Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce

0

Sign in to get full access
Overview
- This paper presents a deep bag-of-words model for efficient and interpretable relevance modeling in the context of Chinese e-commerce.
- The proposed model leverages a deep neural network architecture to capture the semantic information of product titles and user queries, enabling accurate relevance estimation.
- The model is designed to be efficient and interpretable, providing insights into the key factors contributing to relevance judgments.
Plain English Explanation
In the world of e-commerce, determining the relevance of products to a user's search query is a crucial task. This paper introduces a new approach called the "deep bag-of-words model" that aims to improve the accuracy and interpretability of this process, specifically for the Chinese e-commerce market.
The key idea is to use a deep neural network to analyze the semantic information contained in both the product titles and the user's search queries. By identifying the important words and their relationships, the model can better estimate how relevant a product is to a given search. This builds on previous research in areas like ,[object Object],, ,[object Object],, and ,[object Object].
What makes this model unique is its focus on efficiency and interpretability. Rather than relying on complex black-box algorithms, the deep bag-of-words approach is designed to be easy to understand and explain. This allows e-commerce companies to gain insights into why certain products are deemed more relevant, which can help them improve their search algorithms and better serve their customers. The model's efficiency and interpretability also align with recent research on ,[object Object], and ,[object Object].
Technical Explanation
The deep bag-of-words model consists of several key components:
-
Embedding Layer: The first step is to convert the product titles and user queries into numerical representations, known as embeddings. This allows the model to understand the semantic relationships between the words.
-
Attention Mechanism: Next, the model uses an attention mechanism to identify the most important words in the input text. This helps the model focus on the most relevant information when making relevance judgments.
-
Relevance Estimation: The final step is to use a deep neural network to estimate the relevance of a product to a given search query. The model takes the embedded text and the attention weights as input, and outputs a relevance score.
The researchers evaluated the deep bag-of-words model on a large e-commerce dataset from China, and compared its performance to several baseline models. Their results showed that the proposed model outperformed the competitors in terms of both accuracy and interpretability, making it a promising approach for real-world e-commerce applications.
Critical Analysis
The deep bag-of-words model presented in this paper is a novel and interesting approach to relevance modeling in the context of Chinese e-commerce. The focus on efficiency and interpretability is particularly commendable, as it addresses an important need in the industry.
However, the paper does not provide a comprehensive evaluation of the model's limitations or potential drawbacks. For example, the researchers do not discuss how the model might perform on more complex or ambiguous search queries, or how it might scale to larger product catalogs.
Additionally, while the model builds on previous research in areas like robust interaction-based relevance modeling and leveraging large language models, the paper does not provide a thorough discussion of how the proposed approach differs from or extends these existing techniques. A more detailed comparison could help readers better understand the unique contributions of this work.
Overall, the deep bag-of-words model is a compelling and potentially impactful contribution to the field of e-commerce relevance modeling. However, further research and evaluation would be necessary to fully understand its strengths, limitations, and practical implications.
Conclusion
This paper presents a deep bag-of-words model for efficient and interpretable relevance modeling in Chinese e-commerce. The proposed approach leverages deep neural networks to capture the semantic information of product titles and user queries, enabling accurate relevance estimation.
The key advantages of the deep bag-of-words model are its efficiency and interpretability, which can provide valuable insights into the factors driving relevance judgments. This aligns with the growing demand for transparent and explainable AI systems in e-commerce and other domains.
[While the model builds on previous research in areas like robust interaction-based relevance modeling and multi-word term embeddings, its unique focus on efficiency and interpretability makes it a promising contribution to the field](https://aimodels.fyi/papers/arxiv/robust-interaction-based-relevance-modeling-online-e, https://aimodels.fyi/papers/arxiv/multi-word-term-embeddings-improve-lexical-product). Further research and evaluation will be necessary to fully understand the model's strengths, limitations, and potential real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
Zhe Lin, Jiwei Tan, Dan Ou, Xi Chen, Shaowei Yao, Bo Zheng
Text relevance or text matching of query and product is an essential technique for the e-commerce search system to ensure that the displayed products can match the intent of the query. Many studies focus on improving the performance of the relevance model in search system. Recently, pre-trained language models like BERT have achieved promising performance on the text relevance task. While these models perform well on the offline test dataset, there are still obstacles to deploy the pre-trained language model to the online system as their high latency. The two-tower model is extensively employed in industrial scenarios, owing to its ability to harmonize performance with computational efficiency. Regrettably, such models present an opaque ``black box'' nature, which prevents developers from making special optimizations. In this paper, we raise deep Bag-of-Words (DeepBoW) model, an efficient and interpretable relevance architecture for Chinese e-commerce. Our approach proposes to encode the query and the product into the sparse BoW representation, which is a set of word-weight pairs. The weight means the important or the relevant score between the corresponding word and the raw text. The relevance score is measured by the accumulation of the matched word between the sparse BoW representation of the query and the product. Compared to popular dense distributed representation that usually suffers from the drawback of black-box, the most advantage of the proposed representation model is highly explainable and interventionable, which is a superior advantage to the deployment and operation of online search engines. Moreover, the online efficiency of the proposed model is even better than the most efficient inner product form of dense representation ...
Read more7/15/2024
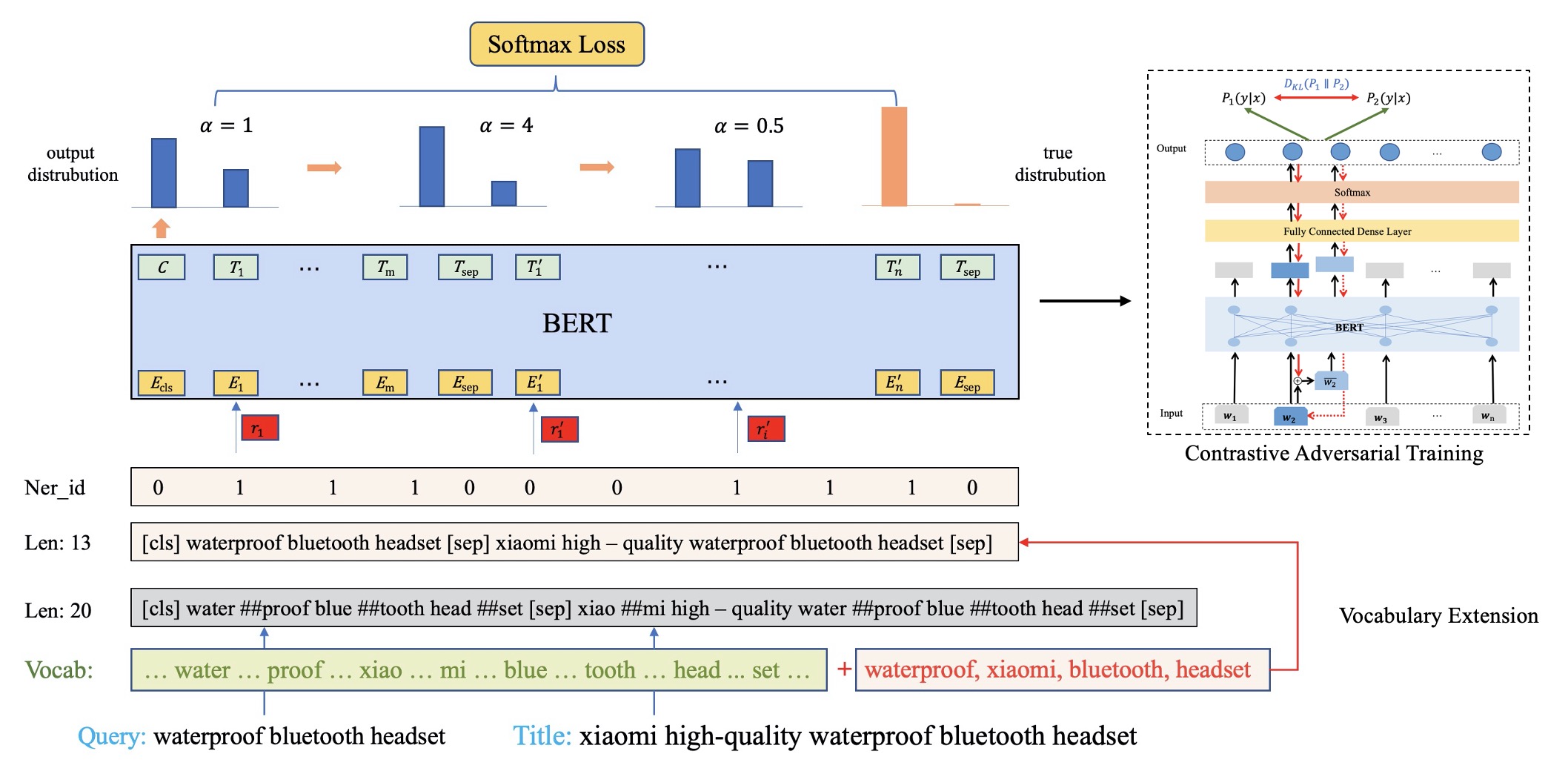
0
Robust Interaction-based Relevance Modeling for Online E-Commerce and LLM-based Retrieval
Ben Chen, Huangyu Dai, Xiang Ma, Wen Jiang, Wei Ning
Semantic relevance calculation is crucial for e-commerce search engines, as it ensures that the items selected closely align with customer intent. Inadequate attention to this aspect can detrimentally affect user experience and engagement. Traditional text-matching techniques are prevalent but often fail to capture the nuances of search intent accurately, so neural networks now have become a preferred solution to processing such complex text matching. Existing methods predominantly employ representation-based architectures, which strike a balance between high traffic capacity and low latency. However, they exhibit significant shortcomings in generalization and robustness when compared to interaction-based architectures. In this work, we introduce a robust interaction-based modeling paradigm to address these shortcomings. It encompasses 1) a dynamic length representation scheme for expedited inference, 2) a professional terms recognition method to identify subjects and core attributes from complex sentence structures, and 3) a contrastive adversarial training protocol to bolster the model's robustness and matching capabilities. Extensive offline evaluations demonstrate the superior robustness and effectiveness of our approach, and online A/B testing confirms its ability to improve relevance in the same exposure position, resulting in more clicks and conversions. To the best of our knowledge, this method is the first interaction-based approach for large e-commerce search relevance calculation. Notably, we have deployed it for the entire search traffic on alibaba.com, the largest B2B e-commerce platform in the world.
Read more6/5/2024
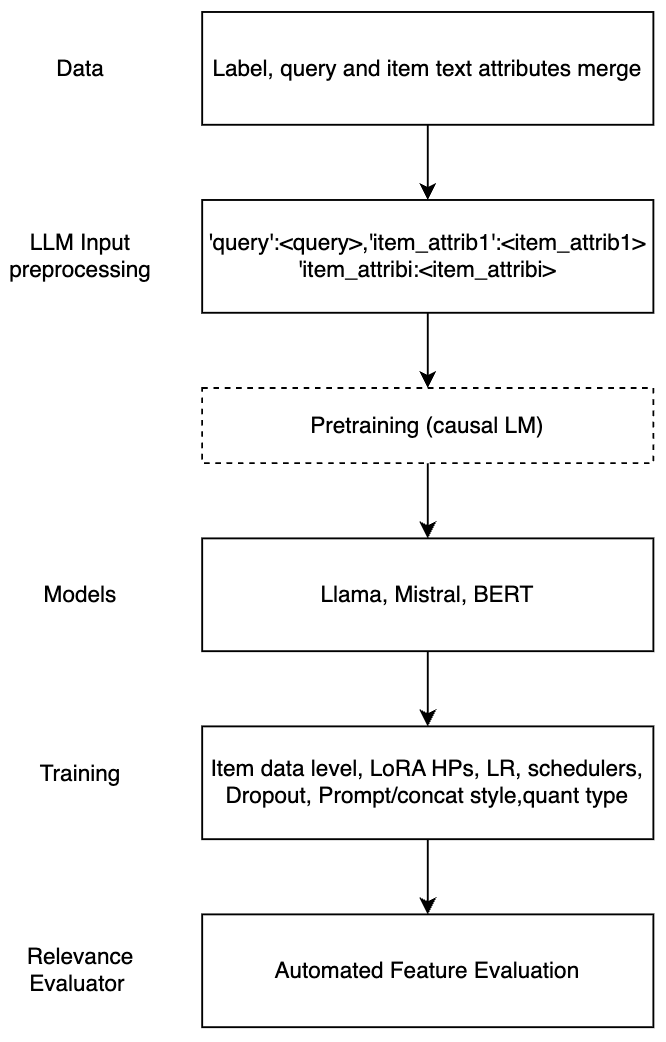
0
Large Language Models for Relevance Judgment in Product Search
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, Ciya Liao
High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
Read more7/18/2024
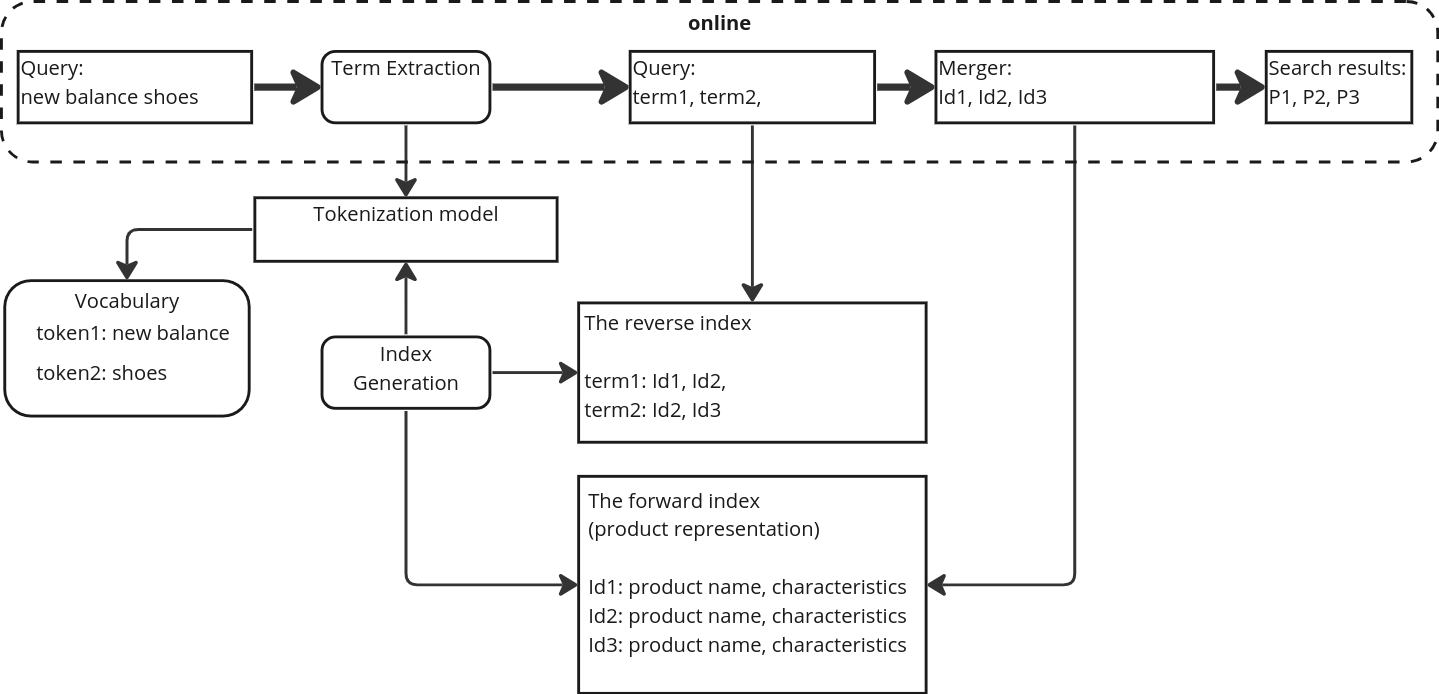
0
Multi-word Term Embeddings Improve Lexical Product Retrieval
Viktor Shcherbakov, Fedor Krasnov
Product search is uniquely different from search for documents, Internet resources or vacancies, therefore it requires the development of specialized search systems. The present work describes the H1 embdedding model, designed for an offline term indexing of product descriptions at e-commerce platforms. The model is compared to other state-of-the-art (SoTA) embedding models within a framework of hybrid product search system that incorporates the advantages of lexical methods for product retrieval and semantic embedding-based methods. We propose an approach to building semantically rich term vocabularies for search indexes. Compared to other production semantic models, H1 paired with the proposed approach stands out due to its ability to process multi-word product terms as one token. As an example, for search queries new balance shoes, gloria jeans kids wear brand entity will be represented as one token - new balance, gloria jeans. This results in an increased precision of the system without affecting the recall. The hybrid search system with proposed model scores mAP@12 = 56.1% and R@1k = 86.6% on the WANDS public dataset, beating other SoTA analogues.
Read more6/4/2024