Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
2304.01716
0
0
🧪
Abstract
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the textbf{dynamic objects} of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by off-the-shelf methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision.
Create account to get full access
Overview
- The paper addresses the challenge of synthesizing novel views from dynamic monocular videos, where a moving camera captures a scene with dynamic objects.
- Existing methods often rely on pre-processed 2D optical flow and depth maps, which can be inaccurate and ambiguous when lifting 2D information to 3D.
- The paper proposes an unsupervised approach that decouples the motion of dynamic objects into object motion and camera motion, using novel regularization techniques.
Plain English Explanation
The paper tackles the problem of creating new views from a video captured by a moving camera in a dynamic scene. This is a challenging task because the camera is moving and the objects in the scene are also moving, making it difficult to accurately model the 3D structure and motion.
Existing methods typically use pre-processed 2D information, like optical flow and depth maps, to help the neural network learn how to generate the new views. However, these pre-processed inputs can be inaccurate, and it's not always clear how to translate the 2D information into a 3D representation.
Instead, this paper takes an unsupervised approach. It breaks down the motion in the scene into two components: the motion of the camera and the motion of the dynamic objects. By separately modeling these two types of motion, the network can better learn the underlying 3D structure and motion of the scene, leading to higher-quality novel views as well as more accurate estimates of the scene's depth and flow.
The key ideas are:
- Enforcing surface consistency of the moving objects over time to ensure their 3D geometry is consistent.
- Regularizing the object appearances across different viewpoints to ensure consistency.
These novel regularization techniques help the network learn the complex 3D dynamics of the scene without relying on pre-processed 2D inputs, which can be error-prone.
Technical Explanation
The paper proposes an unsupervised approach to the problem of dynamic view synthesis from monocular videos. The key idea is to decouple the motion of dynamic objects into two components: object motion and camera motion.
The object motion is regularized using an unsupervised surface consistency constraint, which ensures that the 3D geometric surfaces of moving objects are consistent over time. The camera motion is regularized using a patch-based multi-view constraint, which enforces consistency in the appearance of objects across different viewpoints.
This fine-grained motion formulation helps the network learn the underlying 3D structure and dynamics of the scene, without relying on pre-processed 2D inputs like optical flow and depth maps. The network is able to produce not only high-quality novel views, but also more accurate estimates of the scene's depth and flow compared to existing methods that require extra supervision.
Critical Analysis
The paper presents a novel and promising approach to the challenging problem of dynamic view synthesis from monocular videos. The unsupervised regularization techniques are a key strength, as they avoid the potential inaccuracies and ambiguities associated with relying on pre-processed 2D inputs.
However, the paper does not provide a detailed analysis of the limitations of the proposed method. For example, it's unclear how the method would perform in scenarios with significant occlusions or highly complex object interactions. Additionally, the computational efficiency of the approach is not discussed, which could be an important consideration for real-world applications.
Further research could explore ways to combine the unsupervised motion modeling with other sources of information, such as semantic segmentation or object detection, to further improve the accuracy and robustness of the dynamic view synthesis.
Overall, the paper presents a compelling and innovative approach that could have significant implications for applications such as augmented reality, robotics, and film production. However, additional research and analysis would be needed to fully understand the strengths, limitations, and practical potential of the proposed method.
Conclusion
This paper addresses the challenging problem of synthesizing novel views from dynamic monocular videos captured by a moving camera. By decoupling the motion of dynamic objects into object motion and camera motion, and regularizing these components using unsupervised surface consistency and patch-based multi-view constraints, the proposed approach is able to produce high-quality novel views as well as accurate estimates of scene depth and flow, without relying on pre-processed 2D inputs.
The unsupervised nature of the method is a key strength, as it avoids the potential issues associated with using inaccurate or ambiguous 2D supervision. While the paper does not provide a detailed analysis of the limitations, the proposed techniques represent a significant advancement in the field of dynamic view synthesis and could have important implications for a wide range of applications, from augmented reality to robotics and film production.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
DreamScene4D: Dynamic Multi-Object Scene Generation from Monocular Videos
Wen-Hsuan Chu, Lei Ke, Katerina Fragkiadaki
0
0
View-predictive generative models provide strong priors for lifting object-centric images and videos into 3D and 4D through rendering and score distillation objectives. A question then remains: what about lifting complete multi-object dynamic scenes? There are two challenges in this direction: First, rendering error gradients are often insufficient to recover fast object motion, and second, view predictive generative models work much better for objects than whole scenes, so, score distillation objectives cannot currently be applied at the scene level directly. We present DreamScene4D, the first approach to generate 3D dynamic scenes of multiple objects from monocular videos via 360-degree novel view synthesis. Our key insight is a decompose-recompose approach that factorizes the video scene into the background and object tracks, while also factorizing object motion into 3 components: object-centric deformation, object-to-world-frame transformation, and camera motion. Such decomposition permits rendering error gradients and object view-predictive models to recover object 3D completions and deformations while bounding box tracks guide the large object movements in the scene. We show extensive results on challenging DAVIS, Kubric, and self-captured videos with quantitative comparisons and a user preference study. Besides 4D scene generation, DreamScene4D obtains accurate 2D persistent point track by projecting the inferred 3D trajectories to 2D. We will release our code and hope our work will stimulate more research on fine-grained 4D understanding from videos.
5/24/2024
💬
Generative Camera Dolly: Extreme Monocular Dynamic Novel View Synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, Carl Vondrick
0
0
Accurate reconstruction of complex dynamic scenes from just a single viewpoint continues to be a challenging task in computer vision. Current dynamic novel view synthesis methods typically require videos from many different camera viewpoints, necessitating careful recording setups, and significantly restricting their utility in the wild as well as in terms of embodied AI applications. In this paper, we propose $textbf{GCD}$, a controllable monocular dynamic view synthesis pipeline that leverages large-scale diffusion priors to, given a video of any scene, generate a synchronous video from any other chosen perspective, conditioned on a set of relative camera pose parameters. Our model does not require depth as input, and does not explicitly model 3D scene geometry, instead performing end-to-end video-to-video translation in order to achieve its goal efficiently. Despite being trained on synthetic multi-view video data only, zero-shot real-world generalization experiments show promising results in multiple domains, including robotics, object permanence, and driving environments. We believe our framework can potentially unlock powerful applications in rich dynamic scene understanding, perception for robotics, and interactive 3D video viewing experiences for virtual reality.
5/24/2024
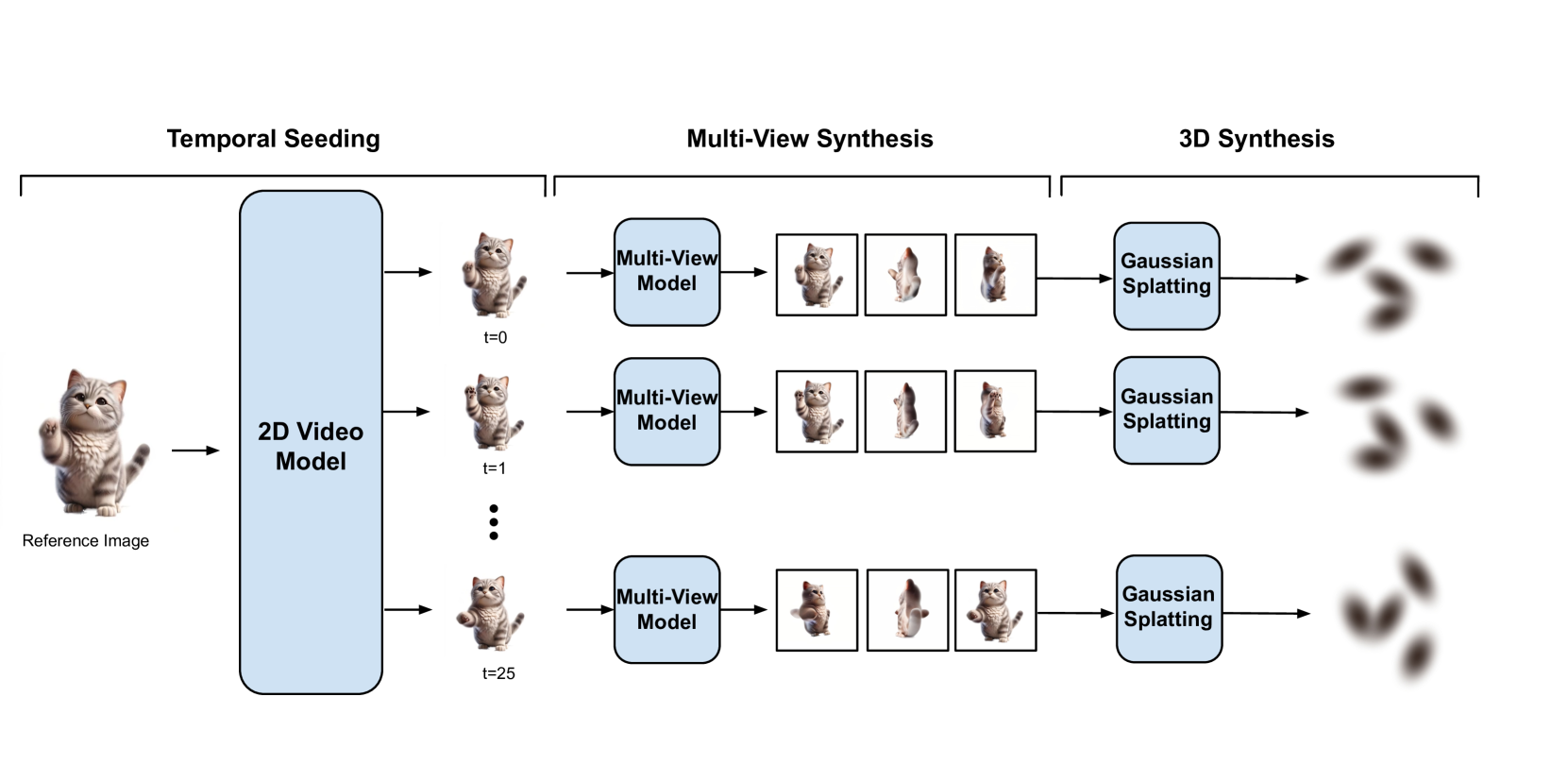
Vid3D: Synthesis of Dynamic 3D Scenes using 2D Video Diffusion
Rishab Parthasarathy, Zack Ankner, Aaron Gokaslan
0
0
A recent frontier in computer vision has been the task of 3D video generation, which consists of generating a time-varying 3D representation of a scene. To generate dynamic 3D scenes, current methods explicitly model 3D temporal dynamics by jointly optimizing for consistency across both time and views of the scene. In this paper, we instead investigate whether it is necessary to explicitly enforce multiview consistency over time, as current approaches do, or if it is sufficient for a model to generate 3D representations of each timestep independently. We hence propose a model, Vid3D, that leverages 2D video diffusion to generate 3D videos by first generating a 2D seed of the video's temporal dynamics and then independently generating a 3D representation for each timestep in the seed video. We evaluate Vid3D against two state-of-the-art 3D video generation methods and find that Vid3D is achieves comparable results despite not explicitly modeling 3D temporal dynamics. We further ablate how the quality of Vid3D depends on the number of views generated per frame. While we observe some degradation with fewer views, performance degradation remains minor. Our results thus suggest that 3D temporal knowledge may not be necessary to generate high-quality dynamic 3D scenes, potentially enabling simpler generative algorithms for this task.
6/18/2024

Modeling Ambient Scene Dynamics for Free-view Synthesis
Meng-Li Shih, Jia-Bin Huang, Changil Kim, Rajvi Shah, Johannes Kopf, Chen Gao
0
0
We introduce a novel method for dynamic free-view synthesis of an ambient scenes from a monocular capture bringing a immersive quality to the viewing experience. Our method builds upon the recent advancements in 3D Gaussian Splatting (3DGS) that can faithfully reconstruct complex static scenes. Previous attempts to extend 3DGS to represent dynamics have been confined to bounded scenes or require multi-camera captures, and often fail to generalize to unseen motions, limiting their practical application. Our approach overcomes these constraints by leveraging the periodicity of ambient motions to learn the motion trajectory model, coupled with careful regularization. We also propose important practical strategies to improve the visual quality of the baseline 3DGS static reconstructions and to improve memory efficiency critical for GPU-memory intensive learning. We demonstrate high-quality photorealistic novel view synthesis of several ambient natural scenes with intricate textures and fine structural elements.
6/14/2024