R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation

0

Sign in to get full access
Overview
- Introduces R2GenCSR, a method for retrieving context samples to assist large language models in generating X-ray medical reports
- Focuses on improving the quality and accuracy of medical report generation by leveraging relevant contextual information
- Proposes a novel retrieval approach to identify and incorporate pertinent clinical samples into the language model's training and inference
Plain English Explanation
The paper presents a method called R2GenCSR (Retrieving Context Samples for [large language model based] X-ray Medical Report Generation) that aims to improve the quality and accuracy of medical report generation from X-ray images.
The key idea is to retrieve and leverage relevant [object Object] to assist the language model in generating more informative and clinically accurate reports. By identifying and incorporating pertinent [object Object], the method seeks to enhance the language model's understanding of the medical context and its ability to generate meaningful, [object Object].
The approach involves a novel retrieval mechanism that can efficiently identify the most relevant clinical samples from a large corpus to include in the training and inference of the language model. This helps the model [object Object] and generate more comprehensive and accurate reports, which can be valuable for [object Object].
Technical Explanation
The paper introduces the R2GenCSR (Retrieving Context Samples for [large language model based] X-ray Medical Report Generation) approach, which aims to enhance the quality and accuracy of medical report generation from X-ray images.
The proposed method involves a novel retrieval mechanism to identify and incorporate relevant [object Object] into the training and inference of the language model. The key idea is to leverage these pertinent clinical samples to [object Object] and its ability to generate [object Object].
The R2GenCSR approach consists of two main components:
-
Retrieval Model: This component is responsible for efficiently identifying the most relevant clinical samples from a large corpus to include in the language model's training and inference. The retrieval model leverages various [object Object] (e.g., textual, visual) to select the most pertinent samples.
-
Language Model: The language model, which is based on a [object Object], is fine-tuned on the retrieved clinical samples to enhance its understanding of the medical domain and its ability to generate accurate and comprehensive X-ray reports.
The authors conduct extensive experiments to evaluate the effectiveness of the R2GenCSR approach, comparing it to various baselines and state-of-the-art methods. The results demonstrate that the proposed method can significantly improve the quality and accuracy of the generated medical reports, highlighting the benefits of leveraging relevant contextual information to support large language models in the medical domain.
Critical Analysis
The paper presents a well-designed and promising approach to improving the quality of X-ray medical report generation using large language models. The key strengths of the R2GenCSR method include:
-
Leveraging Contextual Information: The ability to retrieve and incorporate relevant clinical samples into the language model's training and inference is a valuable contribution, as it can enhance the model's understanding of the medical domain and lead to more informative and accurate reports.
-
Efficient Retrieval Mechanism: The proposed retrieval model, which can efficiently identify the most pertinent clinical samples from a large corpus, is a crucial component that enables the effective integration of contextual information.
However, the paper also highlights some potential limitations and areas for further research:
-
Generalization to Other Medical Domains: The current focus is on X-ray medical reports, and it would be interesting to explore the applicability of the R2GenCSR approach to other medical imaging modalities or clinical tasks.
-
Interpretability and Explainability: The paper does not delve deeply into the interpretability or explainability of the retrieved clinical samples and how they influence the language model's decision-making process. Providing more insights into this aspect could further strengthen the understanding and trust in the generated reports.
-
Ethical Considerations: As with any AI system in the medical domain, there should be a thorough examination of potential biases, privacy concerns, and the responsible deployment of the R2GenCSR method to ensure its safe and ethical use in clinical settings.
Overall, the R2GenCSR approach presents a promising step towards improving the quality and accuracy of medical report generation using large language models, and the authors have identified several promising directions for future research and development.
Conclusion
The paper introduces the R2GenCSR (Retrieving Context Samples for [large language model based] X-ray Medical Report Generation) method, which aims to enhance the quality and accuracy of medical report generation from X-ray images. By leveraging a novel retrieval mechanism to identify and incorporate relevant clinical samples, the approach seeks to improve the language model's understanding of the medical domain and its ability to generate more informative and clinically accurate reports.
The authors demonstrate the effectiveness of the R2GenCSR method through extensive experiments, showcasing its potential to support clinicians and improve patient care. While the current focus is on X-ray medical reports, the principles and techniques underlying the R2GenCSR approach could be further explored and applied to other medical imaging modalities and clinical tasks, potentially making a significant impact on the field of medical report generation using large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
R2GenCSR: Retrieving Context Samples for Large Language Model based X-ray Medical Report Generation
Xiao Wang, Yuehang Li, Fuling Wang, Shiao Wang, Chuanfu Li, Bo Jiang
Inspired by the tremendous success of Large Language Models (LLMs), existing X-ray medical report generation methods attempt to leverage large models to achieve better performance. They usually adopt a Transformer to extract the visual features of a given X-ray image, and then, feed them into the LLM for text generation. How to extract more effective information for the LLMs to help them improve final results is an urgent problem that needs to be solved. Additionally, the use of visual Transformer models also brings high computational complexity. To address these issues, this paper proposes a novel context-guided efficient X-ray medical report generation framework. Specifically, we introduce the Mamba as the vision backbone with linear complexity, and the performance obtained is comparable to that of the strong Transformer model. More importantly, we perform context retrieval from the training set for samples within each mini-batch during the training phase, utilizing both positively and negatively related samples to enhance feature representation and discriminative learning. Subsequently, we feed the vision tokens, context information, and prompt statements to invoke the LLM for generating high-quality medical reports. Extensive experiments on three X-ray report generation datasets (i.e., IU-Xray, MIMIC-CXR, CheXpert Plus) fully validated the effectiveness of our proposed model. The source code of this work will be released on url{https://github.com/Event-AHU/Medical_Image_Analysis}.
Read more8/20/2024

0
Clinical Context-aware Radiology Report Generation from Medical Images using Transformers
Sonit Singh
Recent developments in the field of Natural Language Processing, especially language models such as the transformer have brought state-of-the-art results in language understanding and language generation. In this work, we investigate the use of the transformer model for radiology report generation from chest X-rays. We also highlight limitations in evaluating radiology report generation using only the standard language generation metrics. We then applied a transformer based radiology report generation architecture, and also compare the performance of a transformer based decoder with the recurrence based decoder. Experiments were performed using the IU-CXR dataset, showing superior results to its LSTM counterpart and being significantly faster. Finally, we identify the need of evaluating radiology report generation system using both language generation metrics and classification metrics, which helps to provide robust measure of generated reports in terms of their coherence and diagnostic value.
Read more8/22/2024
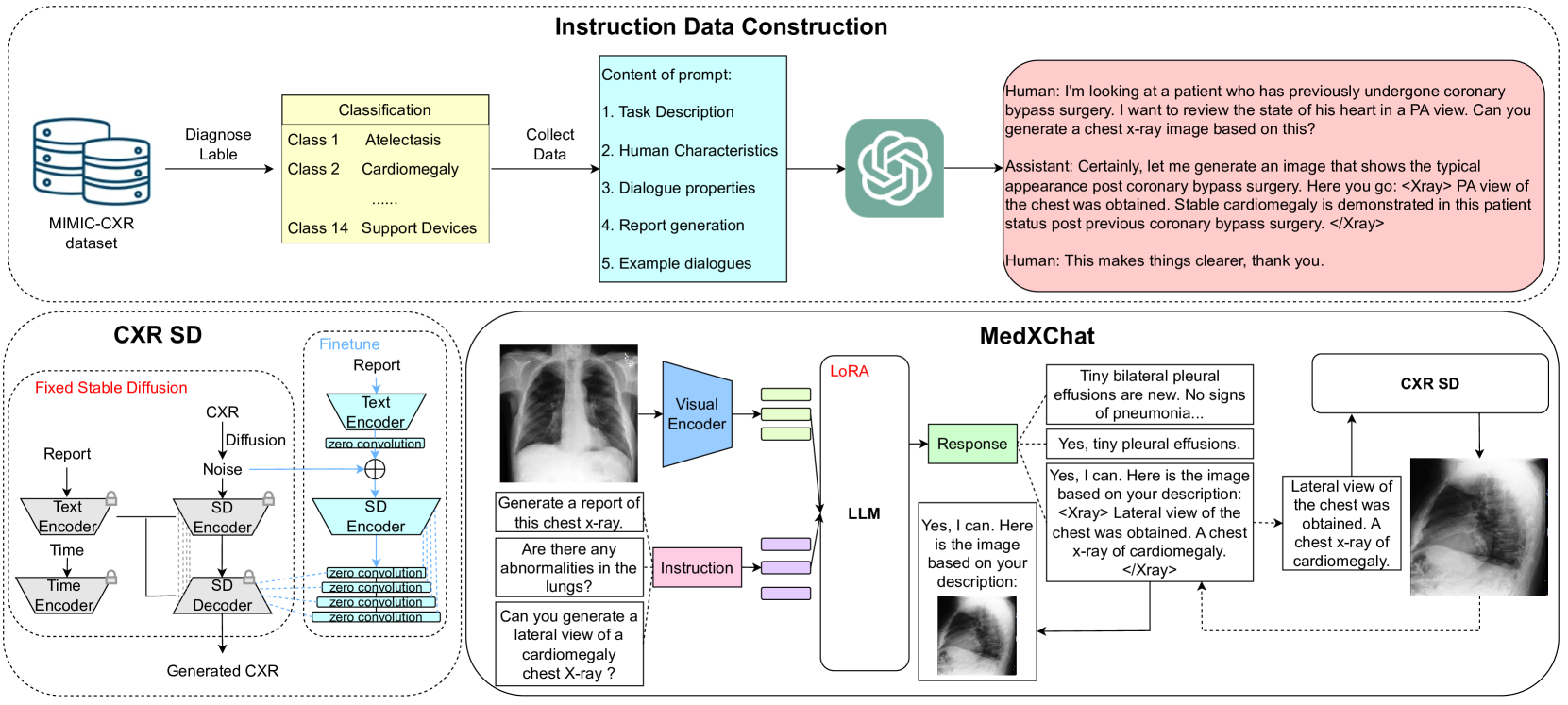
0
MedXChat: A Unified Multimodal Large Language Model Framework towards CXRs Understanding and Generation
Ling Yang, Zhanyu Wang, Zhenghao Chen, Xinyu Liang, Luping Zhou
Multimodal Large Language Models (MLLMs) have shown success in various general image processing tasks, yet their application in medical imaging is nascent, lacking tailored models. This study investigates the potential of MLLMs in improving the understanding and generation of Chest X-Rays (CXRs). We introduce MedXChat, a unified framework facilitating seamless interactions between medical assistants and users for diverse CXR tasks, including text report generation, visual question-answering (VQA), and Text-to-CXR generation. Our MLLMs using natural language as the input breaks task boundaries, maximally simplifying medical professional training by allowing diverse tasks within a single environment. For CXR understanding, we leverage powerful off-the-shelf visual encoders (e.g., ViT) and LLMs (e.g., mPLUG-Owl) to convert medical imagery into language-like features, and subsequently fine-tune our large pre-trained models for medical applications using a visual adapter network and a delta-tuning approach. For CXR generation, we introduce an innovative synthesis approach that utilizes instruction-following capabilities within the Stable Diffusion (SD) architecture. This technique integrates smoothly with the existing model framework, requiring no extra parameters, thereby maintaining the SD's generative strength while also bestowing upon it the capacity to render fine-grained medical images with high fidelity. Through comprehensive experiments, our model demonstrates exceptional cross-task adaptability, displaying adeptness across all three defined tasks. Our MedXChat model and the instruction dataset utilized in this research will be made publicly available to encourage further exploration in the field.
Read more5/13/2024

0
KARGEN: Knowledge-enhanced Automated Radiology Report Generation Using Large Language Models
Yingshu Li, Zhanyu Wang, Yunyi Liu, Lei Wang, Lingqiao Liu, Luping Zhou
Harnessing the robust capabilities of Large Language Models (LLMs) for narrative generation, logical reasoning, and common-sense knowledge integration, this study delves into utilizing LLMs to enhance automated radiology report generation (R2Gen). Despite the wealth of knowledge within LLMs, efficiently triggering relevant knowledge within these large models for specific tasks like R2Gen poses a critical research challenge. This paper presents KARGEN, a Knowledge-enhanced Automated radiology Report GENeration framework based on LLMs. Utilizing a frozen LLM to generate reports, the framework integrates a knowledge graph to unlock chest disease-related knowledge within the LLM to enhance the clinical utility of generated reports. This is achieved by leveraging the knowledge graph to distill disease-related features in a designed way. Since a radiology report encompasses both normal and disease-related findings, the extracted graph-enhanced disease-related features are integrated with regional image features, attending to both aspects. We explore two fusion methods to automatically prioritize and select the most relevant features. The fused features are employed by LLM to generate reports that are more sensitive to diseases and of improved quality. Our approach demonstrates promising results on the MIMIC-CXR and IU-Xray datasets.
Read more9/10/2024