Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text
2311.12373
0
0
📶
Abstract
Significant progress has been made on text generation by pre-trained language models (PLMs), yet distinguishing between human and machine-generated text poses an escalating challenge. This paper offers an in-depth evaluation of three distinct methods used to address this task: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning. These approaches are rigorously tested on a wide range of machine-generated texts, providing a benchmark of their competence in distinguishing between human-authored and machine-authored linguistic constructs. The results reveal considerable differences in performance across methods, thus emphasizing the continued need for advancement in this crucial area of NLP. This study offers valuable insights and paves the way for future research aimed at creating robust and highly discriminative models.
Create account to get full access
Overview
- This paper evaluates different methods for distinguishing between human-written and machine-generated text, an increasingly important challenge as language models become more advanced.
- The researchers rigorously tested three approaches: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning.
- The results reveal significant differences in performance across the methods, highlighting the need for continued progress in this crucial area of natural language processing (NLP).
Plain English Explanation
As language models have become more sophisticated, it has become increasingly difficult to tell whether a piece of text was written by a human or generated by a machine. This paper examines several different techniques that can be used to address this challenge.
The researchers looked at three main approaches:
- Traditional Shallow Learning: Using relatively simple machine learning models to analyze the text.
- Language Model (LM) Fine-tuning: Taking a pre-trained language model and fine-tuning it to specialize in detecting machine-generated text.
- Multilingual Model Fine-tuning: Similar to the LM fine-tuning approach, but using a model that can handle multiple languages.
The team put these methods through a rigorous set of tests, evaluating their performance on a wide range of machine-generated text samples. The results showed that the different approaches had quite varied levels of success in distinguishing human-written and machine-generated content.
This study highlights the continued need for advancements in this important area of natural language processing. By better understanding the strengths and limitations of current techniques, researchers can work towards building more robust and accurate models for detecting machine-generated text.
Technical Explanation
The paper presents a comprehensive evaluation of three distinct methods for deciphering the authenticity of textual content:
- Traditional Shallow Learning: The researchers used relatively simple machine learning models, such as logistic regression and support vector machines, to analyze the linguistic features of the text samples.
- Language Model (LM) Fine-tuning: The team took pre-trained language models and fine-tuned them on datasets of human-written and machine-generated text, allowing the models to specialize in distinguishing the two.
- Multilingual Model Fine-tuning: Similar to the LM fine-tuning approach, but using multilingual models that can handle text in multiple languages.
The paper presents a comprehensive set of experiments, evaluating the performance of these methods on a diverse range of machine-generated text samples, including those created by large language models, machine translation systems, and other text generation techniques.
The results reveal significant differences in the competence of the various methods, with the LM and multilingual fine-tuning approaches generally outperforming the traditional shallow learning techniques. However, the paper also highlights the continued challenges in this area, emphasizing the need for further advancements to create highly discriminative and robust models for detecting machine-generated text.
Critical Analysis
The paper provides a thorough and well-designed evaluation of different techniques for distinguishing human-written and machine-generated text. However, it also acknowledges several limitations and areas for further research.
One key limitation is that the study focuses on a relatively narrow set of machine-generated text samples, primarily from large language models and translation systems. It would be valuable to expand the analysis to include a broader range of text generation techniques, such as those used in fake news detection or user-generated content scenarios.
Additionally, the paper notes that the performance of the fine-tuned models may be sensitive to the specific datasets used for training and the quality of the machine-generated samples. Further research is needed to understand how these factors influence the models' ability to generalize and maintain high accuracy in real-world applications.
Overall, this study provides a valuable benchmark for the current state of the art in machine-generated text detection and highlights the continued need for innovation in this important area of NLP research.
Conclusion
This paper offers a comprehensive evaluation of three distinct methods for distinguishing between human-written and machine-generated text, a critical challenge as language models become increasingly advanced. The results reveal significant differences in the performance of these approaches, underscoring the continued need for advancements in this crucial area of natural language processing.
By rigorously testing the capabilities of traditional shallow learning, Language Model fine-tuning, and Multilingual Model fine-tuning, the researchers have provided valuable insights that can guide future research towards building more robust and accurate models for detecting machine-generated content. This work lays the groundwork for continued progress in this important field, with significant implications for a wide range of applications, from fake news detection to user-generated content analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
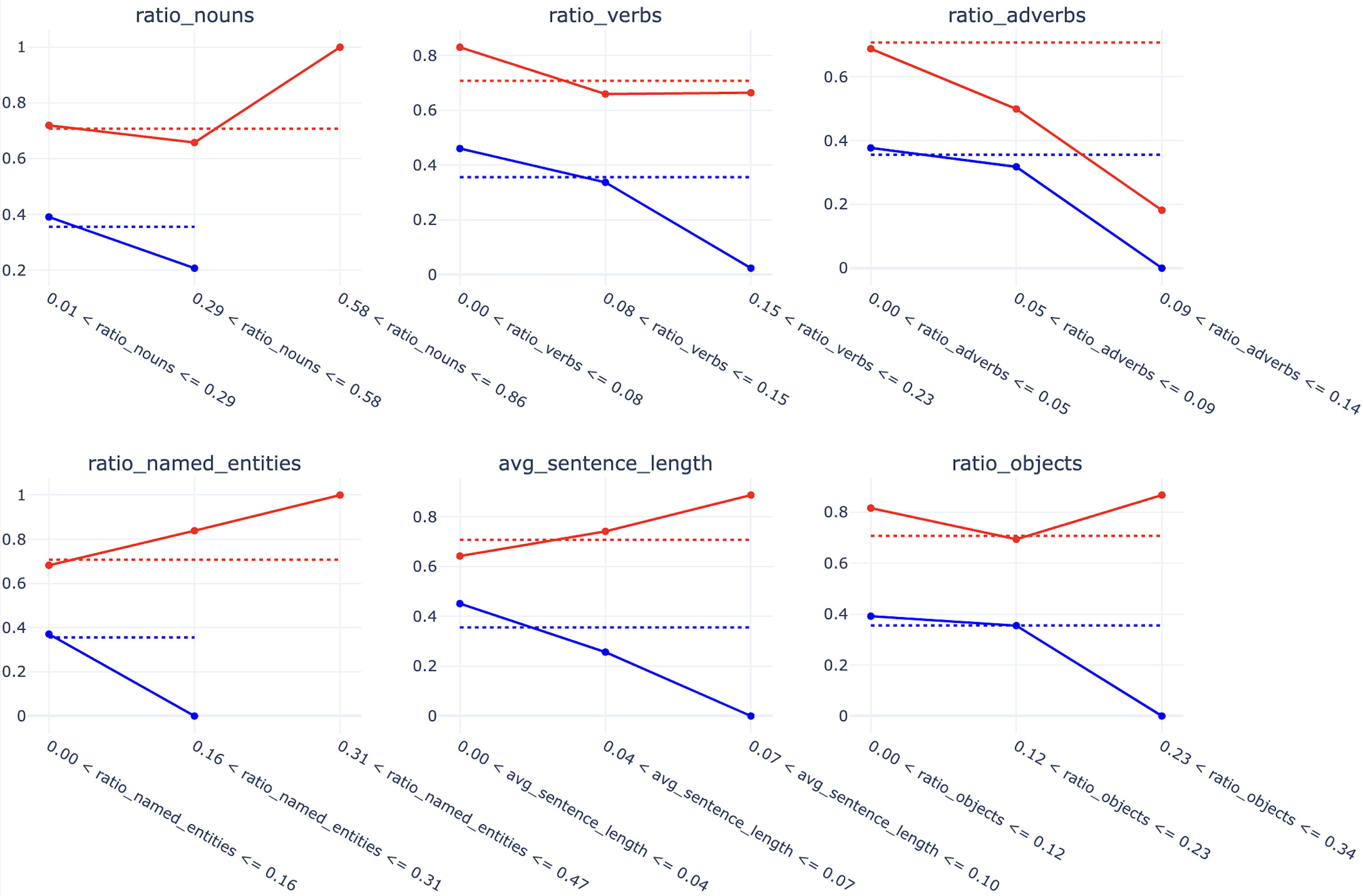
Exploring the Limitations of Detecting Machine-Generated Text
Jad Doughman, Osama Mohammed Afzal, Hawau Olamide Toyin, Shady Shehata, Preslav Nakov, Zeerak Talat
0
0
Recent improvements in the quality of the generations by large language models have spurred research into identifying machine-generated text. Systems proposed for the task often achieve high performance. However, humans and machines can produce text in different styles and in different domains, and it remains unclear whether machine generated-text detection models favour particular styles or domains. In this paper, we critically examine the classification performance for detecting machine-generated text by evaluating on texts with varying writing styles. We find that classifiers are highly sensitive to stylistic changes and differences in text complexity, and in some cases degrade entirely to random classifiers. We further find that detection systems are particularly susceptible to misclassify easy-to-read texts while they have high performance for complex texts.
6/18/2024
🔎
Deepfake Text Detection in the Wild
Yafu Li, Qintong Li, Leyang Cui, Wei Bi, Zhilin Wang, Longyue Wang, Linyi Yang, Shuming Shi, Yue Zhang
0
0
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
5/22/2024
🤖
Detecting Machine-Generated Texts: Not Just AI vs Humans and Explainability is Complicated
Jiazhou Ji, Ruizhe Li, Shujun Li, Jie Guo, Weidong Qiu, Zheng Huang, Chiyu Chen, Xiaoyu Jiang, Xinru Lu
0
0
As LLMs rapidly advance, increasing concerns arise regarding risks about actual authorship of texts we see online and in real world. The task of distinguishing LLM-authored texts is complicated by the nuanced and overlapping behaviors of both machines and humans. In this paper, we challenge the current practice of considering LLM-generated text detection a binary classification task of differentiating human from AI. Instead, we introduce a novel ternary text classification scheme, adding an undecided category for texts that could be attributed to either source, and we show that this new category is crucial to understand how to make the detection result more explainable to lay users. This research shifts the paradigm from merely classifying to explaining machine-generated texts, emphasizing need for detectors to provide clear and understandable explanations to users. Our study involves creating four new datasets comprised of texts from various LLMs and human authors. Based on new datasets, we performed binary classification tests to ascertain the most effective SOTA detection methods and identified SOTA LLMs capable of producing harder-to-detect texts. We constructed a new dataset of texts generated by two top-performing LLMs and human authors, and asked three human annotators to produce ternary labels with explanation notes. This dataset was used to investigate how three top-performing SOTA detectors behave in new ternary classification context. Our results highlight why undecided category is much needed from the viewpoint of explainability. Additionally, we conducted an analysis of explainability of the three best-performing detectors and the explanation notes of the human annotators, revealing insights about the complexity of explainable detection of machine-generated texts. Finally, we propose guidelines for developing future detection systems with improved explanatory power.
6/27/2024