Data-Driven Preference Sampling for Pareto Front Learning

0

Sign in to get full access
Overview
- This paper presents a new approach for learning the Pareto front in multi-objective optimization problems, called Data-Driven Preference Sampling (DDPS).
- DDPS leverages a Dirichlet distribution to model user preferences and efficiently sample candidate solutions along the Pareto front.
- The authors demonstrate DDPS outperforms existing preference-based Pareto front learning methods on several benchmark problems.
Plain English Explanation
The paper describes a new technique called Data-Driven Preference Sampling (DDPS) for learning the Pareto front in multi-objective optimization problems. The Pareto front represents the set of optimal trade-offs between the different objectives.
DDPS works by using a Dirichlet distribution to model the user's preferences over the objectives. This allows the algorithm to efficiently sample candidate solutions that are likely to be on the Pareto front, based on the user's preferences.
The authors show that DDPS outperforms existing preference-based Pareto front learning methods on several benchmark problems. This suggests DDPS could be a useful tool for solving real-world multi-objective optimization problems, where efficiently exploring the Pareto front is crucial.
Technical Explanation
The paper introduces a new method called Data-Driven Preference Sampling (DDPS) for learning the Pareto front in multi-objective optimization problems. The key idea is to leverage a Dirichlet distribution to model the user's preferences over the objectives, and then use this model to efficiently sample candidate solutions along the Pareto front.
Specifically, the authors first assume the user's preferences can be represented by a Dirichlet distribution over the objective function weights. They then devise a sampling strategy that generates candidate solutions by drawing weight vectors from this Dirichlet distribution, evaluating the corresponding objective function values, and selecting the non-dominated solutions.
The authors evaluate DDPS on several benchmark multi-objective optimization problems and compare it to existing preference-based Pareto front learning methods, such as preference-based Gaussian processes and causal graph-based sampling. The results show that DDPS outperforms these baselines in terms of both convergence speed and final Pareto front approximation quality.
Critical Analysis
The paper presents a novel and promising approach for Pareto front learning, but there are a few potential limitations and areas for further research:
-
The proposed DDPS method relies on the assumption that the user's preferences can be accurately modeled by a Dirichlet distribution. In practice, this assumption may not always hold, and more flexible preference models may be needed.
-
The authors only evaluate DDPS on relatively low-dimensional problems (up to 5 objectives). It would be interesting to see how the method scales to higher-dimensional multi-objective optimization problems, which are more common in real-world applications.
-
The paper does not address the issue of how to incorporate additional problem-specific constraints or preferences beyond the objective functions. Extending DDPS to handle such constraints could further improve its practical applicability.
-
While the authors demonstrate the superiority of DDPS over existing preference-based Pareto front learning methods, it would be valuable to also compare it to other state-of-the-art multi-objective optimization algorithms that do not rely on user preferences, such as evolutionary algorithms or manifold learning approaches.
Overall, the paper presents a promising new technique for Pareto front learning and highlights the potential benefits of incorporating user preferences into the optimization process. Further research and empirical evaluation could help address the identified limitations and solidify the advantages of the DDPS approach.
Conclusion
This paper introduces a new method called Data-Driven Preference Sampling (DDPS) for learning the Pareto front in multi-objective optimization problems. DDPS leverages a Dirichlet distribution to model the user's preferences over the objectives, and then uses this model to efficiently sample candidate solutions along the Pareto front.
The authors demonstrate that DDPS outperforms existing preference-based Pareto front learning methods on several benchmark problems, suggesting it could be a valuable tool for solving real-world multi-objective optimization challenges. While the paper identifies a few potential limitations, the DDPS approach represents an important step forward in incorporating user preferences into the Pareto front learning process.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data-Driven Preference Sampling for Pareto Front Learning
Rongguang Ye, Lei Chen, Weiduo Liao, Jinyuan Zhang, Hisao Ishibuchi
Pareto front learning is a technique that introduces preference vectors in a neural network to approximate the Pareto front. Previous Pareto front learning methods have demonstrated high performance in approximating simple Pareto fronts. These methods often sample preference vectors from a fixed Dirichlet distribution. However, no fixed sampling distribution can be adapted to diverse Pareto fronts. Efficiently sampling preference vectors and accurately estimating the Pareto front is a challenge. To address this challenge, we propose a data-driven preference vector sampling framework for Pareto front learning. We utilize the posterior information of the objective functions to adjust the parameters of the sampling distribution flexibly. In this manner, the proposed method can sample preference vectors from the location of the Pareto front with a high probability. Moreover, we design the distribution of the preference vector as a mixture of Dirichlet distributions to improve the performance of the model in disconnected Pareto fronts. Extensive experiments validate the superiority of the proposed method compared with state-of-the-art algorithms.
Read more4/15/2024

0
Evolutionary Preference Sampling for Pareto Set Learning
Rongguang Ye, Longcan Chen, Jinyuan Zhang, Hisao Ishibuchi
Recently, Pareto Set Learning (PSL) has been proposed for learning the entire Pareto set using a neural network. PSL employs preference vectors to scalarize multiple objectives, facilitating the learning of mappings from preference vectors to specific Pareto optimal solutions. Previous PSL methods have shown their effectiveness in solving artificial multi-objective optimization problems (MOPs) with uniform preference vector sampling. The quality of the learned Pareto set is influenced by the sampling strategy of the preference vector, and the sampling of the preference vector needs to be decided based on the Pareto front shape. However, a fixed preference sampling strategy cannot simultaneously adapt the Pareto front of multiple MOPs. To address this limitation, this paper proposes an Evolutionary Preference Sampling (EPS) strategy to efficiently sample preference vectors. Inspired by evolutionary algorithms, we consider preference sampling as an evolutionary process to generate preference vectors for neural network training. We integrate the EPS strategy into five advanced PSL methods. Extensive experiments demonstrate that our proposed method has a faster convergence speed than baseline algorithms on 7 testing problems. Our implementation is available at https://github.com/rG223/EPS.
Read more4/15/2024
0
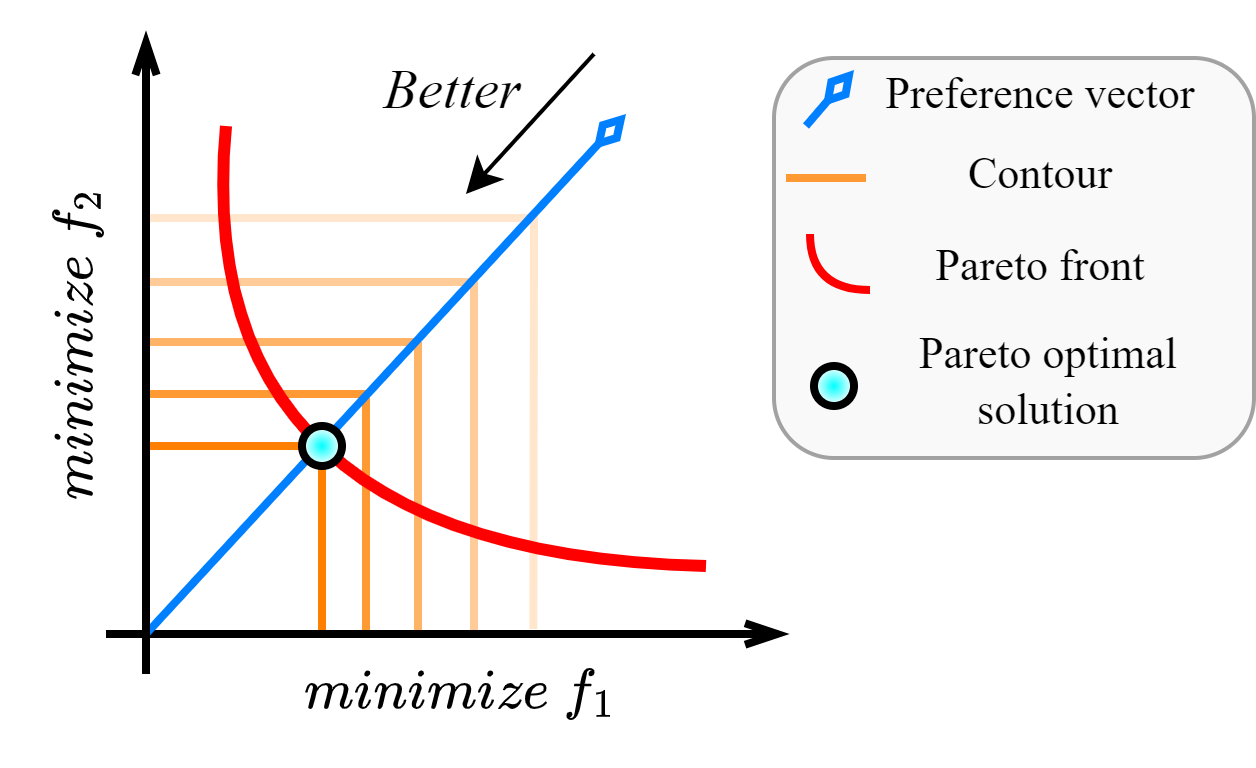
Pareto Front Shape-Agnostic Pareto Set Learning in Multi-Objective Optimization
Rongguang Ye, Longcan Chen, Wei-Bin Kou, Jinyuan Zhang, Hisao Ishibuchi
Pareto set learning (PSL) is an emerging approach for acquiring the complete Pareto set of a multi-objective optimization problem. Existing methods primarily rely on the mapping of preference vectors in the objective space to Pareto optimal solutions in the decision space. However, the sampling of preference vectors theoretically requires prior knowledge of the Pareto front shape to ensure high performance of the PSL methods. Designing a sampling strategy of preference vectors is difficult since the Pareto front shape cannot be known in advance. To make Pareto set learning work effectively in any Pareto front shape, we propose a Pareto front shape-agnostic Pareto Set Learning (GPSL) that does not require the prior information about the Pareto front. The fundamental concept behind GPSL is to treat the learning of the Pareto set as a distribution transformation problem. Specifically, GPSL can transform an arbitrary distribution into the Pareto set distribution. We demonstrate that training a neural network by maximizing hypervolume enables the process of distribution transformation. Our proposed method can handle any shape of the Pareto front and learn the Pareto set without requiring prior knowledge. Experimental results show the high performance of our proposed method on diverse test problems compared with recent Pareto set learning algorithms.
Read more8/13/2024
0
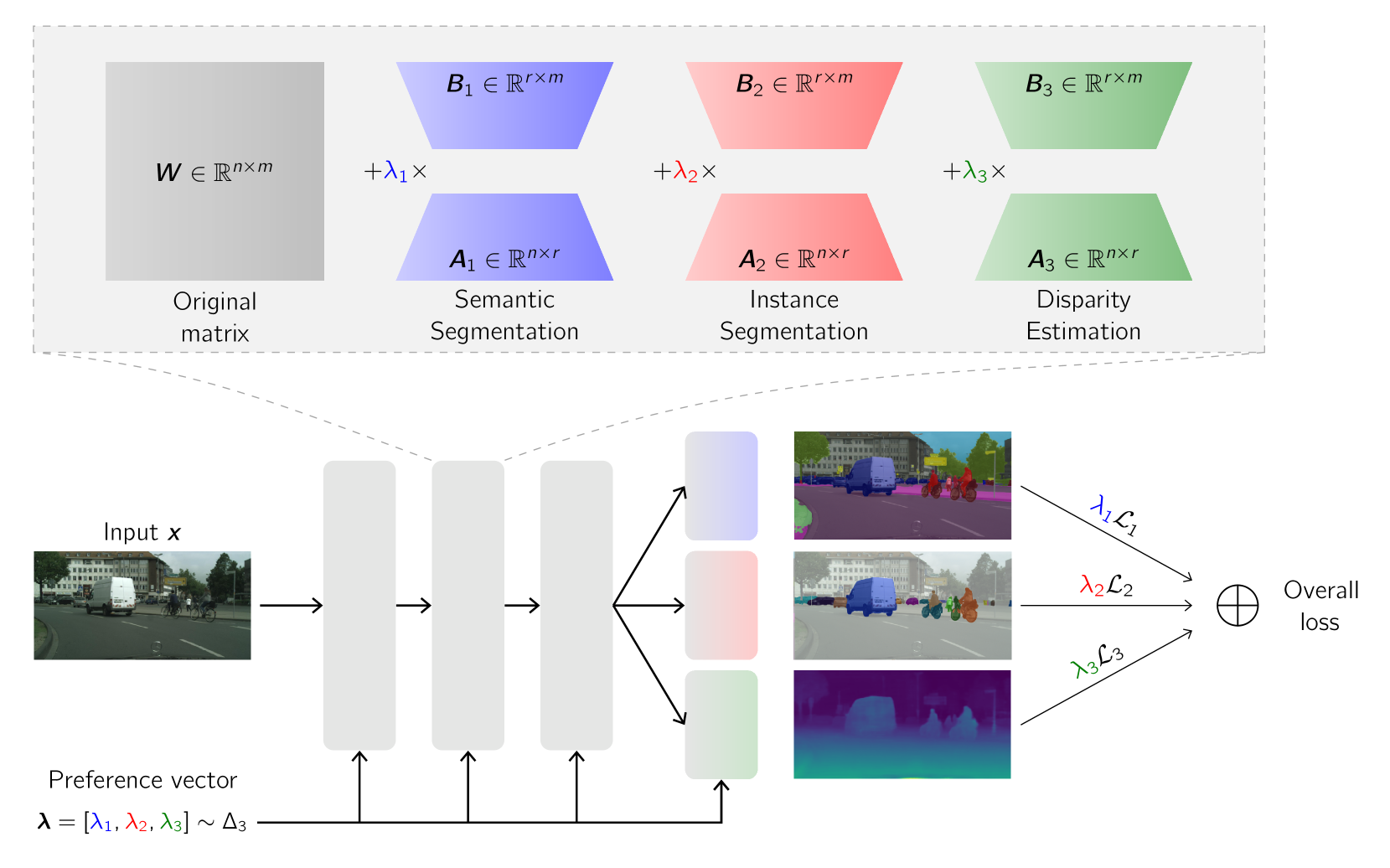
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Nikolaos Dimitriadis, Pascal Frossard, Francois Fleuret
Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
Read more7/12/2024