Debating with More Persuasive LLMs Leads to More Truthful Answers
2402.06782
0
0
Abstract
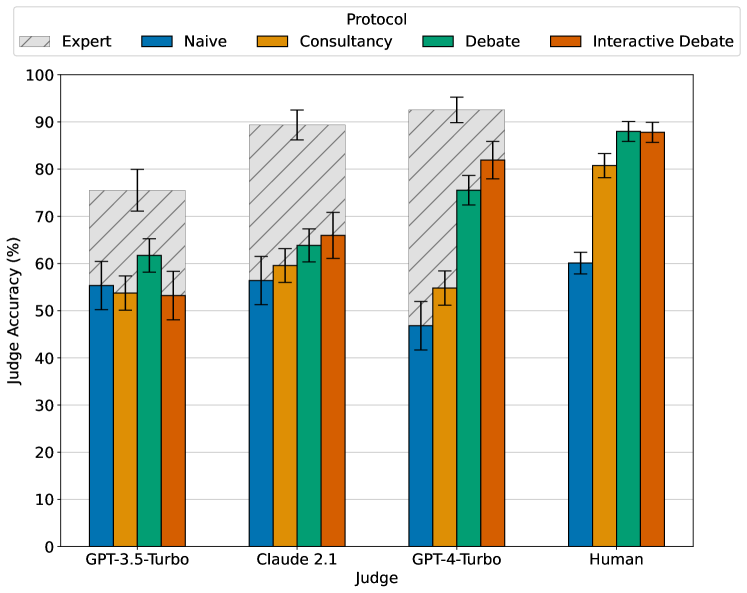
Common methods for aligning large language models (LLMs) with desired behaviour heavily rely on human-labelled data. However, as models grow increasingly sophisticated, they will surpass human expertise, and the role of human evaluation will evolve into non-experts overseeing experts. In anticipation of this, we ask: can weaker models assess the correctness of stronger models? We investigate this question in an analogous setting, where stronger models (experts) possess the necessary information to answer questions and weaker models (non-experts) lack this information. The method we evaluate is debate, where two LLM experts each argue for a different answer, and a non-expert selects the answer. We find that debate consistently helps both non-expert models and humans answer questions, achieving 76% and 88% accuracy respectively (naive baselines obtain 48% and 60%). Furthermore, optimising expert debaters for persuasiveness in an unsupervised manner improves non-expert ability to identify the truth in debates. Our results provide encouraging empirical evidence for the viability of aligning models with debate in the absence of ground truth.
Create account to get full access
Overview
- This paper explores how debating with more persuasive large language models (LLMs) can lead to more truthful answers.
- The researchers designed protocols to pit LLMs against each other in debates and examined the truthfulness of the resulting outputs.
- Their findings suggest that LLMs with greater persuasive capabilities can help uncover more truthful information through the debate process.
Plain English Explanation
In this study, the researchers looked at how powerful language AI models can be used to help verify the truthfulness of information. They created a system where two AI models would debate each other on a given topic. The key insight is that the more persuasive and capable AI model would be able to identify and expose any flaws or falsehoods in the other model's arguments, ultimately leading to a more truthful overall outcome.
The idea is similar to how human debates can help surface the truth - the more skilled debaters can often poke holes in each other's claims, gradually honing in on the most accurate and evidence-based positions. By applying this dynamic to powerful language AI models, the researchers found that the debating process could be leveraged to uncover truthful information more effectively than just relying on a single AI model's output.
This research builds on previous work exploring how conversational AI can be used for news debiasing and how persuasive language models can be. The key innovation here is applying these capabilities in a debating context to arrive at more truthful conclusions.
Technical Explanation
The researchers designed several protocols to test their hypothesis. In the first protocol, they had two LLMs debate a given topic, with one model assigned the "pro" position and the other the "con" position. The models took turns making arguments, with the other model having the opportunity to rebut.
The researchers then evaluated the truthfulness of the final outputs by having human raters assess them. They found that the debated outputs were rated as significantly more truthful than outputs from a single LLM providing a unilateral response.
In a second protocol, the researchers experimented with giving the LLMs varying levels of persuasive capability. They found that when one model had a clear persuasive advantage, it was better able to identify and counter the flaws in the other model's arguments, leading to a more truthful final output.
These findings suggest that debating with more persuasive LLMs can be an effective way to help humans verify the truthfulness of information, by leveraging the models' ability to challenge each other's claims and surface the most well-supported positions.
Critical Analysis
The researchers acknowledge several limitations in their work. First, the truthfulness evaluations were conducted by human raters, which introduces potential biases and subjectivity. Additionally, the experiments were limited to a small set of topics, and it's unclear how the results would scale to more complex or nuanced subject matter.
Another potential concern is that the debating process could become an arms race of persuasive capability, where the most rhetorically skilled model wins out regardless of the actual accuracy of its claims. This could potentially lead to further challenges around explainability and contestability of the models' decisions.
Further research is needed to explore the long-term implications of this approach, particularly around the ethical considerations of using powerful language models to determine truth. Careful thought must be given to ensuring these systems are transparent, accountable, and aligned with human values.
Conclusion
This research presents a novel approach to leveraging the capabilities of large language models to help uncover truthful information. By pitting LLMs against each other in a debating context, the researchers found that the more persuasive models were able to identify and counter flaws in their opponents' arguments, leading to more truthful final outputs.
These findings have important implications for the use of AI in information verification and decision-making processes. While further work is needed to address the potential limitations and ethical concerns, this study demonstrates the potential for AI-driven debates to serve as a useful tool for surfacing truthful and well-supported positions on complex topics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evaluating the Performance of Large Language Models via Debates
Behrad Moniri, Hamed Hassani, Edgar Dobriban
0
0
Large Language Models (LLMs) are rapidly evolving and impacting various fields, necessitating the development of effective methods to evaluate and compare their performance. Most current approaches for performance evaluation are either based on fixed, domain-specific questions that lack the flexibility required in many real-world applications where tasks are not always from a single domain, or rely on human input, making them unscalable. We propose an automated benchmarking framework based on debates between LLMs, judged by another LLM. This method assesses not only domain knowledge, but also skills such as problem definition and inconsistency recognition. We evaluate the performance of various state-of-the-art LLMs using the debate framework and achieve rankings that align closely with popular rankings based on human input, eliminating the need for costly human crowdsourcing.
6/18/2024
An Empirical Analysis on Large Language Models in Debate Evaluation
Xinyi Liu, Pinxin Liu, Hangfeng He
0
0
In this study, we investigate the capabilities and inherent biases of advanced large language models (LLMs) such as GPT-3.5 and GPT-4 in the context of debate evaluation. We discover that LLM's performance exceeds humans and surpasses the performance of state-of-the-art methods fine-tuned on extensive datasets in debate evaluation. We additionally explore and analyze biases present in LLMs, including positional bias, lexical bias, order bias, which may affect their evaluative judgments. Our findings reveal a consistent bias in both GPT-3.5 and GPT-4 towards the second candidate response presented, attributed to prompt design. We also uncover lexical biases in both GPT-3.5 and GPT-4, especially when label sets carry connotations such as numerical or sequential, highlighting the critical need for careful label verbalizer selection in prompt design. Additionally, our analysis indicates a tendency of both models to favor the debate's concluding side as the winner, suggesting an end-of-discussion bias.
6/5/2024

Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, Dieuwke Hupkes
0
0
Offering a promising solution to the scalability challenges associated with human evaluation, the LLM-as-a-judge paradigm is rapidly gaining traction as an approach to evaluating large language models (LLMs). However, there are still many open questions about the strengths and weaknesses of this paradigm, and what potential biases it may hold. In this paper, we present a comprehensive study of the performance of various LLMs acting as judges. We leverage TriviaQA as a benchmark for assessing objective knowledge reasoning of LLMs and evaluate them alongside human annotations which we found to have a high inter-annotator agreement. Our study includes 9 judge models and 9 exam taker models -- both base and instruction-tuned. We assess the judge model's alignment across different model sizes, families, and judge prompts. Among other results, our research rediscovers the importance of using Cohen's kappa as a metric of alignment as opposed to simple percent agreement, showing that judges with high percent agreement can still assign vastly different scores. We find that both Llama-3 70B and GPT-4 Turbo have an excellent alignment with humans, but in terms of ranking exam taker models, they are outperformed by both JudgeLM-7B and the lexical judge Contains, which have up to 34 points lower human alignment. Through error analysis and various other studies, including the effects of instruction length and leniency bias, we hope to provide valuable lessons for using LLMs as judges in the future.
6/19/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024