fooled
Plain English Explanation
The paper explores whether large language models (LLMs) - the powerful AI systems that can generate human-like text - can be fooled or tricked. LLMs like GPT-3 are capable of impressive feats, but the researchers wanted to see if there are weaknesses that could be exploited.
Adversarial attacks are attempts to deliberately confuse or mislead an AI system, often by making subtle changes to the input that humans may not even notice. The researchers investigated different ways these kinds of attacks could be used against LLMs, such as detecting software vulnerabilities or identifying privacy risks. They wanted to understand how resilient or vulnerable these AI systems are to such attacks.
Technical Explanation
The paper looks at several types of adversarial attacks that can be used to fool LLMs, including:
- Trigger-based attacks: Inserting subtle "triggers" into the input text that cause the model to generate a different, often unintended, output.
- Adversarial prompts: Crafting prompts that lead the model to produce biased, nonsensical, or harmful outputs.
- Data poisoning: Injecting malicious data into the training set to corrupt the model's knowledge and behavior.
The researchers conducted experiments to evaluate the vulnerability of popular LLMs like GPT-3 and T5 to these attacks. They found that the models were susceptible to all three types of attacks, with trigger-based attacks being particularly effective.
Critical Analysis
The paper provides important insights into the vulnerabilities of LLMs, which is crucial as these models become more widely deployed. While the researchers acknowledge that there are existing techniques to mitigate such attacks, the results highlight the need for continued research and development in this area.
One limitation of the study is that it focuses primarily on the technical aspects of the attacks, without deeply exploring the real-world implications or potential societal impacts. Further research could investigate how these vulnerabilities could be exploited in practice and the broader consequences for areas like cybersecurity, privacy, and trust in AI systems.
Conclusion
This paper demonstrates that LLMs, despite their impressive capabilities, can be vulnerable to various types of adversarial attacks. As these models become more prominent, it is crucial to understand and address these vulnerabilities to ensure the safe and responsible deployment of LLMs in real-world applications. The findings from this research can inform the development of more robust and secure AI systems, ultimately enhancing public trust and confidence in this transformative technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can LLMs be Fooled? Investigating Vulnerabilities in LLMs
Sara Abdali, Jia He, CJ Barberan, Richard Anarfi
The advent of Large Language Models (LLMs) has garnered significant popularity and wielded immense power across various domains within Natural Language Processing (NLP). While their capabilities are undeniably impressive, it is crucial to identify and scrutinize their vulnerabilities especially when those vulnerabilities can have costly consequences. One such LLM, trained to provide a concise summarization from medical documents could unequivocally leak personal patient data when prompted surreptitiously. This is just one of many unfortunate examples that have been unveiled and further research is necessary to comprehend the underlying reasons behind such vulnerabilities. In this study, we delve into multiple sections of vulnerabilities which are model-based, training-time, inference-time vulnerabilities, and discuss mitigation strategies including Model Editing which aims at modifying LLMs behavior, and Chroma Teaming which incorporates synergy of multiple teaming strategies to enhance LLMs' resilience. This paper will synthesize the findings from each vulnerability section and propose new directions of research and development. By understanding the focal points of current vulnerabilities, we can better anticipate and mitigate future risks, paving the road for more robust and secure LLMs.
Read more7/31/2024
0
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
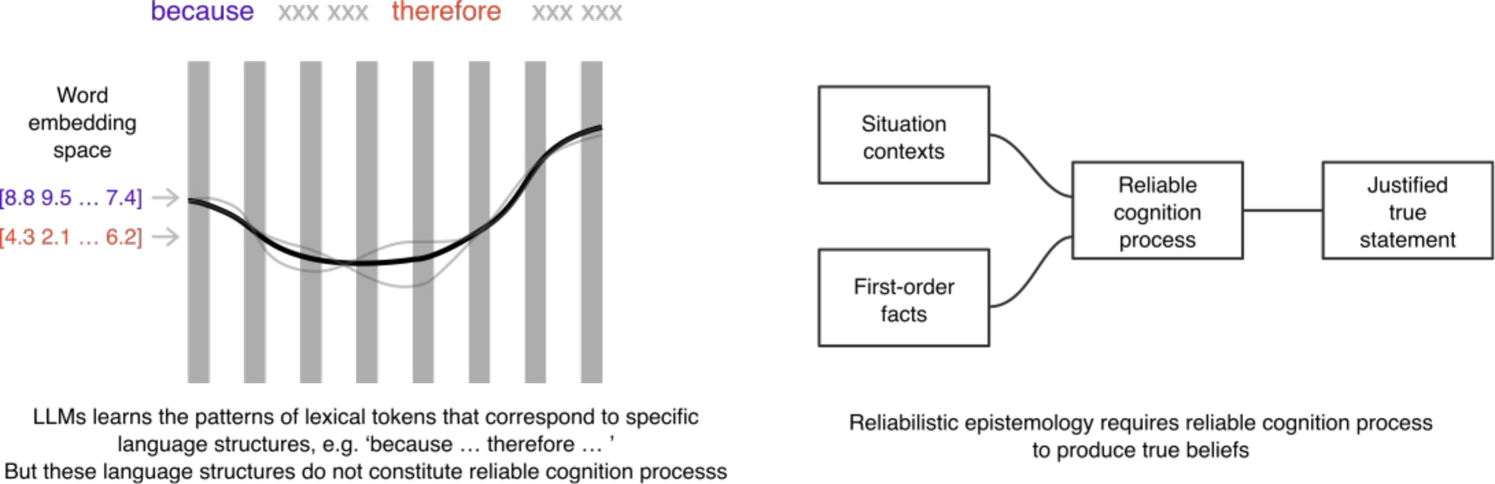
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024
0
Transforming Computer Security and Public Trust Through the Exploration of Fine-Tuning Large Language Models
Garrett Crumrine, Izzat Alsmadi, Jesus Guerrero, Yuvaraj Munian
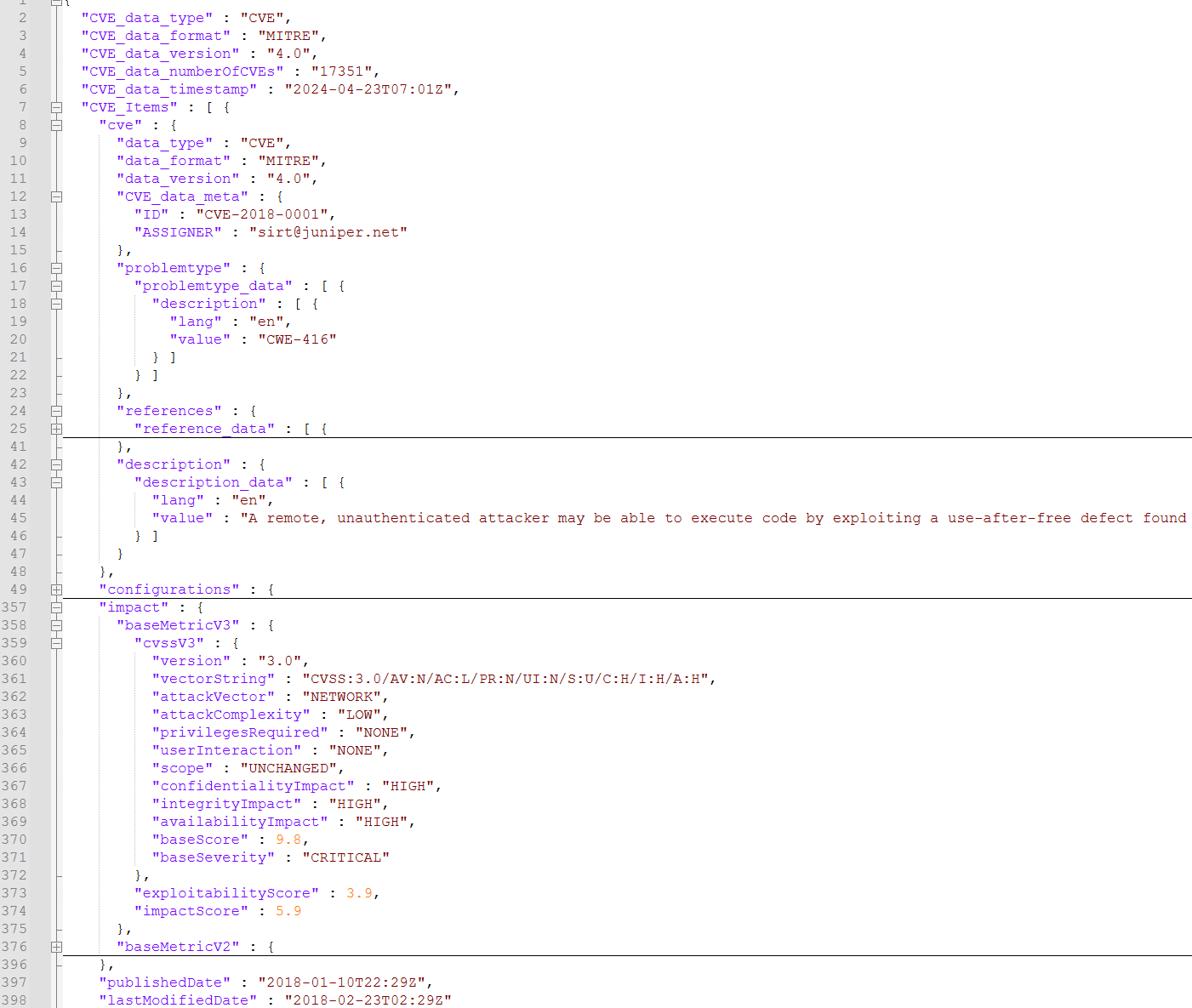
Large language models (LLMs) have revolutionized how we interact with machines. However, this technological advancement has been paralleled by the emergence of Mallas, malicious services operating underground that exploit LLMs for nefarious purposes. Such services create malware, phishing attacks, and deceptive websites, escalating the cyber security threats landscape. This paper delves into the proliferation of Mallas by examining the use of various pre-trained language models and their efficiency and vulnerabilities when misused. Building on a dataset from the Common Vulnerabilities and Exposures (CVE) program, it explores fine-tuning methodologies to generate code and explanatory text related to identified vulnerabilities. This research aims to shed light on the operational strategies and exploitation techniques of Mallas, leading to the development of more secure and trustworthy AI applications. The paper concludes by emphasizing the need for further research, enhanced safeguards, and ethical guidelines to mitigate the risks associated with the malicious application of LLMs.
Read more6/4/2024
💬
0
Recent Advances in Attack and Defense Approaches of Large Language Models
Jing Cui, Yishi Xu, Zhewei Huang, Shuchang Zhou, Jianbin Jiao, Junge Zhang
Large Language Models (LLMs) have revolutionized artificial intelligence and machine learning through their advanced text processing and generating capabilities. However, their widespread deployment has raised significant safety and reliability concerns. Established vulnerabilities in deep neural networks, coupled with emerging threat models, may compromise security evaluations and create a false sense of security. Given the extensive research in the field of LLM security, we believe that summarizing the current state of affairs will help the research community better understand the present landscape and inform future developments. This paper reviews current research on LLM vulnerabilities and threats, and evaluates the effectiveness of contemporary defense mechanisms. We analyze recent studies on attack vectors and model weaknesses, providing insights into attack mechanisms and the evolving threat landscape. We also examine current defense strategies, highlighting their strengths and limitations. By contrasting advancements in attack and defense methodologies, we identify research gaps and propose future directions to enhance LLM security. Our goal is to advance the understanding of LLM safety challenges and guide the development of more robust security measures.
Read more9/9/2024