The Unmet Promise of Synthetic Training Images: Using Retrieved Real Images Performs Better

0

Sign in to get full access
Overview
- This paper investigates the effectiveness of using synthetic training images versus real images for machine learning tasks.
- The authors find that using real images retrieved from the internet performs better than using synthetic training images, contrary to the common belief that synthetic data can improve model performance.
- The paper provides insights into the limitations of current synthetic data generation techniques and the importance of using high-quality, real-world data for effective machine learning.
Plain English Explanation
Machine learning models are often trained on large datasets of images, and researchers have explored using synthetic or computer-generated images as a way to augment these datasets and improve model performance. The idea is that synthetic images can provide a more diverse and controlled training set, allowing models to learn more robust features.
However, this paper challenges the assumption that synthetic images are always better. The authors show that when they use a technique to retrieve and transform real images from the internet, the resulting training data actually performs better than using synthetic images. This suggests that current synthetic data generation methods may not be capturing the full complexity and nuance of real-world data, and that using high-quality real images can be more effective for training powerful machine learning models.
The paper "Is Synthetic Image Useful for Transfer Learning Investigation?" and the paper "Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning for Improved Performance on Synthetic Data" have also explored the limitations of synthetic data, finding that it can struggle to match the performance of real-world data. This new paper adds to this growing body of research questioning the unmet promise of synthetic training data.
Technical Explanation
The paper begins by reviewing related work on the use of synthetic data for machine learning, noting the mixed results reported in the literature. The authors then describe their own experiment, where they train computer vision models on either synthetic images or real images retrieved and transformed from the internet.
For the synthetic data, the authors use a state-of-the-art image generation technique called StyleGAN2. For the real data, they use an image retrieval and transformation pipeline to find and augment relevant images from a large online database.
The authors evaluate the performance of the models trained on these two datasets on several standard computer vision benchmarks. Contrary to their expectations, they find that the models trained on the retrieved and transformed real images consistently outperform those trained on the synthetic data.
The authors hypothesize that current synthetic data generation methods, while impressive, still struggle to capture the full complexity and diversity of real-world data. The retrieved real images, even with some transformations, may provide a richer training signal that allows the models to learn more generalizable features.
Critical Analysis
The paper provides a valuable contribution by empirically demonstrating the limitations of synthetic training data, even when using state-of-the-art generation techniques. This challenges the common assumption that synthetic data is a panacea for data-hungry machine learning models.
However, the authors acknowledge that their findings are specific to the particular computer vision tasks and datasets they evaluated. It's possible that synthetic data could be more beneficial in other domains or with different model architectures and training regimes.
Additionally, the authors' image retrieval and transformation pipeline is not described in detail, so it's difficult to assess how generalizable or scalable that approach might be. There may be practical limitations or biases introduced by that process that are not fully explored.
Further research is needed to better understand the tradeoffs between synthetic and real-world training data, and to develop more sophisticated techniques for generating high-quality synthetic data that can truly complement or even surpass the performance of real images. As highlighted in the paper "Is Synthetic Data All We Need? Benchmarking and Analyzing Generalization Gaps", there are still significant gaps between synthetic and real-world data that need to be addressed.
Conclusion
This paper presents an insightful challenge to the prevailing narrative around the benefits of synthetic training data for machine learning. By showing that retrieved and transformed real images can outperform state-of-the-art synthetic data, the authors raise important questions about the limitations of current synthetic data generation techniques.
The findings suggest that while synthetic data may have a role to play, especially in data-scarce domains, relying solely on synthetic images may not be a silver bullet for improving model performance. Careful curation and use of high-quality real-world data remain critical for building robust and effective machine learning systems.
As the field of artificial intelligence continues to advance, it will be important for researchers and practitioners to rigorously evaluate the tradeoffs between synthetic and real-world data, and to develop new techniques that can truly bridge the gap between the two. This paper represents an important step in that direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Unmet Promise of Synthetic Training Images: Using Retrieved Real Images Performs Better
Scott Geng, Cheng-Yu Hsieh, Vivek Ramanujan, Matthew Wallingford, Chun-Liang Li, Pang Wei Koh, Ranjay Krishna
Generative text-to-image models enable us to synthesize unlimited amounts of images in a controllable manner, spurring many recent efforts to train vision models with synthetic data. However, every synthetic image ultimately originates from the upstream data used to train the generator. What additional value does the intermediate generator provide over directly training on relevant parts of the upstream data? Grounding this question in the setting of image classification,a we compare finetuning on task-relevant, targeted synthetic data generated by Stable Diffusion -- a generative model trained on the LAION-2B dataset -- against finetuning on targeted real images retrieved directly from LAION-2B. We show that while synthetic data can benefit some downstream tasks, it is universally matched or outperformed by real data from our simple retrieval baseline. Our analysis suggests that this underperformance is partially due to generator artifacts and inaccurate task-relevant visual details in the synthetic images. Overall, we argue that retrieval is a critical baseline to consider when training with synthetic data -- a baseline that current methods do not yet surpass. We release code, data, and models at https://github.com/scottgeng00/unmet-promise.
Read more7/4/2024
0
Is Synthetic Image Useful for Transfer Learning? An Investigation into Data Generation, Volume, and Utilization
Yuhang Li, Xin Dong, Chen Chen, Jingtao Li, Yuxin Wen, Michael Spranger, Lingjuan Lyu
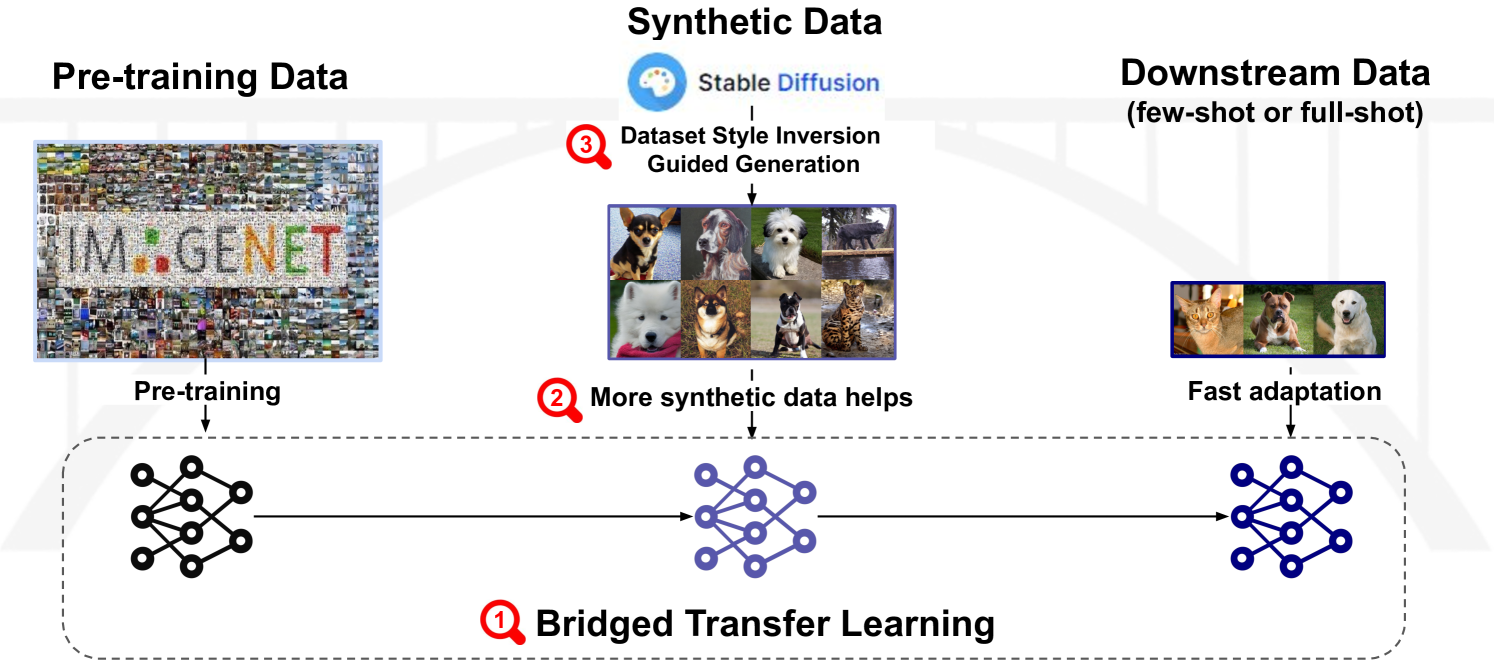
Synthetic image data generation represents a promising avenue for training deep learning models, particularly in the realm of transfer learning, where obtaining real images within a specific domain can be prohibitively expensive due to privacy and intellectual property considerations. This work delves into the generation and utilization of synthetic images derived from text-to-image generative models in facilitating transfer learning paradigms. Despite the high visual fidelity of the generated images, we observe that their naive incorporation into existing real-image datasets does not consistently enhance model performance due to the inherent distribution gap between synthetic and real images. To address this issue, we introduce a novel two-stage framework called bridged transfer, which initially employs synthetic images for fine-tuning a pre-trained model to improve its transferability and subsequently uses real data for rapid adaptation. Alongside, We propose dataset style inversion strategy to improve the stylistic alignment between synthetic and real images. Our proposed methods are evaluated across 10 different datasets and 5 distinct models, demonstrating consistent improvements, with up to 30% accuracy increase on classification tasks. Intriguingly, we note that the enhancements were not yet saturated, indicating that the benefits may further increase with an expanded volume of synthetic data.
Read more4/4/2024
🔄
0
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
Leonhard Hennicke, Christian Medeiros Adriano, Holger Giese, Jan Mathias Koehler, Lukas Schott
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
Read more5/7/2024

0
Detect Fake with Fake: Leveraging Synthetic Data-driven Representation for Synthetic Image Detection
Hina Otake, Yoshihiro Fukuhara, Yoshiki Kubotani, Shigeo Morishima
Are general-purpose visual representations acquired solely from synthetic data useful for detecting fake images? In this work, we show the effectiveness of synthetic data-driven representations for synthetic image detection. Upon analysis, we find that vision transformers trained by the latest visual representation learners with synthetic data can effectively distinguish fake from real images without seeing any real images during pre-training. Notably, using SynCLR as the backbone in a state-of-the-art detection method demonstrates a performance improvement of +10.32 mAP and +4.73% accuracy over the widely used CLIP, when tested on previously unseen GAN models. Code is available at https://github.com/cvpaperchallenge/detect-fake-with-fake.
Read more9/16/2024