Unlearning Traces the Influential Training Data of Language Models

2

Sign in to get full access
Overview
- This paper explores a novel technique called "unlearning" to reveal the influential training data of large language models.
- The researchers propose a method to systematically remove specific training examples from a model, allowing them to identify the most influential data points that shape the model's behavior.
- The findings provide valuable insights into the inner workings of these complex models and have implications for model transparency, fairness, and accountability.
Plain English Explanation
The researchers in this paper looked at a new way to understand how large language models, like those used in chatbots and virtual assistants, are influenced by the data they are trained on. Rethinking Machine Unlearning in Large Language Models and Machine Unlearning for Large Language Models are related papers that explore similar concepts.
Rather than just looking at the final model, the researchers developed a technique called "unlearning" that allows them to systematically remove specific examples from the training data. This helps them identify which training examples had the biggest impact on shaping the model's behavior and outputs.
By selectively "unlearning" parts of the training data, the researchers can peek under the hood of these complex language models and better understand what influences their decisions. This could lead to more transparent and accountable AI systems, as well as help address issues of fairness and bias. Class-Based Machine Unlearning for Complex Data via Concepts and Adversarial Machine Unlearning explore related techniques for "unlearning" in machine learning models.
The findings from this research provide valuable insights into the inner workings of language models and have implications for improving the transparency, fairness, and accountability of these powerful AI systems. Data Attribution for Text-to-Image Models by is another relevant paper that looks at understanding the influence of training data on AI models.
Technical Explanation
The researchers propose a novel "unlearning" technique to systematically remove specific training examples from large language models. By selectively "unforgeetting" parts of the model's training data, they can identify the most influential data points that shape the model's behavior and outputs.
The key steps of their approach are:
- Training a Base Model: The researchers start by training a large language model on a standard dataset, such as Wikipedia or Common Crawl.
- Unlearning Individual Examples: They then systematically remove individual training examples from the model, one at a time, and measure the change in the model's performance. Examples that result in the largest performance changes are considered the most influential.
- Analyzing Influential Examples: By examining the characteristics of the most influential training examples, the researchers can gain insights into what types of data have the greatest impact on the model's learned representations and outputs.
The researchers demonstrate their unlearning approach on several large language models, including GPT-2 and GPT-3. Their findings reveal that the models are heavily influenced by a relatively small subset of the training data, with certain types of examples (e.g., longer, more complex sentences) having a disproportionate impact.
This technique provides a powerful tool for opening up the "black box" of large language models and understanding their inner workings. The insights gleaned from unlearning can inform efforts to improve model transparency, fairness, and accountability.
Critical Analysis
The unlearning approach presented in this paper is a promising step towards greater transparency in large language models. By systematically removing training examples, the researchers are able to identify the most influential data points that shape the models' behaviors and outputs.
However, one potential limitation of the unlearning approach is that it may not capture more complex or indirect ways in which the training data influences the model. The removal of individual examples may not fully account for the cumulative or interactive effects of the training data.
Additionally, the unlearning process can be computationally intensive, as it requires retraining the model for each example removed. This could limit the scalability of the approach, especially for the largest language models.
Future research could explore more efficient or targeted unlearning techniques, as well as investigate the unlearning of entire subsets of the training data (e.g., by topic or source) rather than individual examples. Adversarial Machine Unlearning and Class-Based Machine Unlearning for Complex Data via Concepts discuss related approaches for "unlearning" in machine learning models.
Overall, the unlearning technique presented in this paper represents an important step towards greater transparency and accountability in large language models. The insights gained from this research can help inform the development of more responsible and trustworthy AI systems.
Conclusion
This paper introduces a novel "unlearning" technique that allows researchers to systematically remove specific training examples from large language models. By selectively "unforgeetting" parts of the training data, the researchers can identify the most influential data points that shape the models' behaviors and outputs.
The findings from this research provide valuable insights into the inner workings of complex language models, which can inform efforts to improve their transparency, fairness, and accountability. The unlearning approach offers a powerful tool for opening up the "black box" of these AI systems and understanding the factors that drive their decision-making.
While the unlearning process has some limitations, such as computational intensity and potential to miss more complex data influences, the insights gained from this research are an important step towards developing more responsible and trustworthy AI systems. Further research in this area, as seen in Rethinking Machine Unlearning in Large Language Models, Machine Unlearning for Large Language Models, and Data Attribution for Text-to-Image Models by, will continue to shed light on the complex relationship between training data and model behavior.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
2
Unlearning Traces the Influential Training Data of Language Models
Masaru Isonuma, Ivan Titov
Identifying the training datasets that influence a language model's outputs is essential for minimizing the generation of harmful content and enhancing its performance. Ideally, we can measure the influence of each dataset by removing it from training; however, it is prohibitively expensive to retrain a model multiple times. This paper presents UnTrac: unlearning traces the influence of a training dataset on the model's performance. UnTrac is extremely simple; each training dataset is unlearned by gradient ascent, and we evaluate how much the model's predictions change after unlearning. Furthermore, we propose a more scalable approach, UnTrac-Inv, which unlearns a test dataset and evaluates the unlearned model on training datasets. UnTrac-Inv resembles UnTrac, while being efficient for massive training datasets. In the experiments, we examine if our methods can assess the influence of pretraining datasets on generating toxic, biased, and untruthful content. Our methods estimate their influence much more accurately than existing methods while requiring neither excessive memory space nor multiple checkpoints.
Read more6/14/2024

0
Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Read more7/16/2024

0
Learn while Unlearn: An Iterative Unlearning Framework for Generative Language Models
Haoyu Tang, Ye Liu, Xukai Liu, Kai Zhang, Yanghai Zhang, Qi Liu, Enhong Chen
Recent advancements in machine learning, especially in Natural Language Processing (NLP), have led to the development of sophisticated models trained on vast datasets, but this progress has raised concerns about potential sensitive information leakage. In response, regulatory measures like the EU General Data Protection Regulation (GDPR) have driven the exploration of Machine Unlearning techniques, which aim to enable models to selectively forget certain data entries. While early approaches focused on pre-processing methods, recent research has shifted towards training-based machine unlearning methods. However, many existing methods require access to original training data, posing challenges in scenarios where such data is unavailable. Besides, directly facilitating unlearning may undermine the language model's general expressive ability. To this end, in this paper, we introduce the Iterative Contrastive Unlearning (ICU) framework, which addresses these challenges by incorporating three key components. We propose a Knowledge Unlearning Induction module for unlearning specific target sequences and a Contrastive Learning Enhancement module to prevent degrading in generation capacity. Additionally, an Iterative Unlearning Refinement module is integrated to make the process more adaptive to each target sample respectively. Experimental results demonstrate the efficacy of ICU in maintaining performance while efficiently unlearning sensitive information, offering a promising avenue for privacy-conscious machine learning applications.
Read more7/31/2024
0
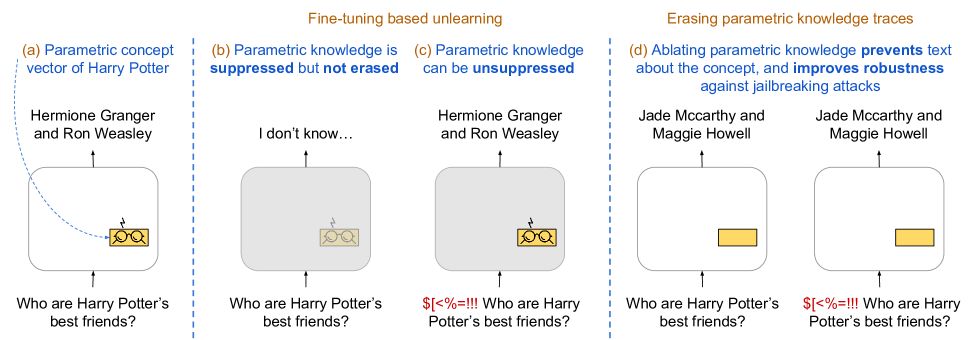
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Yihuai Hong, Lei Yu, Shauli Ravfogel, Haiqin Yang, Mor Geva
The task of unlearning certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed concept vectors) that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.
Read more6/18/2024