Who's in and who's out? A case study of multimodal CLIP-filtering in DataComp
2405.08209
0
0
Abstract
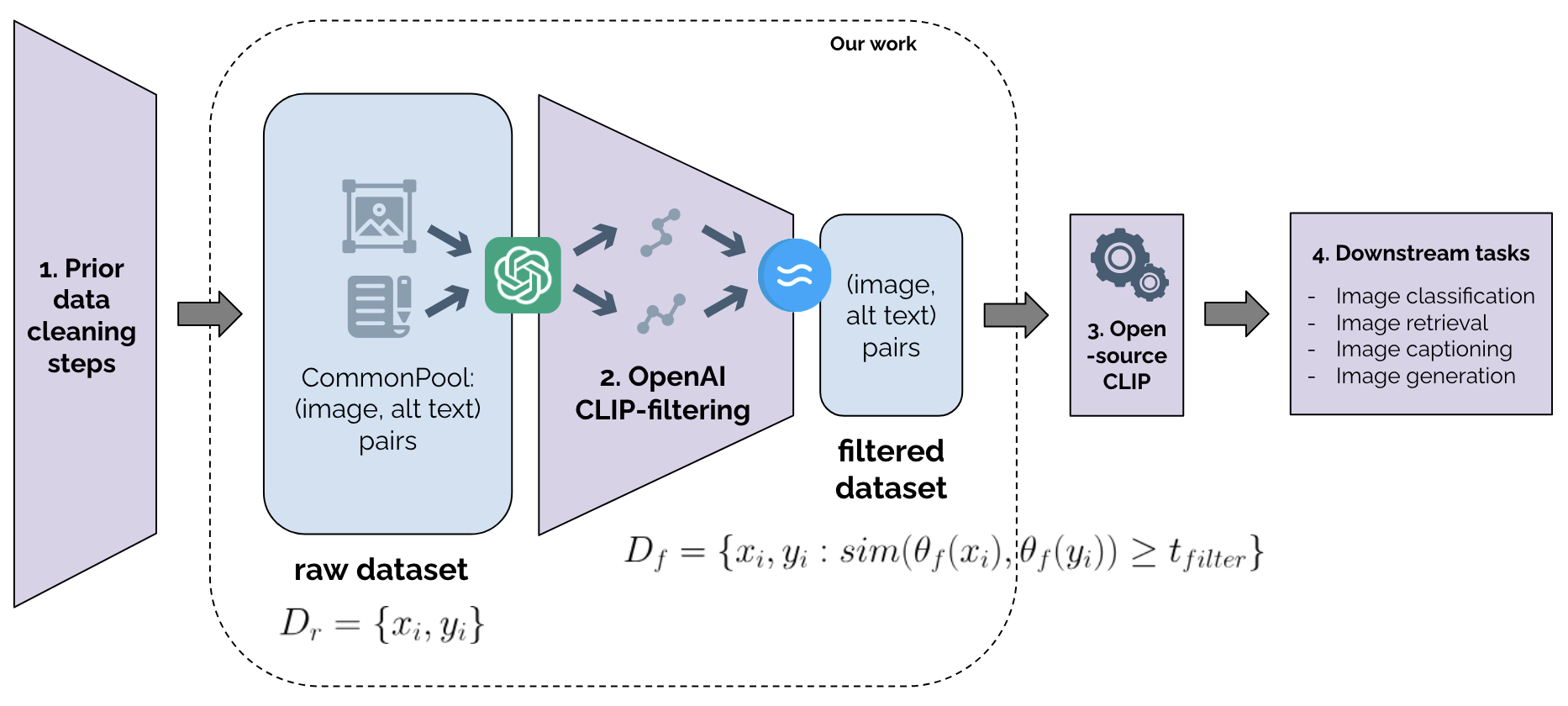
As training datasets become increasingly drawn from unstructured, uncontrolled environments such as the web, researchers and industry practitioners have increasingly relied upon data filtering techniques to filter out the noise of web-scraped data. While datasets have been widely shown to reflect the biases and values of their creators, in this paper we contribute to an emerging body of research that assesses the filters used to create these datasets. We show that image-text data filtering also has biases and is value-laden, encoding specific notions of what is counted as high-quality data. In our work, we audit a standard approach of image-text CLIP-filtering on the academic benchmark DataComp's CommonPool by analyzing discrepancies of filtering through various annotation techniques across multiple modalities of image, text, and website source. We find that data relating to several imputed demographic groups -- such as LGBTQ+ people, older women, and younger men -- are associated with higher rates of exclusion. Moreover, we demonstrate cases of exclusion amplification: not only are certain marginalized groups already underrepresented in the unfiltered data, but CLIP-filtering excludes data from these groups at higher rates. The data-filtering step in the machine learning pipeline can therefore exacerbate representation disparities already present in the data-gathering step, especially when existing filters are designed to optimize a specifically-chosen downstream performance metric like zero-shot image classification accuracy. Finally, we show that the NSFW filter fails to remove sexually-explicit content from CommonPool, and that CLIP-filtering includes several categories of copyrighted content at high rates. Our conclusions point to a need for fundamental changes in dataset creation and filtering practices.
Create account to get full access
Overview
- This paper presents a case study on the use of multimodal CLIP-filtering in the dataset collection process for a project called "DataComp".
- The researchers investigate the potential biases and representation disparities that can arise from using CLIP, a popular multimodal language-image model, to filter the images and text in the dataset.
- The paper explores the impacts of this filtering approach on the final dataset composition and discusses the implications for data ideology and the broader issue of algorithmic bias.
Plain English Explanation
The researchers in this paper looked at how a popular AI model called CLIP can be used to filter the images and text that go into a dataset. CLIP is good at matching up images and the words that describe them, but the researchers found that this filtering process can also introduce biases and leave out certain types of people or content.
For example, CLIP has been shown to have biases against certain demographic groups, and using it to filter a dataset could mean that the final dataset ends up underrepresenting those groups. The researchers call this an issue of "data ideology" - the idea that the choices made in dataset collection can shape the kind of knowledge and narratives that get reflected in AI systems.
To explore this issue, the researchers did a case study on a dataset collection project called "DataComp". They looked at how the CLIP-based filtering affected the composition of the final dataset, and what that might mean for the kinds of insights and applications that could come out of that dataset. The paper also discusses ways to mitigate these biases, such as using techniques like "safe CLIP" to remove harmful content.
The key takeaway is that the choices made in how datasets are built can have important consequences, and researchers need to be thoughtful about the potential biases and representation issues that can arise, especially when using powerful AI models like CLIP in the dataset curation process.
Technical Explanation
The paper investigates the use of multimodal CLIP-based filtering in the dataset collection process for a project called "DataComp". CLIP is a language-image model that can be used to assess the relevance and appropriateness of images and text for inclusion in a dataset.
The researchers analyze the impacts of this CLIP-based filtering approach on the final composition of the DataComp dataset. They find that the filtering can introduce biases and representation disparities, leading to an underrepresentation of certain demographic groups and content types.
To understand these issues, the paper explores the concept of "data ideology" - the idea that the choices made in dataset curation can shape the narratives and knowledge that get reflected in AI systems built on that data. The researchers argue that the use of CLIP-based filtering is an example of this data ideology in action, as the model's own biases and limitations get encoded into the final dataset.
The paper also discusses potential techniques to mitigate these biases, such as using "safe CLIP" to remove harmful content, or exploring methods like CLAP that aim to isolate content from style in language-image models. Approaches like RankCLIP that focus on ranking consistency are also mentioned as potential ways to address these issues.
Overall, the paper highlights the importance of critical examination of the dataset curation process, especially when leveraging powerful AI models like CLIP, in order to ensure more equitable and representative datasets for AI development.
Critical Analysis
The paper provides a valuable case study on the potential pitfalls of using CLIP-based filtering in dataset curation, and the broader implications for data ideology and algorithmic bias. The researchers raise important concerns about how the choices made in this process can lead to the underrepresentation of certain groups and content types in the final dataset.
One limitation of the paper is that it is a case study focused on a single dataset collection project, so the generalizability of the findings may be limited. It would be helpful to see analyses of CLIP-based filtering applied to a wider range of datasets and use cases to better understand the scope of the problem.
Additionally, while the paper discusses some potential mitigation strategies, such as "safe CLIP" and techniques like CLAP, it would be valuable to see a more in-depth exploration of these approaches and their effectiveness in addressing the identified biases. Further research into scaling down CLIP could also yield insights into more efficient and equitable ways to leverage such powerful multimodal models.
Overall, the paper successfully highlights the importance of critically examining the dataset curation process, particularly when using advanced AI models like CLIP. It serves as a call to the research community to be more attentive to issues of data ideology and representation disparities in order to build more inclusive and equitable AI systems.
Conclusion
This paper presents a case study on the use of multimodal CLIP-based filtering in the dataset collection process for the "DataComp" project. The researchers found that this approach can introduce biases and representation disparities, leading to the underrepresentation of certain demographic groups and content types in the final dataset.
The paper explores the broader implications of these findings in the context of "data ideology" - the idea that the choices made in dataset curation can shape the knowledge and narratives reflected in AI systems. The researchers highlight the importance of critical examination of the dataset creation process, especially when using powerful AI models like CLIP, to ensure more equitable and representative datasets for AI development.
While the paper is limited to a single case study, it serves as a valuable contribution to the ongoing discussion around algorithmic bias and the need for more thoughtful and responsible approaches to dataset curation. Further research into mitigation strategies and the application of these findings to a wider range of datasets and use cases could yield additional insights to guide the development of more inclusive and representative AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Demystifying CLIP Data
Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer, Christoph Feichtenhofer
0
0
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at https://github.com/facebookresearch/MetaCLIP.
4/9/2024
🤿
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
Samuele Poppi, Tobia Poppi, Federico Cocchi, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
0
0
Large-scale vision-and-language models, such as CLIP, are typically trained on web-scale data, which can introduce inappropriate content and lead to the development of unsafe and biased behavior. This, in turn, hampers their applicability in sensitive and trustworthy contexts and could raise significant concerns in their adoption. Our research introduces a novel approach to enhancing the safety of vision-and-language models by diminishing their sensitivity to NSFW (not safe for work) inputs. In particular, our methodology seeks to sever toxic linguistic and visual concepts, unlearning the linkage between unsafe linguistic or visual items and unsafe regions of the embedding space. We show how this can be done by fine-tuning a CLIP model on synthetic data obtained from a large language model trained to convert between safe and unsafe sentences, and a text-to-image generator. We conduct extensive experiments on the resulting embedding space for cross-modal retrieval, text-to-image, and image-to-text generation, where we show that our model can be remarkably employed with pre-trained generative models. Our source code and trained models are available at: https://github.com/aimagelab/safe-clip.
4/15/2024
📉
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
Ang'eline Pouget, Lucas Beyer, Emanuele Bugliarello, Xiao Wang, Andreas Peter Steiner, Xiaohua Zhai, Ibrahim Alabdulmohsin
0
0
We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by - and even at odds with - the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
5/27/2024
⚙️
CLAP: Isolating Content from Style through Contrastive Learning with Augmented Prompts
Yichao Cai, Yuhang Liu, Zhen Zhang, Javen Qinfeng Shi
0
0
Contrastive vision-language models, such as CLIP, have garnered considerable attention for various dowmsteam tasks, mainly due to the remarkable ability of the learned features for generalization. However, the features they learned often blend content and style information, which somewhat limits their generalization capabilities under distribution shifts. To address this limitation, we adopt a causal generative perspective for multimodal data and propose contrastive learning with data augmentation to disentangle content features from the original representations. To achieve this, we begins with exploring image augmentation techniques and develop a method to seamlessly integrate them into pre-trained CLIP-like models to extract pure content features. Taking a step further, recognizing the inherent semantic richness and logical structure of text data, we explore the use of text augmentation to isolate latent content from style features. This enables CLIP-like model's encoders to concentrate on latent content information, refining the learned representations by pre-trained CLIP-like models. Our extensive experiments across diverse datasets demonstrate significant improvements in zero-shot and few-shot classification tasks, alongside enhanced robustness to various perturbations. These results underscore the effectiveness of our proposed methods in refining vision-language representations and advancing the state-of-the-art in multimodal learning.
4/30/2024