Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences

0
Sign in to get full access
Overview
- This paper introduces Pareto Low-Rank Adapters (PORA), a novel approach for efficient multi-task learning with preferences.
- PORA learns a low-rank adapter module that can be efficiently combined with a shared backbone model to perform well on multiple tasks.
- The paper also proposes Pareto-Optimal Preference Learning (POPL), a method for learning the user's task preferences in a principled way.
Plain English Explanation
Pareto Low-Rank Adapters (PORA) is a new technique that allows machine learning models to perform well on multiple different tasks, while also taking into account the user's preferences for those tasks.
Typically, when training a machine learning model to do multiple tasks, the model has to balance the various objectives, which can lead to suboptimal performance on any one task. PORA solves this by learning a small "adapter" module that can be efficiently combined with a shared backbone model. This adapter module is designed to be low-rank, meaning it has a compact representation, which makes it efficient to train and use.
The paper also introduces Pareto-Optimal Preference Learning (POPL), a way to learn the user's preferences for the different tasks in a principled way. This allows the model to focus on the tasks the user cares about the most, rather than trying to be equally good at everything.
Imagine you have a model that can do three different tasks: playing chess, solving math problems, and writing short stories. With PORA, you could train a single shared backbone model, and then learn small adapter modules for each task. The user could then specify their preferences, e.g., they care most about chess, then math, then writing. The model would then focus on performing well on chess and math, while still maintaining some competence in writing.
Technical Explanation
Pareto Low-Rank Adapters (PORA) is a novel approach for efficient multi-task learning that leverages low-rank adapter modules. The key idea is to learn a shared backbone model along with a set of low-rank adapters, one for each task. These adapters can be efficiently combined with the backbone model to perform well on multiple tasks.
The paper also introduces Pareto-Optimal Preference Learning (POPL), a method for learning the user's task preferences in a principled way. POPL formulates the preference learning problem as a multi-objective optimization problem, where the objective is to find the Pareto-optimal set of task weights that best match the user's preferences.
The authors evaluate PORA on a range of multi-task learning benchmarks, including MELORA, INFLORA, and BATCHED-LORA. The results demonstrate that PORA can achieve strong performance on multiple tasks while being efficient in terms of parameters and computation.
Critical Analysis
The paper presents a well-designed and principled approach to multi-task learning with preferences. The use of low-rank adapters is a clever way to balance task-specific performance and model efficiency, and the POPL method for learning user preferences is a novel contribution.
However, the paper does not extensively explore the limitations of the PORA approach. For example, it is not clear how well PORA would scale to a large number of tasks, or how sensitive the performance is to the choice of hyperparameters, such as the rank of the adapter modules.
Additionally, the paper does not discuss the potential ethical implications of a system that can efficiently optimize for user preferences. There could be concerns around the prioritization of certain tasks over others, and how this might impact fairness and representation.
Overall, the paper presents a promising approach to multi-task learning, but further research is needed to fully understand the strengths, weaknesses, and potential societal impacts of the PORA and POPL methods.
Conclusion
Pareto Low-Rank Adapters (PORA) is a novel technique for efficient multi-task learning that learns low-rank adapter modules to be combined with a shared backbone model. The paper also introduces Pareto-Optimal Preference Learning (POPL), a principled method for learning user preferences across tasks.
The PORA approach demonstrates strong performance on a range of multi-task learning benchmarks, while being efficient in terms of parameters and computation. This could have important implications for the development of more versatile and resource-friendly machine learning models.
However, the paper does not fully address the potential limitations and ethical considerations of the PORA and POPL methods. Further research is needed to understand the scalability, robustness, and societal impact of this approach to multi-task learning with preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Nikolaos Dimitriadis, Pascal Frossard, Francois Fleuret
Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
Read more7/12/2024

0
Efficient Pareto Manifold Learning with Low-Rank Structure
Weiyu Chen, James T. Kwok
Multi-task learning, which optimizes performance across multiple tasks, is inherently a multi-objective optimization problem. Various algorithms are developed to provide discrete trade-off solutions on the Pareto front. Recently, continuous Pareto front approximations using a linear combination of base networks have emerged as a compelling strategy. However, it suffers from scalability issues when the number of tasks is large. To address this issue, we propose a novel approach that integrates a main network with several low-rank matrices to efficiently learn the Pareto manifold. It significantly reduces the number of parameters and facilitates the extraction of shared features. We also introduce orthogonal regularization to further bolster performance. Extensive experimental results demonstrate that the proposed approach outperforms state-of-the-art baselines, especially on datasets with a large number of tasks.
Read more7/31/2024
0
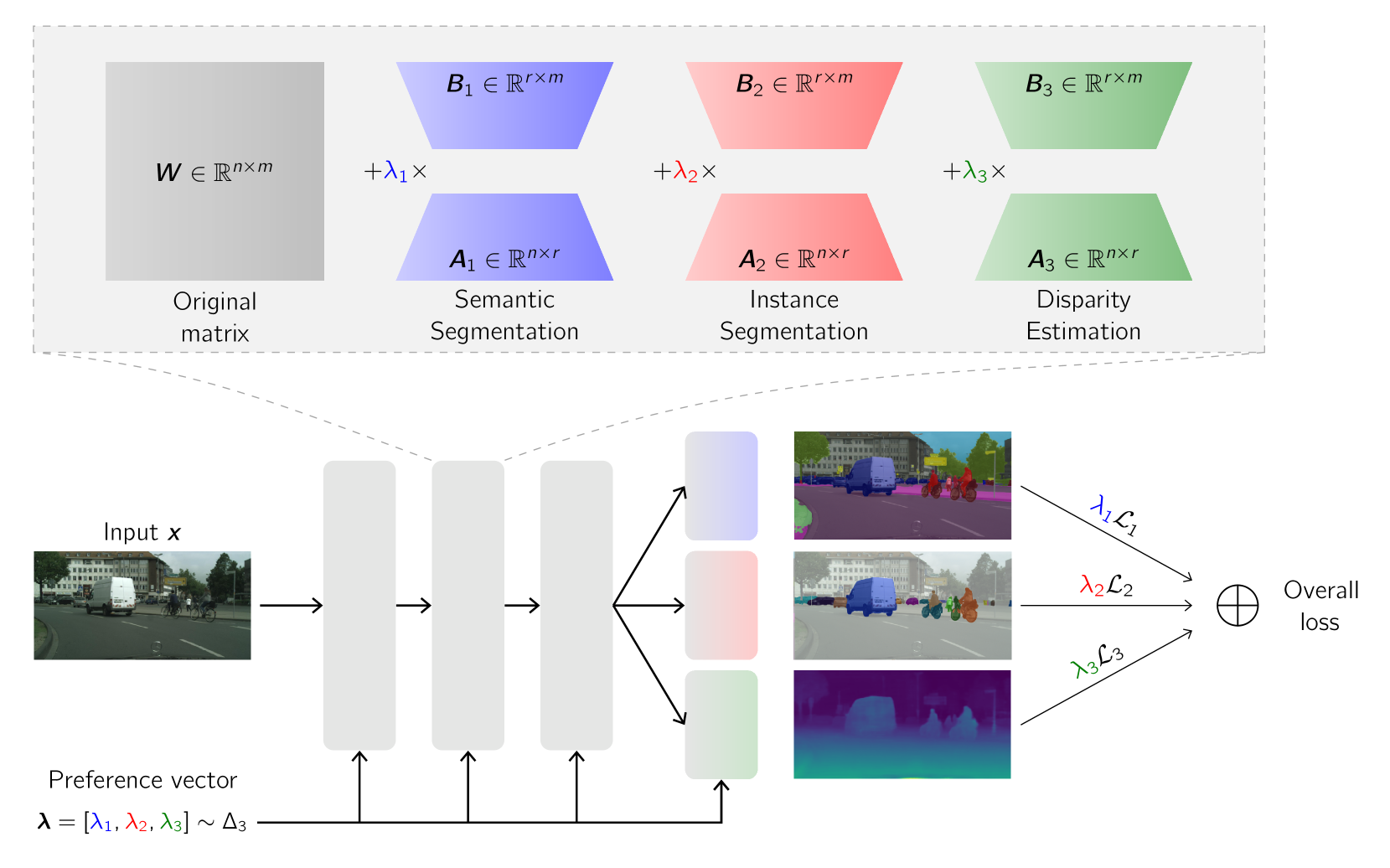
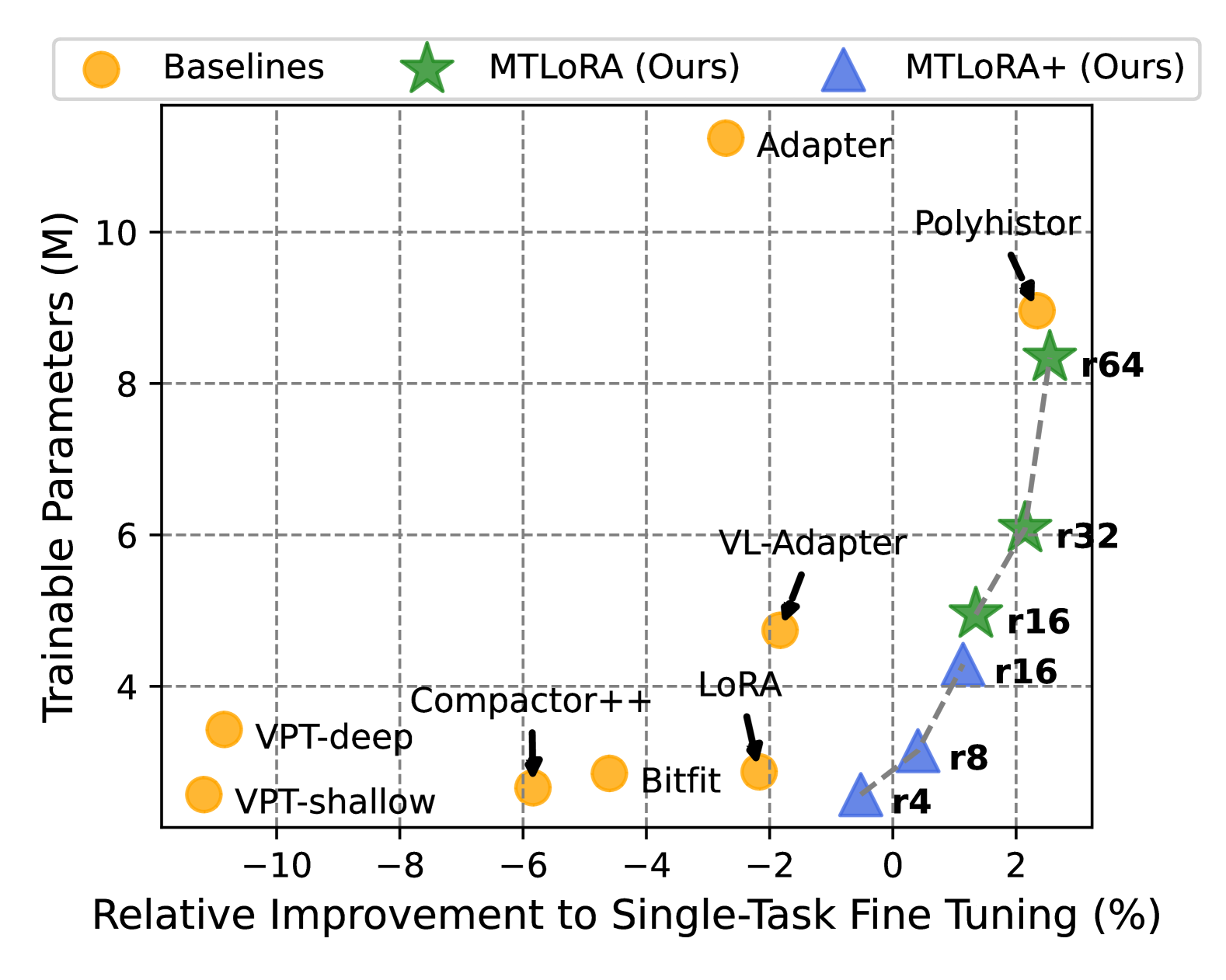
MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning
Ahmed Agiza, Marina Neseem, Sherief Reda
Adapting models pre-trained on large-scale datasets to a variety of downstream tasks is a common strategy in deep learning. Consequently, parameter-efficient fine-tuning methods have emerged as a promising way to adapt pre-trained models to different tasks while training only a minimal number of parameters. While most of these methods are designed for single-task adaptation, parameter-efficient training in Multi-Task Learning (MTL) architectures is still unexplored. In this paper, we introduce MTLoRA, a novel framework for parameter-efficient training of MTL models. MTLoRA employs Task-Agnostic and Task-Specific Low-Rank Adaptation modules, which effectively disentangle the parameter space in MTL fine-tuning, thereby enabling the model to adeptly handle both task specialization and interaction within MTL contexts. We applied MTLoRA to hierarchical-transformer-based MTL architectures, adapting them to multiple downstream dense prediction tasks. Our extensive experiments on the PASCAL dataset show that MTLoRA achieves higher accuracy on downstream tasks compared to fully fine-tuning the MTL model while reducing the number of trainable parameters by 3.6x. Furthermore, MTLoRA establishes a Pareto-optimal trade-off between the number of trainable parameters and the accuracy of the downstream tasks, outperforming current state-of-the-art parameter-efficient training methods in both accuracy and efficiency. Our code is publicly available.
Read more4/1/2024

0
MELoRA: Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning
Pengjie Ren, Chengshun Shi, Shiguang Wu, Mengqi Zhang, Zhaochun Ren, Maarten de Rijke, Zhumin Chen, Jiahuan Pei
Parameter-efficient fine-tuning (PEFT) is a popular method for tailoring pre-trained large language models (LLMs), especially as the models' scale and the diversity of tasks increase. Low-rank adaptation (LoRA) is based on the idea that the adaptation process is intrinsically low-dimensional, i.e., significant model changes can be represented with relatively few parameters. However, decreasing the rank encounters challenges with generalization errors for specific tasks when compared to full-parameter fine-tuning. We present MELoRA, a mini-ensemble low-rank adapters that uses fewer trainable parameters while maintaining a higher rank, thereby offering improved performance potential. The core idea is to freeze original pretrained weights and train a group of mini LoRAs with only a small number of parameters. This can capture a significant degree of diversity among mini LoRAs, thus promoting better generalization ability. We conduct a theoretical analysis and empirical studies on various NLP tasks. Our experimental results show that, compared to LoRA, MELoRA achieves better performance with 8 times fewer trainable parameters on natural language understanding tasks and 36 times fewer trainable parameters on instruction following tasks, which demonstrates the effectiveness of MELoRA.
Read more6/26/2024