Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
2402.00159
0
0
💬
Abstract
Information about pretraining corpora used to train the current best-performing language models is seldom discussed: commercial models rarely detail their data, and even open models are often released without accompanying training data or recipes to reproduce them. As a result, it is challenging to conduct and advance scientific research on language modeling, such as understanding how training data impacts model capabilities and limitations. To facilitate scientific research on language model pretraining, we curate and release Dolma, a three-trillion-token English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. We extensively document Dolma, including its design principles, details about its construction, and a summary of its contents. We present analyses and experimental results on intermediate states of Dolma to share what we have learned about important data curation practices. Finally, we open-source our data curation toolkit to enable reproduction of our work as well as support further research in large-scale data curation.
Create account to get full access
Overview
- Researchers have created a large, diverse corpus of English text called Dolma, containing over 3 trillion tokens from various sources including web content, scientific papers, code, books, social media, and encyclopedias.
- The goal is to facilitate more open and reproducible research on language models by providing a well-documented dataset for pretraining.
- The researchers share insights from their data curation process and release open-source tools to enable others to build similar large-scale datasets.
Plain English Explanation
The paper discusses the creation of a new dataset called Dolma, which is a massive collection of English text from many different sources. This includes things like websites, academic papers, computer code, books, social media, and encyclopedias. In total, the dataset contains over 3 trillion individual words or "tokens."
The main reason the researchers built Dolma is to support more open and scientific research on language models - the large AI systems that are trained on huge amounts of text data to understand and generate human language. Currently, the datasets used to train the best-performing language models are often kept secret by the companies that develop them. This makes it hard for other researchers to study how the training data affects the models' capabilities and limitations.
By openly sharing the Dolma dataset and documenting how it was created, the researchers hope to enable more people to study language models and advance the field. They also release the tools they used to build Dolma, so others can create similar large-scale datasets for their own research.
Throughout the process, the researchers learned important lessons about best practices for curating diverse, high-quality data for training language models. They share these insights in the paper, providing a roadmap for others who want to build their own large text corpora.
Technical Explanation
The paper presents the Dolma dataset, a 3-trillion-token English corpus, and the researchers' approach to its creation. Dolma was constructed from a wide variety of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials.
The researchers extensively document Dolma, including its design principles, construction details, and a summary of its contents. They share analyses and experimental results on intermediate states of Dolma to highlight important data curation practices, such as filtering low-quality or redundant content.
Additionally, the researchers open-source their data curation toolkit to enable reproduction of their work and support further research in large-scale data curation for language models. This aligns with their goal of facilitating more open and reproducible scientific research on language modeling, which is often hindered by the lack of transparency around commercial models' training data.
The paper's findings emphasize the value of curating diverse, high-quality datasets like Dolma to advance the state of the art in language modeling. By providing this resource, the researchers hope to enable researchers to better understand how training data impacts model capabilities and limitations, leading to more robust and generalizable language models.
Critical Analysis
The paper makes a compelling case for the importance of open and reproducible research in language modeling, a field that has been dominated by commercial models with opaque training data. The creation of the Dolma dataset is a significant step towards addressing this problem, as it provides a large-scale, well-documented corpus for researchers to use in their studies.
One potential limitation of the Dolma dataset is that, like many web-based corpora, it may contain biases and artifacts that could influence the performance and behavior of language models trained on it. The researchers acknowledge this issue and mention plans to further analyze and mitigate such biases in future work.
Additionally, while the dataset is made available to the research community, the sheer size of Dolma (3 trillion tokens) may pose challenges for some researchers in terms of storage, processing, and experimentation. The researchers could potentially explore ways to make the dataset more accessible, such as providing subsets or sampling techniques.
Overall, the Dolma dataset and the researchers' approach to its creation represent an important contribution to the field of language modeling. By embracing open science and sharing their insights, the researchers have laid the groundwork for more collaborative and impactful research in this area.
Conclusion
The paper presents the Dolma dataset, a large and diverse English corpus of over 3 trillion tokens, as a means to facilitate more open and reproducible research on language modeling. By openly sharing this dataset and the tools used to create it, the researchers aim to enable other researchers to better understand the impact of training data on language model capabilities and limitations.
The open-sourcing of the Dolma dataset and the researchers' data curation toolkit is a significant step towards promoting transparency and collaboration in the field of language modeling. This work has the potential to drive advancements in the development of more robust and generalizable language models, ultimately benefiting a wide range of applications that rely on natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Zyda: A 1.3T Dataset for Open Language Modeling
Yury Tokpanov, Beren Millidge, Paolo Glorioso, Jonathan Pilault, Adam Ibrahim, James Whittington, Quentin Anthony
0
0
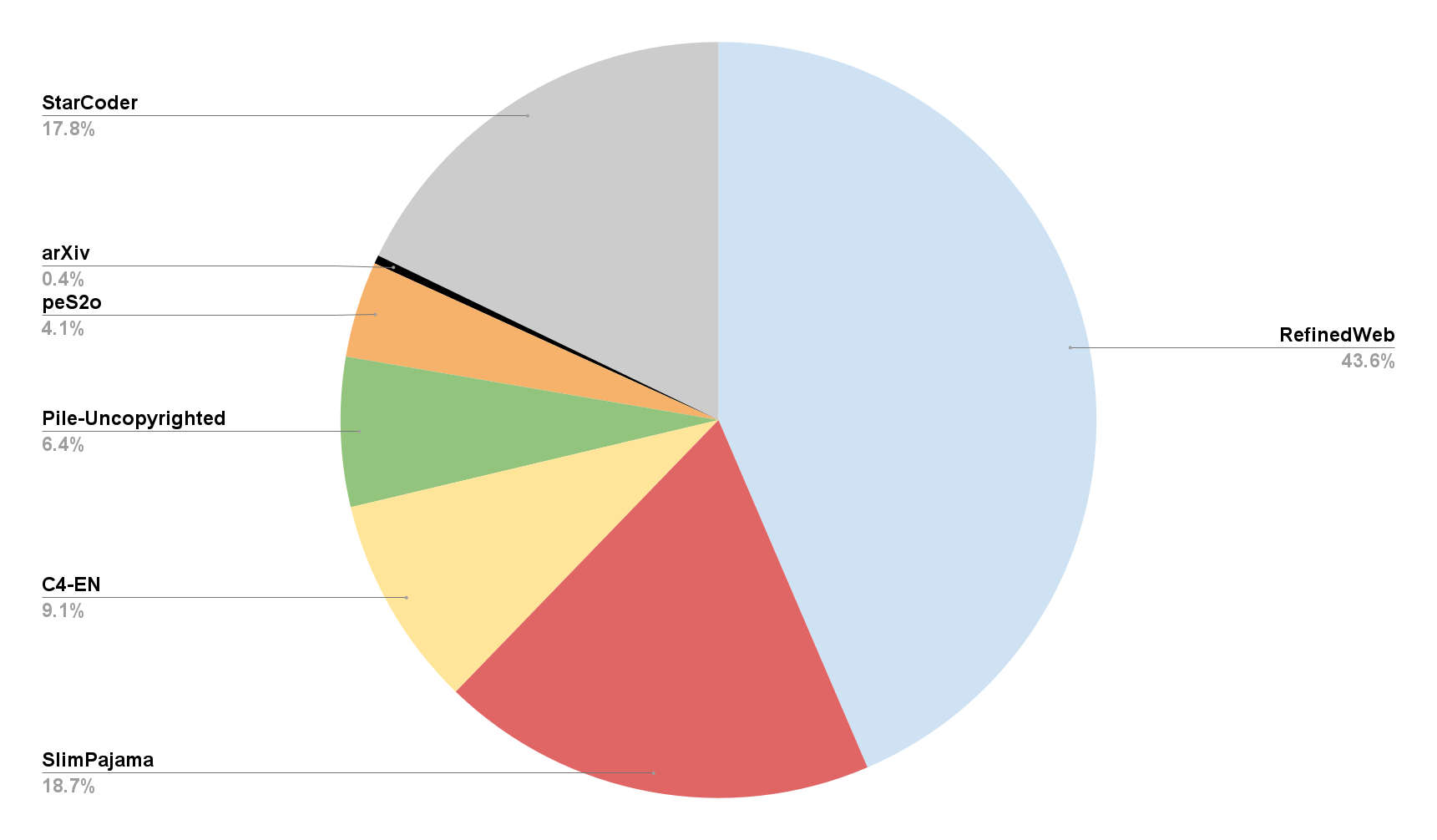
The size of large language models (LLMs) has scaled dramatically in recent years and their computational and data requirements have surged correspondingly. State-of-the-art language models, even at relatively smaller sizes, typically require training on at least a trillion tokens. This rapid advancement has eclipsed the growth of open-source datasets available for large-scale LLM pretraining. In this paper, we introduce Zyda (Zyphra Dataset), a dataset under a permissive license comprising 1.3 trillion tokens, assembled by integrating several major respected open-source datasets into a single, high-quality corpus. We apply rigorous filtering and deduplication processes, both within and across datasets, to maintain and enhance the quality derived from the original datasets. Our evaluations show that Zyda not only competes favorably with other open datasets like Dolma, FineWeb, and RefinedWeb, but also substantially improves the performance of comparable models from the Pythia suite. Our rigorous data processing methods significantly enhance Zyda's effectiveness, outperforming even the best of its constituent datasets when used independently.
6/5/2024
OLMo: Accelerating the Science of Language Models
Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
0
0
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, we have built OLMo, a competitive, truly Open Language Model, to enable the scientific study of language models. Unlike most prior efforts that have only released model weights and inference code, we release OLMo alongside open training data and training and evaluation code. We hope this release will empower the open research community and inspire a new wave of innovation.
6/11/2024
DataComp-LM: In search of the next generation of training sets for language models
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, Saurabh Garg, Rui Xin, Niklas Muennighoff, Reinhard Heckel, Jean Mercat, Mayee Chen, Suchin Gururangan, Mitchell Wortsman, Alon Albalak, Yonatan Bitton, Marianna Nezhurina, Amro Abbas, Cheng-Yu Hsieh, Dhruba Ghosh, Josh Gardner, Maciej Kilian, Hanlin Zhang, Rulin Shao, Sarah Pratt, Sunny Sanyal, Gabriel Ilharco, Giannis Daras, Kalyani Marathe, Aaron Gokaslan, Jieyu Zhang, Khyathi Chandu, Thao Nguyen, Igor Vasiljevic, Sham Kakade, Shuran Song, Sujay Sanghavi, Fartash Faghri, Sewoong Oh, Luke Zettlemoyer, Kyle Lo, Alaaeldin El-Nouby, Hadi Pouransari, Alexander Toshev, Stephanie Wang, Dirk Groeneveld, Luca Soldaini, Pang Wei Koh, Jenia Jitsev, Thomas Kollar, Alexandros G. Dimakis, Yair Carmon, Achal Dave, Ludwig Schmidt, Vaishaal Shankar
0
0
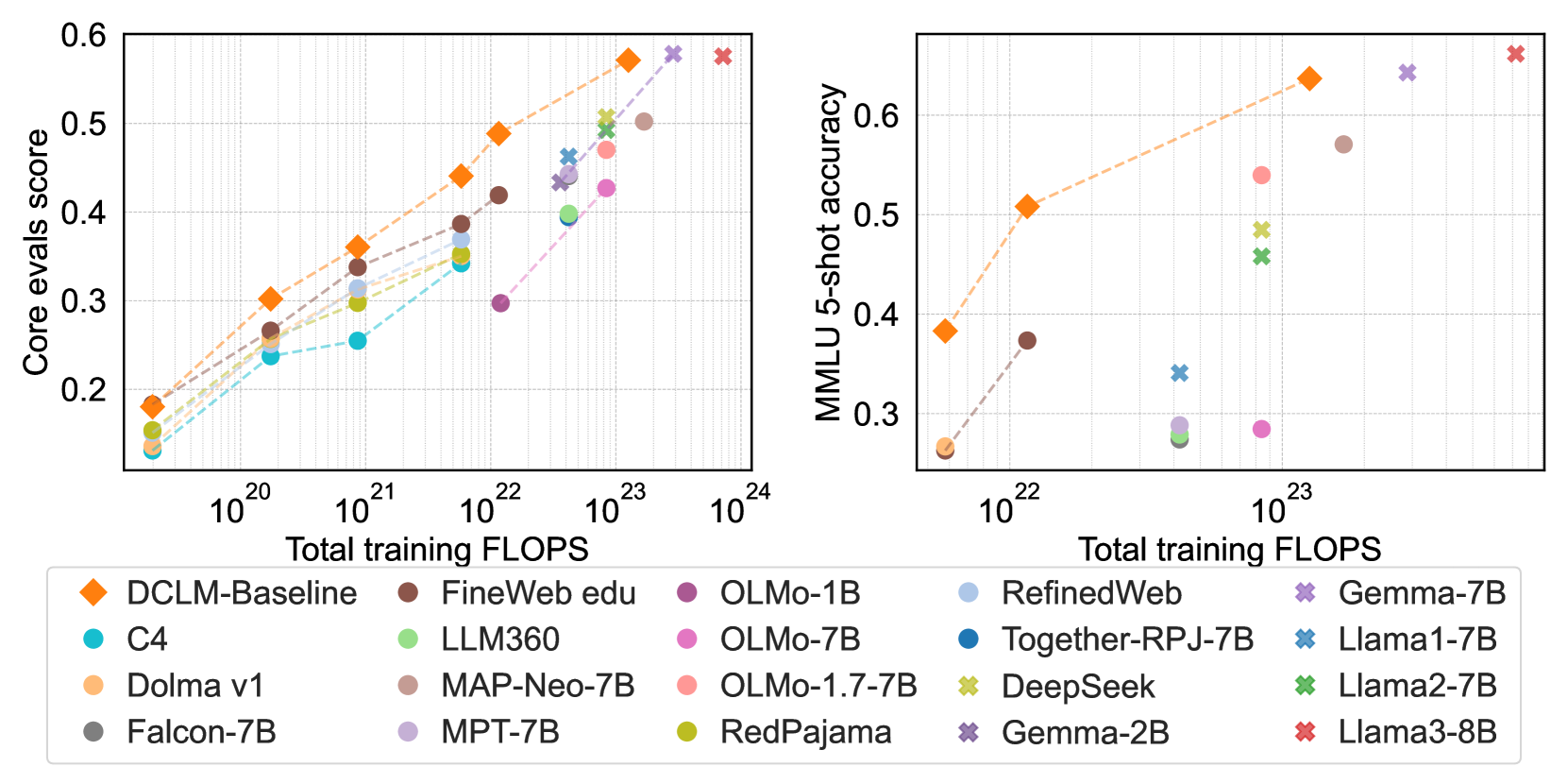
We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations. Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters. As a baseline for DCLM, we conduct extensive experiments and find that model-based filtering is key to assembling a high-quality training set. The resulting dataset, DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute. Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B. Our results highlight the importance of dataset design for training language models and offer a starting point for further research on data curation.
6/24/2024
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Taishi Nakamura, Mayank Mishra, Simone Tedeschi, Yekun Chai, Jason T Stillerman, Felix Friedrich, Prateek Yadav, Tanmay Laud, Vu Minh Chien, Terry Yue Zhuo, Diganta Misra, Ben Bogin, Xuan-Son Vu, Marzena Karpinska, Arnav Varma Dantuluri, Wojciech Kusa, Tommaso Furlanello, Rio Yokota, Niklas Muennighoff, Suhas Pai, Tosin Adewumi, Veronika Laippala, Xiaozhe Yao, Adalberto Junior, Alpay Ariyak, Aleksandr Drozd, Jordan Clive, Kshitij Gupta, Liangyu Chen, Qi Sun, Ken Tsui, Noah Persaud, Nour Fahmy, Tianlong Chen, Mohit Bansal, Nicolo Monti, Tai Dang, Ziyang Luo, Tien-Tung Bui, Roberto Navigli, Virendra Mehta, Matthew Blumberg, Victor May, Huu Nguyen, Sampo Pyysalo
0
0
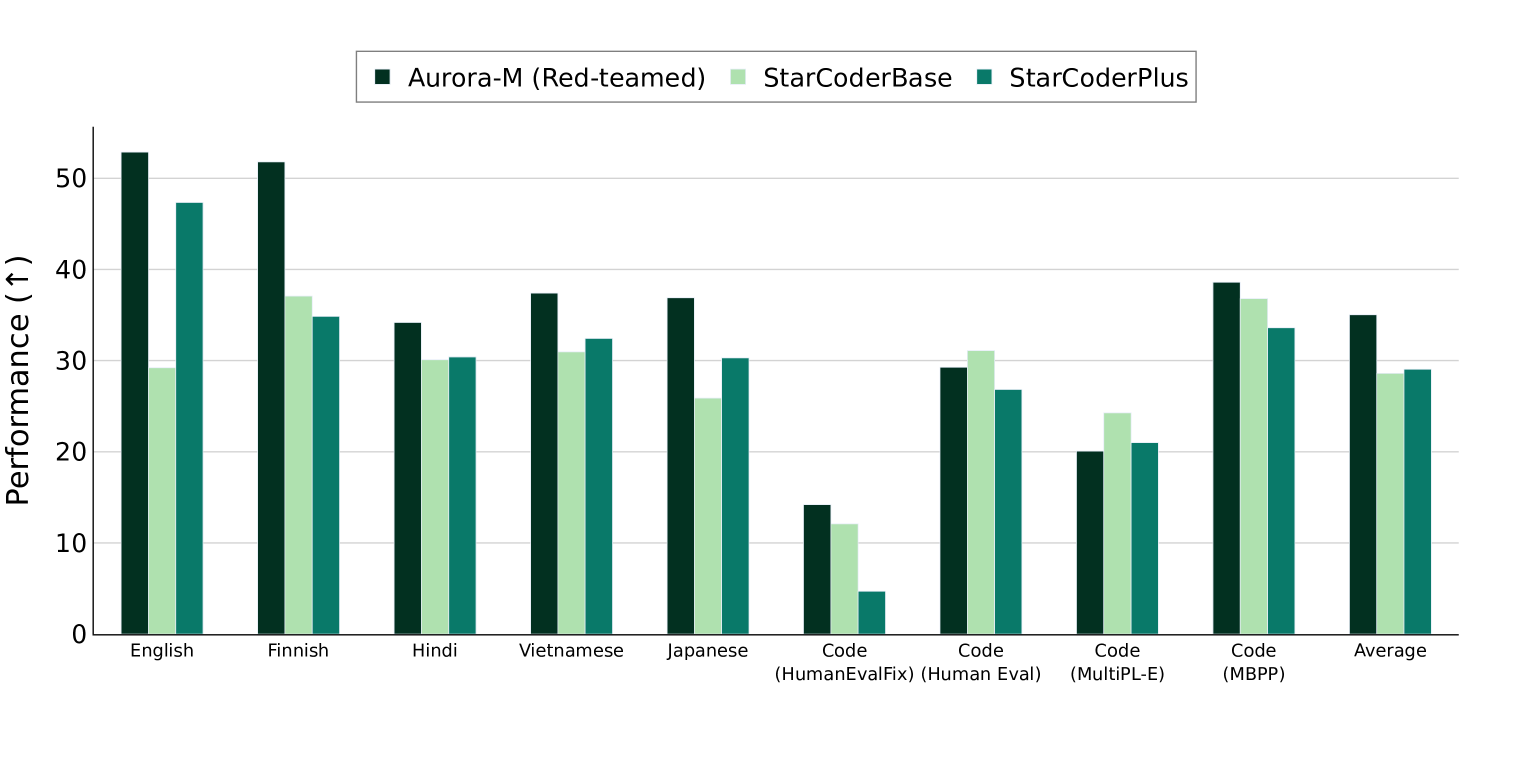
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
4/24/2024