Deep Reinforcement Learning-based Quadcopter Controller: A Practical Approach and Experiments

0
Sign in to get full access
Overview
- This paper presents a practical approach to developing a deep reinforcement learning-based controller for a quadcopter drone.
- The researchers conducted experiments to evaluate the performance of their controller in various scenarios, including trajectory tracking, hovering, and collision avoidance.
- The proposed method integrates deep reinforcement learning techniques with robust low-level control, aiming to achieve reliable and efficient quadcopter control.
Plain English Explanation
The paper describes a new way to control a quadcopter drone, using a machine learning technique called deep reinforcement learning. Quadcopters are small drones with four propellers that can fly in different directions. Controlling a quadcopter can be challenging because it needs to be able to hover, track a specific path, and avoid collisions, all while maintaining stability.
The researchers developed a deep reinforcement learning-based controller that can learn how to control the quadcopter through trial and error, rather than relying on pre-programmed rules. This allows the controller to adapt to different situations and learn to perform complex maneuvers. The team also integrated this deep learning controller with a more traditional, low-level control system to ensure the quadcopter remains stable and responsive.
The researchers then tested their controller in a variety of scenarios, such as having the quadcopter follow a specified path, hover in place, and avoid obstacles. The results showed that the deep reinforcement learning-based controller was able to successfully perform these tasks, demonstrating the practical application of this approach for controlling quadcopters.
Technical Explanation
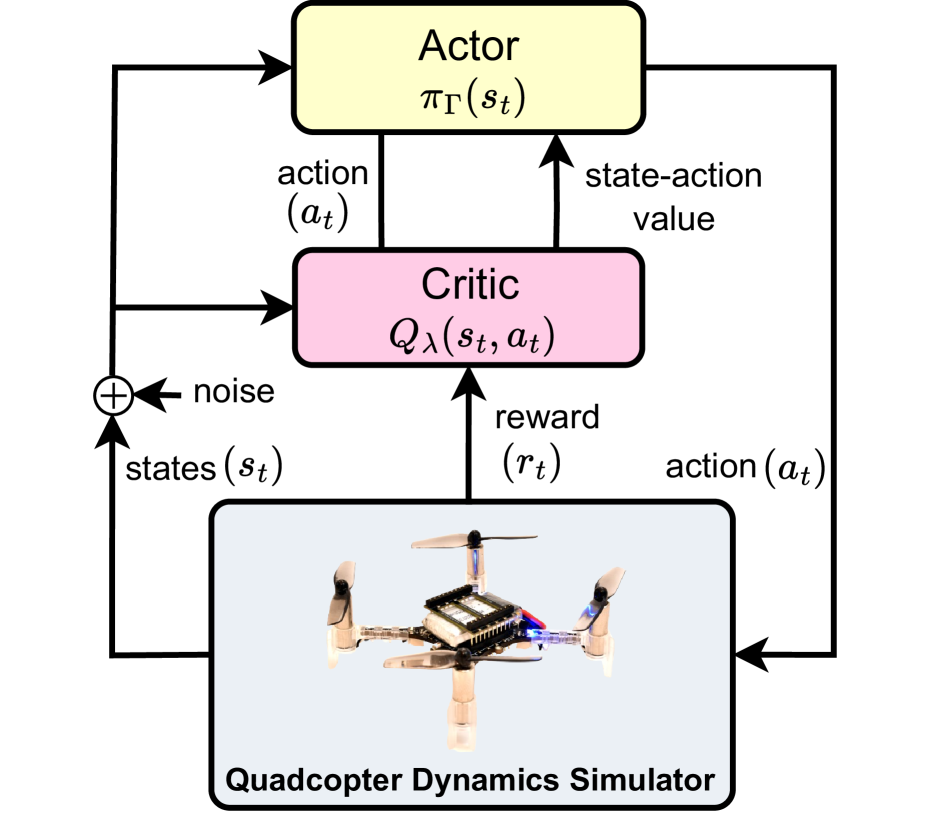
The researchers developed a deep reinforcement learning-based quadcopter controller that integrates with a robust low-level control system. This builds on previous work in areas like learning to fly in seconds, reinforcement learning-based autonomous multi-rotor landing, collision avoidance and navigation for quadrotor swarms, and adaptive reinforcement learning for robot control.
The deep reinforcement learning controller was trained in simulation to learn optimal control policies for tasks like trajectory tracking, hovering, and collision avoidance. This integrated approach of combining deep RL with robust low-level control has shown promise for improving the reliability and efficiency of quadcopter control.
In the experiments, the researchers evaluated the performance of their deep RL-based quadcopter controller in various scenarios, including trajectory tracking, hovering, and collision avoidance. The results demonstrated the controller's ability to successfully perform these tasks, highlighting the practical potential of this approach.
Critical Analysis
The paper provides a thorough evaluation of the deep reinforcement learning-based quadcopter controller, addressing key challenges such as trajectory tracking, hovering, and collision avoidance. However, the authors acknowledge that further research is needed to improve the controller's robustness and generalization capabilities, particularly when dealing with real-world uncertainties and disturbances.
Additionally, the training and simulation environment used in the experiments may not fully capture the complexities of real-world quadcopter operation, such as wind gusts, sensor noise, and model inaccuracies. Exploring the performance of the controller in more realistic conditions would be a valuable area for future work.
It would also be interesting to see how the deep RL-based controller compares to other state-of-the-art quadcopter control approaches in terms of task performance, computational efficiency, and ease of deployment.
Conclusion
This paper presents a practical deep reinforcement learning-based approach for quadcopter control, demonstrating its potential for reliable and efficient control in various scenarios. The integration of deep RL with robust low-level control shows promise for improving the autonomy and adaptability of quadcopter systems.
The successful experimental results highlight the applicability of this approach, although further research is needed to address its limitations and explore its performance in more realistic environments. Overall, this work contributes to the ongoing efforts to develop advanced control systems for quadcopters and other autonomous aerial vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!