Deceptive Semantic Shortcuts on Reasoning Chains: How Far Can Models Go without Hallucination?
2311.09702
0
0
👁️
Abstract
Despite the recent advancement in large language models (LLMs) and their high performances across numerous benchmarks, recent research has unveiled that LLMs suffer from hallucinations and unfaithful reasoning. This work studies a specific type of hallucination induced by semantic associations. Specifically, we investigate to what extent LLMs take shortcuts from certain keyword/entity biases in the prompt instead of following the correct reasoning path. To quantify this phenomenon, we propose a novel probing method and benchmark called EureQA. We start from questions that LLMs will answer correctly with utmost certainty, and mask the important entity with evidence sentence recursively, asking models to find masked entities according to a chain of evidence before answering the question. During the construction of the evidence, we purposefully replace semantic clues (entities) that may lead to the correct answer with distractor clues (evidence) that will not directly lead to the correct answer but require a chain-like reasoning process. We evaluate if models can follow the correct reasoning chain instead of short-cutting through distractor clues. We find that existing LLMs lack the necessary capabilities to follow correct reasoning paths and resist the attempt of greedy shortcuts. We show that the distractor semantic associations often lead to model hallucination, which is strong evidence that questions the validity of current LLM reasoning.
Create account to get full access
Overview
- Recent research has shown that large language models (LLMs) can suffer from hallucinations and unfaithful reasoning, even when performing well on benchmarks.
- This work investigates a specific type of hallucination induced by semantic associations, where LLMs take shortcuts based on keyword/entity biases in the prompt instead of following the correct reasoning path.
- The researchers propose a novel probing method and benchmark called EureQA to quantify this phenomenon.
Plain English Explanation
Large language models (LLMs) have made impressive strides in recent years, achieving high performance on various benchmarks. However, recent research has revealed that these models can sometimes suffer from hallucinations and unfaithful reasoning. This means they may provide answers that seem plausible but are actually incorrect, relying on shortcuts rather than following the proper reasoning process.
The researchers in this study wanted to investigate a specific type of hallucination caused by semantic associations. They found that LLMs sometimes take shortcuts based on certain keywords or entities in the prompt, rather than truly understanding the underlying logic and chain of evidence required to answer the question correctly.
To better understand this phenomenon, the researchers developed a novel probing method and benchmark called EureQA. The key idea is to start with questions that LLMs can answer with high confidence, and then systematically mask important entities while introducing distracting evidence that could lead the model astray. By evaluating whether the models can follow the correct reasoning chain instead of relying on these semantic shortcuts, the researchers aim to assess the models' true understanding and reasoning capabilities.
Technical Explanation
The researchers built the EureQA benchmark by starting with questions that existing LLMs can answer correctly with high certainty. They then recursively masked the important entities in the question and provided a chain of evidence to guide the model toward the correct answer.
Importantly, the researchers purposefully included distractor clues (evidence) that were semantically related but did not directly lead to the correct answer. This was done to force the models to follow the correct reasoning path rather than taking a shortcut based on the distractor clues.
By evaluating the performance of existing LLMs on this benchmark, the researchers found that the models often failed to resist the temptation of the distractor semantic associations, leading to hallucinations and unfaithful reasoning. This suggests that current LLMs lack the necessary capabilities to consistently follow the correct reasoning chain, even when faced with well-designed prompts that should guide them toward the right answer.
Critical Analysis
The researchers acknowledge that this work focuses on a specific type of hallucination induced by semantic associations, and there may be other forms of hallucination that LLMs are susceptible to. Additionally, the EureQA benchmark may not capture all the nuances of real-world reasoning tasks, and further research is needed to fully understand the limitations of current LLMs.
That said, the findings presented in this paper raise important questions about the validity of current LLM reasoning. The tendency of these models to take shortcuts and rely on semantic associations, rather than following the logical chain of evidence, suggests that their performance on benchmarks may not accurately reflect their true reasoning capabilities. This has implications for the use of LLMs in critical applications and highlights the need for continued research and development to address these limitations.
Conclusion
This study sheds light on a specific type of hallucination in large language models, where they rely on semantic associations and shortcuts instead of following the correct reasoning path. The researchers' novel EureQA benchmark provides a way to quantify and assess this phenomenon, revealing significant shortcomings in the reasoning capabilities of current LLMs.
These findings have important implications for the development and deployment of large language models, as they suggest that the models' high performance on benchmarks may not always translate to robust and trustworthy reasoning in real-world applications. Further research is needed to better understand and mitigate these limitations, with the ultimate goal of creating language models that can engage in faithful and reliable reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Break the Chain: Large Language Models Can be Shortcut Reasoners
Mengru Ding, Hanmeng Liu, Zhizhang Fu, Jian Song, Wenbo Xie, Yue Zhang
0
0
Recent advancements in Chain-of-Thought (CoT) reasoning utilize complex modules but are hampered by high token consumption, limited applicability, and challenges in reproducibility. This paper conducts a critical evaluation of CoT prompting, extending beyond arithmetic to include complex logical and commonsense reasoning tasks, areas where standard CoT methods fall short. We propose the integration of human-like heuristics and shortcuts into language models (LMs) through break the chain strategies. These strategies disrupt traditional CoT processes using controlled variables to assess their efficacy. Additionally, we develop innovative zero-shot prompting strategies that encourage the use of shortcuts, enabling LMs to quickly exploit reasoning clues and bypass detailed procedural steps. Our comprehensive experiments across various LMs, both commercial and open-source, reveal that LMs maintain effective performance with break the chain strategies. We also introduce ShortcutQA, a dataset specifically designed to evaluate reasoning through shortcuts, compiled from competitive tests optimized for heuristic reasoning tasks such as forward/backward reasoning and simplification. Our analysis confirms that ShortcutQA not only poses a robust challenge to LMs but also serves as an essential benchmark for enhancing reasoning efficiency in AI.
6/12/2024
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
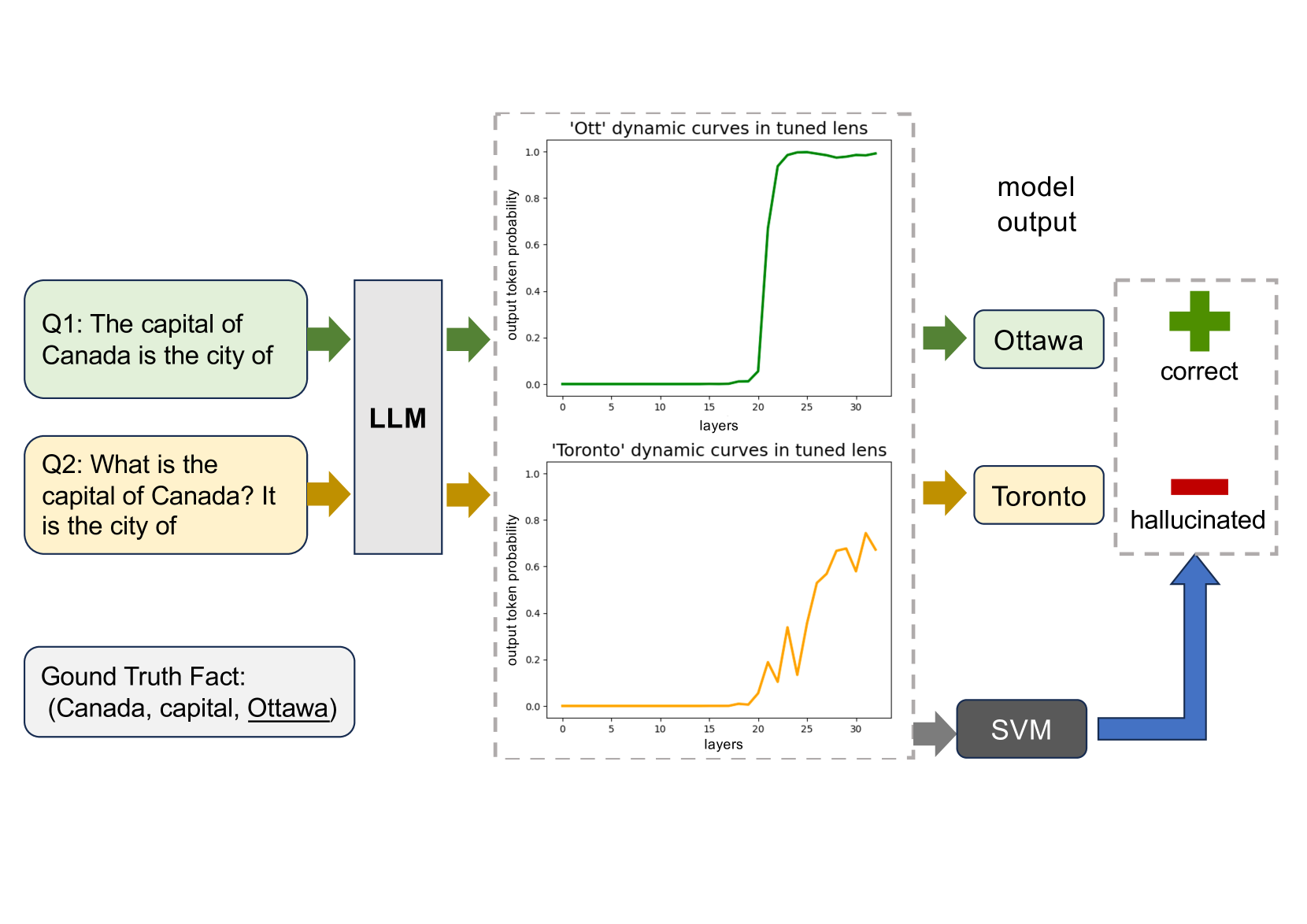
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024
Mechanistic Understanding and Mitigation of Language Model Non-Factual Hallucinations
Lei Yu, Meng Cao, Jackie Chi Kit Cheung, Yue Dong
0
0
State-of-the-art language models (LMs) sometimes generate non-factual hallucinations that misalign with world knowledge. To explore the mechanistic causes of these hallucinations, we create diagnostic datasets with subject-relation queries and adapt interpretability methods to trace hallucinations through internal model representations. We discover two general and distinct mechanistic causes of hallucinations shared across LMs (Llama-2, Pythia, GPT-J): 1) knowledge enrichment hallucinations: insufficient subject attribute knowledge in lower layer MLPs, and 2) answer extraction hallucinations: failure to select the correct object attribute in upper layer attention heads. We also found these two internal mechanistic causes of hallucinations are reflected in external manifestations. Based on insights from our mechanistic analysis, we propose a novel hallucination mitigation method through targeted restoration of the LM's internal fact recall pipeline, demonstrating superior performance compared to baselines.
6/19/2024

Analyzing LLM Behavior in Dialogue Summarization: Unveiling Circumstantial Hallucination Trends
Sanjana Ramprasad, Elisa Ferracane, Zachary C. Lipton
0
0
Recent advancements in large language models (LLMs) have considerably advanced the capabilities of summarization systems. However, they continue to face concerns about hallucinations. While prior work has evaluated LLMs extensively in news domains, most evaluation of dialogue summarization has focused on BART-based models, leaving a gap in our understanding of their faithfulness. Our work benchmarks the faithfulness of LLMs for dialogue summarization, using human annotations and focusing on identifying and categorizing span-level inconsistencies. Specifically, we focus on two prominent LLMs: GPT-4 and Alpaca-13B. Our evaluation reveals subtleties as to what constitutes a hallucination: LLMs often generate plausible inferences, supported by circumstantial evidence in the conversation, that lack direct evidence, a pattern that is less prevalent in older models. We propose a refined taxonomy of errors, coining the category of Circumstantial Inference to bucket these LLM behaviors and release the dataset. Using our taxonomy, we compare the behavioral differences between LLMs and older fine-tuned models. Additionally, we systematically assess the efficacy of automatic error detection methods on LLM summaries and find that they struggle to detect these nuanced errors. To address this, we introduce two prompt-based approaches for fine-grained error detection that outperform existing metrics, particularly for identifying Circumstantial Inference.
6/6/2024