DataComp-LM: In search of the next generation of training sets for language models
2406.11794
2
0
Abstract
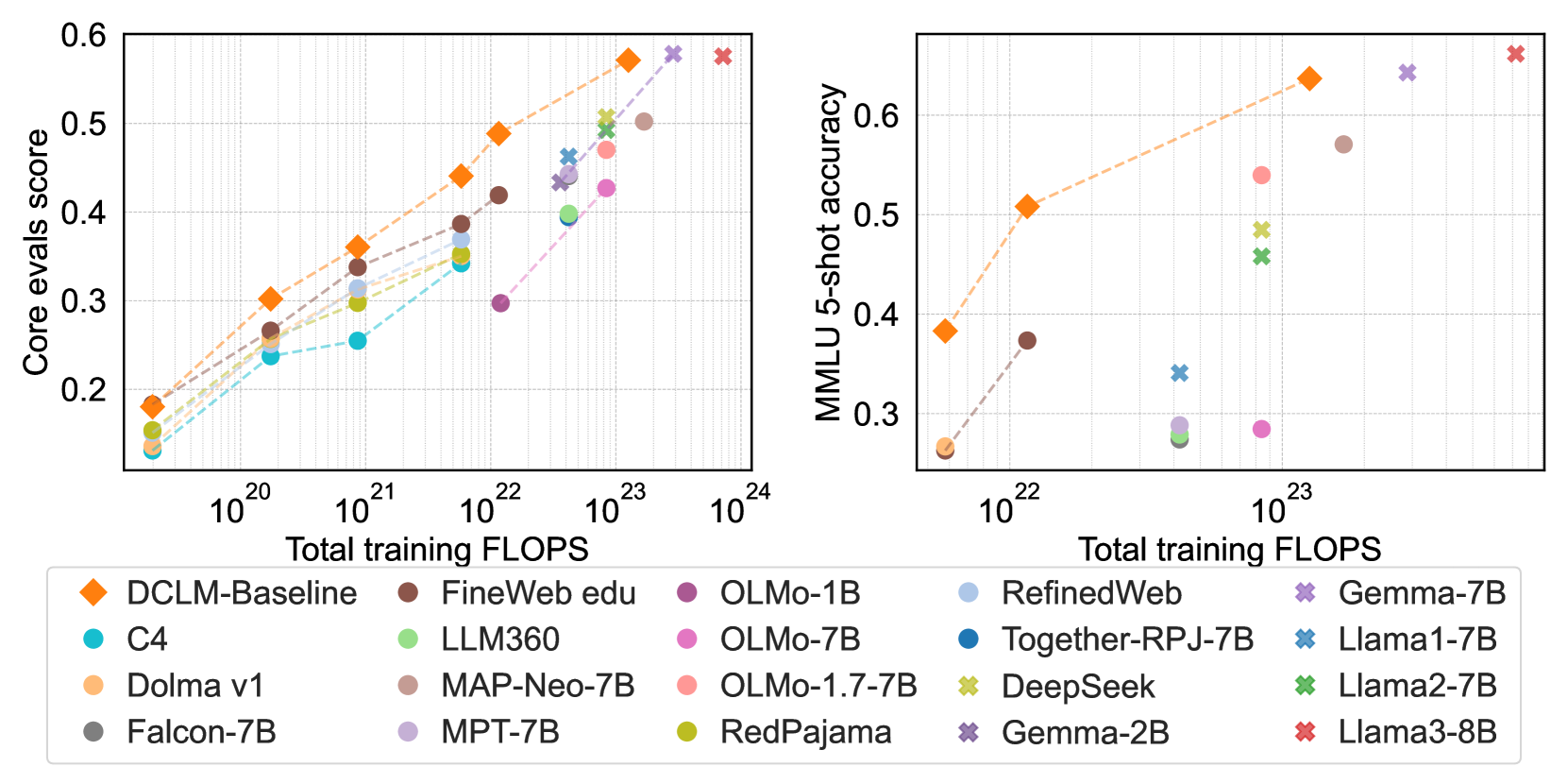
We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
Create account to get full access
Overview
- Examines the need for new, high-quality training datasets for language models
- Introduces DataComp-LM, a framework for developing and evaluating such datasets
- Highlights the importance of dataset composition and quality in advancing language model capabilities
Plain English Explanation
This paper explores the challenge of finding the right training data to build the next generation of powerful language models. The researchers argue that the datasets commonly used today, while large, may not be diverse or high-quality enough to help language models truly understand and engage with human language.
The paper introduces DataComp-LM, a framework for developing and evaluating new training datasets that could address these limitations. The key idea is to create datasets that not only have a vast amount of text, but also capture the breadth and nuance of how people actually communicate.
By focusing on dataset composition and quality, the researchers hope to push the boundaries of what language models can do - from engaging in more natural conversations to demonstrating deeper reasoning and understanding. This work could have important implications for fields like question answering, language evaluation, and even multimodal AI.
Technical Explanation
The paper argues that while existing language model training datasets are impressively large, they may not capture the full breadth and nuance of human communication. The researchers propose the DataComp-LM framework as a way to develop and evaluate new, high-quality training datasets that could help address this challenge.
Key elements of the DataComp-LM framework include:
- Comprehensive evaluation metrics to assess dataset quality, diversity, and suitability for training language models
- Techniques for systematically curating datasets that span a wide range of domains, styles, and perspectives
- Procedures for ensuring dataset integrity and minimizing potential biases or contamination
Through experiments and case studies, the paper demonstrates how DataComp-LM can be used to create training datasets that enable language models to perform better on a variety of tasks, including those involving Chinese-centric content.
Critical Analysis
The paper makes a compelling case for the importance of dataset quality and composition in advancing language model capabilities. However, it also acknowledges several caveats and areas for further research:
- Developing comprehensive evaluation metrics for dataset quality is a complex challenge, and the researchers note that more work is needed in this area.
- Curating diverse, high-quality datasets at scale can be resource-intensive, and the paper does not fully address the practical challenges involved.
- The paper focuses primarily on textual data, but language models are increasingly being trained on multimodal inputs, which may require different approaches to dataset development.
Additionally, while the paper highlights the potential benefits of the DataComp-LM framework, it does not provide a thorough comparison to alternative approaches or address potential limitations or drawbacks of the proposed methodology.
Conclusion
The DataComp-LM framework introduced in this paper represents an important step towards developing the next generation of training datasets for language models. By emphasizing the importance of dataset composition and quality, the researchers aim to push the boundaries of what language models can achieve in terms of natural language understanding, reasoning, and engagement.
While the paper leaves some open questions, it lays the groundwork for a more systematic and rigorous approach to dataset curation and evaluation. As language models continue to play an increasingly central role in a wide range of applications, this work could have significant implications for the future of natural language processing and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A. Smith, Hannaneh Hajishirzi, Iz Beltagy, Dirk Groeneveld, Jesse Dodge, Kyle Lo
0
0
Information about pretraining corpora used to train the current best-performing language models is seldom discussed: commercial models rarely detail their data, and even open models are often released without accompanying training data or recipes to reproduce them. As a result, it is challenging to conduct and advance scientific research on language modeling, such as understanding how training data impacts model capabilities and limitations. To facilitate scientific research on language model pretraining, we curate and release Dolma, a three-trillion-token English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. We extensively document Dolma, including its design principles, details about its construction, and a summary of its contents. We present analyses and experimental results on intermediate states of Dolma to share what we have learned about important data curation practices. Finally, we open-source our data curation toolkit to enable reproduction of our work as well as support further research in large-scale data curation.
6/10/2024

GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
Amani Namboori, Shivam Mangale, Andy Rosenbaum, Saleh Soltan
0
0
The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.
4/16/2024
Benchmark Data Contamination of Large Language Models: A Survey
Cheng Xu, Shuhao Guan, Derek Greene, M-Tahar Kechadi
0
0
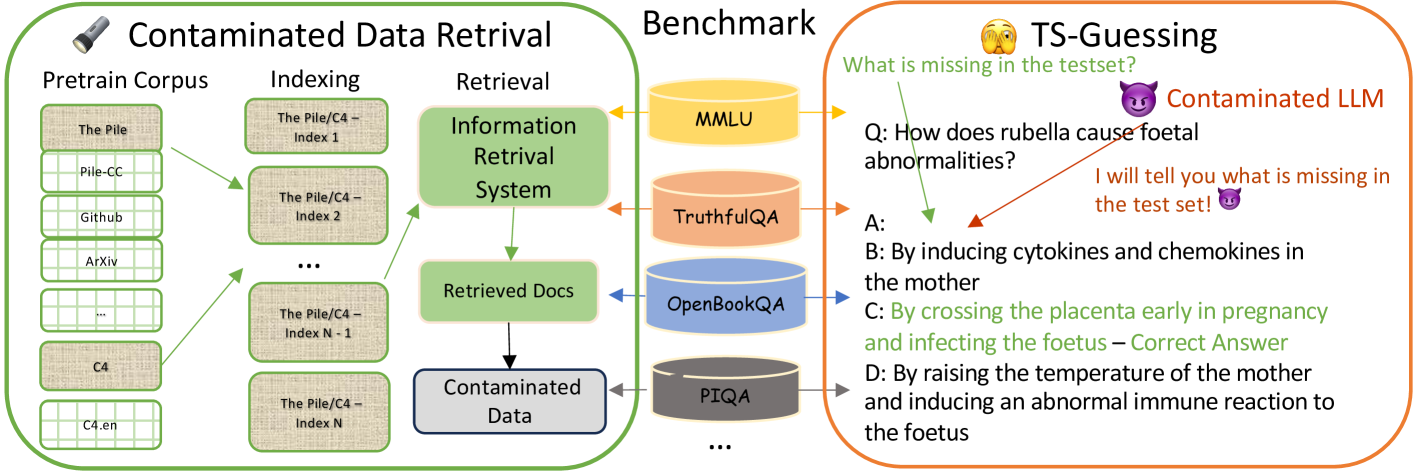
The rapid development of Large Language Models (LLMs) like GPT-4, Claude-3, and Gemini has transformed the field of natural language processing. However, it has also resulted in a significant issue known as Benchmark Data Contamination (BDC). This occurs when language models inadvertently incorporate evaluation benchmark information from their training data, leading to inaccurate or unreliable performance during the evaluation phase of the process. This paper reviews the complex challenge of BDC in LLM evaluation and explores alternative assessment methods to mitigate the risks associated with traditional benchmarks. The paper also examines challenges and future directions in mitigating BDC risks, highlighting the complexity of the issue and the need for innovative solutions to ensure the reliability of LLM evaluation in real-world applications.
6/7/2024
Who's in and who's out? A case study of multimodal CLIP-filtering in DataComp
Rachel Hong, William Agnew, Tadayoshi Kohno, Jamie Morgenstern
0
0
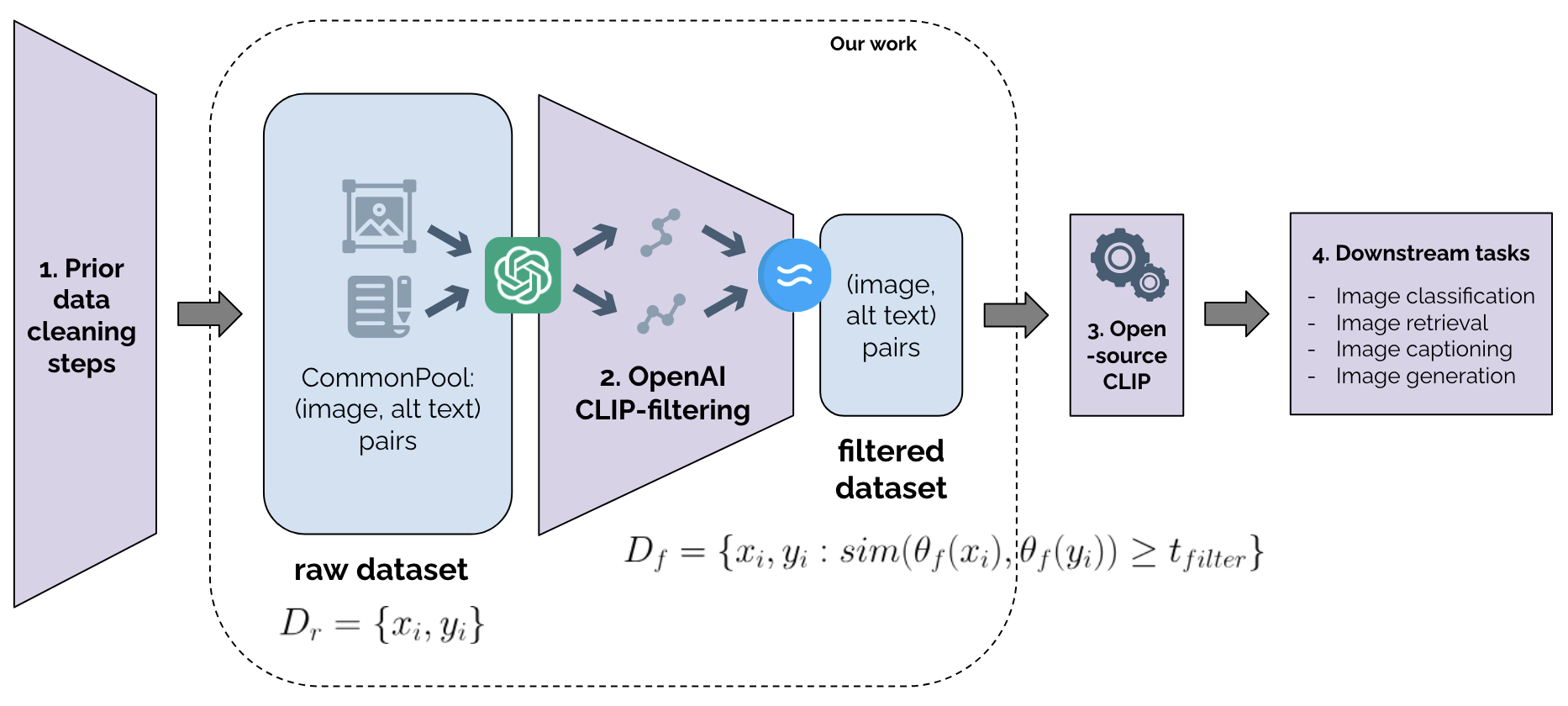
As training datasets become increasingly drawn from unstructured, uncontrolled environments such as the web, researchers and industry practitioners have increasingly relied upon data filtering techniques to filter out the noise of web-scraped data. While datasets have been widely shown to reflect the biases and values of their creators, in this paper we contribute to an emerging body of research that assesses the filters used to create these datasets. We show that image-text data filtering also has biases and is value-laden, encoding specific notions of what is counted as high-quality data. In our work, we audit a standard approach of image-text CLIP-filtering on the academic benchmark DataComp's CommonPool by analyzing discrepancies of filtering through various annotation techniques across multiple modalities of image, text, and website source. We find that data relating to several imputed demographic groups -- such as LGBTQ+ people, older women, and younger men -- are associated with higher rates of exclusion. Moreover, we demonstrate cases of exclusion amplification: not only are certain marginalized groups already underrepresented in the unfiltered data, but CLIP-filtering excludes data from these groups at higher rates. The data-filtering step in the machine learning pipeline can therefore exacerbate representation disparities already present in the data-gathering step, especially when existing filters are designed to optimize a specifically-chosen downstream performance metric like zero-shot image classification accuracy. Finally, we show that the NSFW filter fails to remove sexually-explicit content from CommonPool, and that CLIP-filtering includes several categories of copyrighted content at high rates. Our conclusions point to a need for fundamental changes in dataset creation and filtering practices.
5/15/2024