DALL-M: Context-Aware Clinical Data Augmentation with LLMs

0

Sign in to get full access
Overview
- This paper, "DALL-M: Context-Aware Clinical Data Augmentation with LLMs," explores a novel approach to enhancing clinical datasets using large language models (LLMs).
- The researchers develop DALL-M, a system that can generate synthetic medical data by leveraging contextual information from electronic health records (EHRs).
- The goal is to address the challenge of limited annotated clinical data, which hinders the development of robust machine learning models for medical applications.
Plain English Explanation
The paper presents a technique called DALL-M, which stands for "Data Augmentation with Large Language Models." The core idea is to use powerful language models, similar to the ones that power chatbots and text generation, to create new, realistic-looking medical data that can be used to train machine learning models.
The key innovation is that DALL-M incorporates contextual information from electronic health records (EHRs) to generate more relevant and clinically-plausible synthetic data. For example, if a patient has a history of diabetes, the generated data for that patient would reflect realistic details about their condition, medications, and other relevant factors.
This is important because many medical machine learning models suffer from a lack of labeled training data. Hospitals and clinics often have large datasets of EHRs, but only a small fraction of this data is annotated and ready for training AI systems. DALL-M aims to bridge this gap by generating high-quality synthetic data that can supplement the limited real-world training data, allowing models to be trained more effectively.
By leveraging the power of large language models and incorporating contextual information, the researchers believe DALL-M can help advance the development of more accurate and robust medical AI systems, which could ultimately lead to better patient outcomes.
Technical Explanation
The researchers develop a framework called DALL-M, which stands for "Data Augmentation with Large Language Models." DALL-M is designed to generate synthetic clinical data that can be used to enhance machine learning models for various medical applications.
The core of the DALL-M system is a large language model that has been pre-trained on a diverse corpus of medical text, including clinical notes, research papers, and other relevant sources. This pre-trained model is then fine-tuned on a dataset of electronic health records (EHRs), which contain rich contextual information about patients, their medical history, diagnoses, treatments, and outcomes.
The fine-tuned model is then used to generate new, synthetic medical data that closely mimics the characteristics of the real EHR data. Importantly, DALL-M leverages the contextual information in the EHRs to ensure that the generated data is clinically plausible and consistent with the patient's medical history and condition.
For example, if a patient has a history of diabetes, the generated data for that patient would include realistic details about their blood glucose levels, medication regimen, and any associated complications. This context-aware approach helps to ensure that the synthetic data is not only realistic but also relevant and useful for training machine learning models.
The researchers evaluate the performance of DALL-M by incorporating the generated synthetic data into the training of various medical machine learning models, such as those for disease diagnosis and treatment recommendation. The results demonstrate that the DALL-M-augmented models outperform models trained on the original, limited EHR data alone, highlighting the potential of this approach to enhance the development of robust and accurate medical AI systems.
Critical Analysis
The DALL-M approach presented in this paper is a promising step towards addressing the challenge of limited annotated clinical data for training medical machine learning models. By leveraging the power of large language models and incorporating contextual information from electronic health records, the researchers have developed a system that can generate high-quality synthetic data that closely mimics real-world medical data.
One potential limitation of the DALL-M approach is the reliance on the quality and completeness of the underlying EHR data. If the EHR data is itself biased or incomplete, this could be reflected in the generated synthetic data, potentially introducing new biases or artifacts into the training data.
Additionally, while the researchers demonstrate the effectiveness of DALL-M in improving the performance of various medical machine learning models, it is important to consider the long-term implications of relying on synthetic data for model training. Careful monitoring and validation of the models' performance on real-world clinical data will be crucial to ensure that the synthetic data is not masking underlying issues or limitations in the models.
Further research could also explore ways to incorporate additional sources of contextual information, such as medical imaging data or genetic information, to enhance the realism and clinical relevance of the generated synthetic data. Incorporating these multimodal data sources could lead to even more robust and accurate medical AI systems.
Conclusion
The DALL-M framework presented in this paper represents a significant advancement in the field of clinical data augmentation. By leveraging large language models and incorporating contextual information from electronic health records, the researchers have developed a system that can generate high-quality synthetic medical data to supplement the limited annotated real-world data available for training machine learning models.
The successful integration of DALL-M-generated data into various medical AI applications demonstrates the potential of this approach to accelerate the development of more accurate and robust models for tasks such as disease diagnosis, treatment recommendation, and patient monitoring. As the field of medical AI continues to evolve, techniques like DALL-M will likely play an increasingly important role in addressing the data challenges that have historically hindered progress in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DALL-M: Context-Aware Clinical Data Augmentation with LLMs
Chihcheng Hsieh, Catarina Moreira, Isabel Blanco Nobre, Sandra Costa Sousa, Chun Ouyang, Margot Brereton, Joaquim Jorge, Jacinto C. Nascimento
X-ray images are vital in medical diagnostics, but their effectiveness is limited without clinical context. Radiologists often find chest X-rays insufficient for diagnosing underlying diseases, necessitating comprehensive clinical features and data integration. We present a novel technique to enhance the clinical context through augmentation techniques with clinical tabular data, thereby improving its applicability and reliability in AI medical diagnostics. To address this, we introduce a pioneering approach to clinical data augmentation that employs large language models (LLMs) to generate patient contextual synthetic data. This methodology is crucial for training more robust deep learning models in healthcare. It preserves the integrity of real patient data while enriching the dataset with contextually relevant synthetic features, significantly enhancing model performance. DALL-M uses a three-phase feature generation process: (i) clinical context storage, (ii) expert query generation, and (iii) context-aware feature augmentation. DALL-M generates new, clinically relevant features by synthesizing chest X-ray images and reports. Applied to 799 cases using nine features from the MIMIC-IV dataset, it created an augmented set of 91 features. This is the first work to generate contextual values for existing and new features based on patients' X-ray reports, gender, and age and to produce new contextual knowledge during data augmentation. Empirical validation with machine learning models, including Decision Trees, Random Forests, XGBoost, and TabNET, showed significant performance improvements. Incorporating augmented features increased the F1 score by 16.5% and Precision and Recall by approximately 25%. DALL-M addresses a critical gap in clinical data augmentation, offering a robust framework for generating contextually enriched datasets.
Read more7/12/2024

0
Enhancing chest X-ray datasets with privacy-preserving large language models and multi-type annotations: a data-driven approach for improved classification
Ricardo Bigolin Lanfredi, Pritam Mukherjee, Ronald Summers
In chest X-ray (CXR) image analysis, rule-based systems are usually employed to extract labels from reports for dataset releases. However, there is still room for improvement in label quality. These labelers typically output only presence labels, sometimes with binary uncertainty indicators, which limits their usefulness. Supervised deep learning models have also been developed for report labeling but lack adaptability, similar to rule-based systems. In this work, we present MAPLEZ (Medical report Annotations with Privacy-preserving Large language model using Expeditious Zero shot answers), a novel approach leveraging a locally executable Large Language Model (LLM) to extract and enhance findings labels on CXR reports. MAPLEZ extracts not only binary labels indicating the presence or absence of a finding but also the location, severity, and radiologists' uncertainty about the finding. Over eight abnormalities from five test sets, we show that our method can extract these annotations with an increase of 3.6 percentage points (pp) in macro F1 score for categorical presence annotations and more than 20 pp increase in F1 score for the location annotations over competing labelers. Additionally, using the combination of improved annotations and multi-type annotations in classification supervision, we demonstrate substantial advancements in model quality, with an increase of 1.1 pp in AUROC over models trained with annotations from the best alternative approach. We share code and annotations.
Read more8/16/2024
0
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
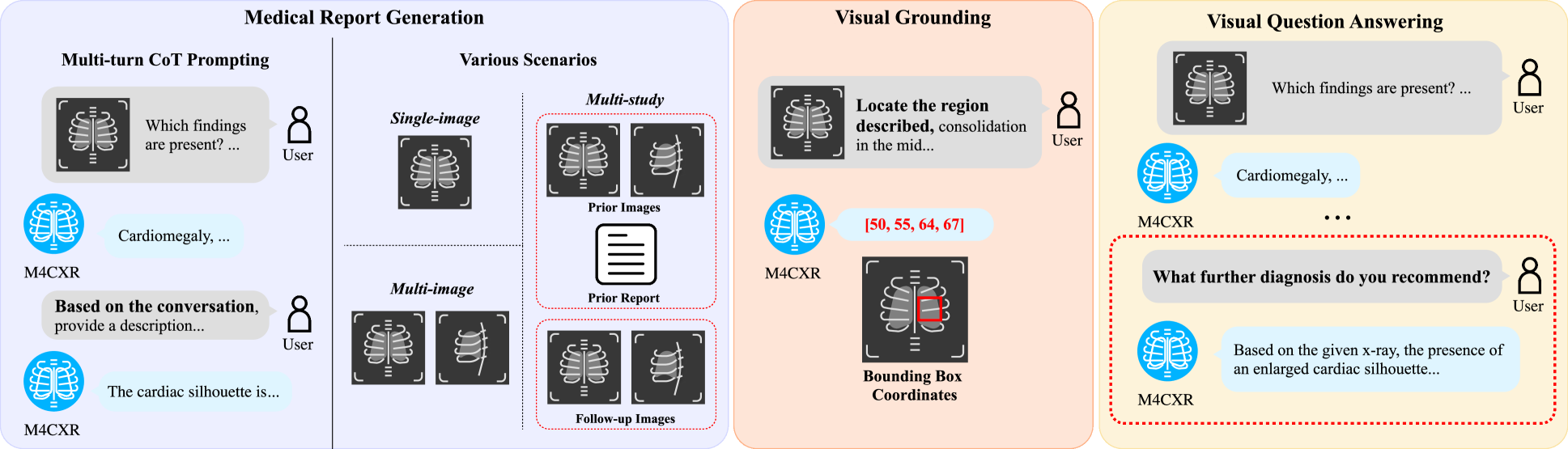
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024

0
R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation
Xiao Wang, Yuehang Li, Fuling Wang, Shiao Wang, Chuanfu Li, Bo Jiang
Inspired by the tremendous success of Large Language Models (LLMs), existing X-ray medical report generation methods attempt to leverage large models to achieve better performance. They usually adopt a Transformer to extract the visual features of a given X-ray image, and then, feed them into the LLM for text generation. How to extract more effective information for the LLMs to help them improve final results is an urgent problem that needs to be solved. Additionally, the use of visual Transformer models also brings high computational complexity. To address these issues, this paper proposes a novel context-guided efficient X-ray medical report generation framework. Specifically, we introduce the Mamba as the vision backbone with linear complexity, and the performance obtained is comparable to that of the strong Transformer model. More importantly, we perform context retrieval from the training set for samples within each mini-batch during the training phase, utilizing both positively and negatively related samples to enhance feature representation and discriminative learning. Subsequently, we feed the vision tokens, context information, and prompt statements to invoke the LLM for generating high-quality medical reports. Extensive experiments on three X-ray report generation datasets (i.e., IU-Xray, MIMIC-CXR, CheXpert Plus) fully validated the effectiveness of our proposed model. The source code of this work will be released on url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Read more8/20/2024