Deep Reward Supervisions for Tuning Text-to-Image Diffusion Models
2405.00760
0
1
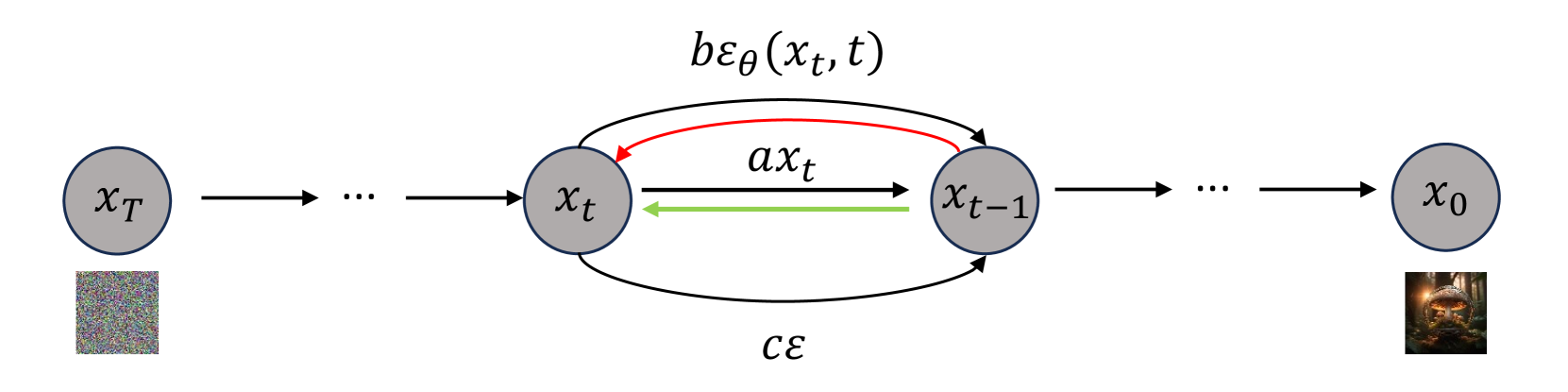
Abstract
Optimizing a text-to-image diffusion model with a given reward function is an important but underexplored research area. In this study, we propose Deep Reward Tuning (DRTune), an algorithm that directly supervises the final output image of a text-to-image diffusion model and back-propagates through the iterative sampling process to the input noise. We find that training earlier steps in the sampling process is crucial for low-level rewards, and deep supervision can be achieved efficiently and effectively by stopping the gradient of the denoising network input. DRTune is extensively evaluated on various reward models. It consistently outperforms other algorithms, particularly for low-level control signals, where all shallow supervision methods fail. Additionally, we fine-tune Stable Diffusion XL 1.0 (SDXL 1.0) model via DRTune to optimize Human Preference Score v2.1, resulting in the Favorable Diffusion XL 1.0 (FDXL 1.0) model. FDXL 1.0 significantly enhances image quality compared to SDXL 1.0 and reaches comparable quality compared with Midjourney v5.2.
Create account to get full access
Overview
- This paper explores a novel approach for tuning text-to-image diffusion models using "deep reward supervisions" - a technique that leverages human feedback and preferences to guide the model's learning process.
- The key idea is to train a reward model that can provide rich, contextual rewards to the diffusion model during fine-tuning, leading to images that better align with human preferences.
- The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing improvements in image quality and semantic alignment compared to baselines.
Plain English Explanation
The paper discusses a new way to fine-tune text-to-image diffusion models, which are AI systems that can generate images from textual descriptions. The main challenge with these models is ensuring the generated images align well with what humans actually want to see.
The researchers' solution is to train a separate "reward model" that can provide detailed feedback to the diffusion model during the fine-tuning process. This reward model learns to assess how well the generated images match human preferences, and then uses that information to guide the diffusion model's learning.
The key idea is that by incorporating this rich, contextual feedback, the diffusion model can learn to generate images that are not just technically accurate, but also visually appealing and semantically aligned with the original text prompt. The authors show that this approach leads to significant improvements in image quality and relevance compared to standard fine-tuning methods.
This work is important because it highlights the value of incorporating human preferences and feedback into the training of AI systems that generate creative content like images. By learning to optimize for what humans actually want, these models can produce results that are more useful and engaging.
Technical Explanation
The paper introduces a novel framework called "Deep Reward Supervisions" (DRS) for fine-tuning text-to-image diffusion models. The core idea is to train a separate "reward model" in parallel with the diffusion model, which learns to assess the quality and relevance of the generated images based on human preferences.
During the fine-tuning stage, the reward model provides detailed, contextual rewards to the diffusion model, guiding it to generate images that better align with the target distribution. This is in contrast to standard fine-tuning approaches that rely on simple, generic loss functions.
The authors demonstrate the DRS framework on several benchmark datasets, including DiscFFusion, Pixel-Wise RL, and Confidence-Aware Reward Optimization. They show that their approach leads to significant improvements in image quality and semantic alignment compared to baselines, as measured by both qualitative and quantitative metrics.
The key technical insights include:
- Architecture design for the reward model, which takes into account both the generated image and the text prompt
- Training procedure that jointly optimizes the diffusion model and reward model
- Strategies for effectively incorporating the reward signal into the diffusion model's learning process
Overall, the DRS framework represents an important step towards developing text-to-image models that can better capture and optimize for human preferences and creative sensibilities.
Critical Analysis
The paper presents a well-designed and thorough study on the use of deep reward supervisions for fine-tuning text-to-image diffusion models. The authors have clearly put a lot of thought into the technical details of their approach and have done a commendable job of evaluating it on multiple benchmark datasets.
One potential limitation of the work is that it relies on having access to human-provided ratings or feedback to train the reward model. In real-world settings, collecting such data can be challenging and resource-intensive. It would be interesting to see if the authors' techniques could be adapted to work with more widely available sources of human preferences, such as image-text pairs from the web.
Additionally, the paper does not delve deeply into the potential biases or limitations of the reward model itself. As with any AI system that aims to optimize for human preferences, there is a risk of amplifying existing biases or producing results that are skewed towards the perspectives of the specific individuals or groups involved in the data collection and annotation process.
Further research could explore techniques for making the reward model more robust and inclusive, perhaps by incorporating diverse sources of human feedback or by developing methods for assessing and mitigating biases in the reward signal.
Overall, the work represents an important contribution to the field of text-to-image generation, and the authors' emphasis on aligning AI systems with human preferences is a valuable direction for the broader machine learning community to explore.
Conclusion
This paper presents a novel approach called "Deep Reward Supervisions" for fine-tuning text-to-image diffusion models. The key innovation is the use of a separate reward model that can provide rich, contextual feedback to the diffusion model during the learning process, guiding it to generate images that better align with human preferences.
The authors demonstrate the effectiveness of their approach on several benchmark datasets, showing significant improvements in image quality and semantic alignment compared to standard fine-tuning techniques. This work highlights the importance of incorporating human feedback and preferences into the training of AI systems that generate creative content, and it represents an important step towards developing text-to-image models that can better capture and optimize for human sensibilities.
While the current approach relies on the availability of human-provided ratings or feedback, future research could explore ways to make the system more robust and inclusive, perhaps by drawing on a wider range of human preferences or by developing more sophisticated techniques for mitigating biases in the reward signal.
Overall, this paper makes a valuable contribution to the field of text-to-image generation and serves as a useful example of how human-AI collaboration can be leveraged to create more effective and aligned AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Directly Fine-Tuning Diffusion Models on Differentiable Rewards
Kevin Clark, Paul Vicol, Kevin Swersky, David J Fleet
0
0
We present Direct Reward Fine-Tuning (DRaFT), a simple and effective method for fine-tuning diffusion models to maximize differentiable reward functions, such as scores from human preference models. We first show that it is possible to backpropagate the reward function gradient through the full sampling procedure, and that doing so achieves strong performance on a variety of rewards, outperforming reinforcement learning-based approaches. We then propose more efficient variants of DRaFT: DRaFT-K, which truncates backpropagation to only the last K steps of sampling, and DRaFT-LV, which obtains lower-variance gradient estimates for the case when K=1. We show that our methods work well for a variety of reward functions and can be used to substantially improve the aesthetic quality of images generated by Stable Diffusion 1.4. Finally, we draw connections between our approach and prior work, providing a unifying perspective on the design space of gradient-based fine-tuning algorithms.
6/24/2024

Tuning-Free Alignment of Diffusion Models with Direct Noise Optimization
Zhiwei Tang, Jiangweizhi Peng, Jiasheng Tang, Mingyi Hong, Fan Wang, Tsung-Hui Chang
0
0
In this work, we focus on the alignment problem of diffusion models with a continuous reward function, which represents specific objectives for downstream tasks, such as improving human preference. The central goal of the alignment problem is to adjust the distribution learned by diffusion models such that the generated samples maximize the target reward function. We propose a novel alignment approach, named Direct Noise Optimization (DNO), that optimizes the injected noise during the sampling process of diffusion models. By design, DNO is tuning-free and prompt-agnostic, as the alignment occurs in an online fashion during generation. We rigorously study the theoretical properties of DNO and also propose variants to deal with non-differentiable reward functions. Furthermore, we identify that naive implementation of DNO occasionally suffers from the out-of-distribution reward hacking problem, where optimized samples have high rewards but are no longer in the support of the pretrained distribution. To remedy this issue, we leverage classical high-dimensional statistics theory and propose to augment the DNO loss with certain probability regularization. We conduct extensive experiments on several popular reward functions trained on human feedback data and demonstrate that the proposed DNO approach achieves state-of-the-art reward scores as well as high image quality, all within a reasonable time budget for generation.
5/30/2024
🔗
A Dense Reward View on Aligning Text-to-Image Diffusion with Preference
Shentao Yang, Tianqi Chen, Mingyuan Zhou
0
0
Aligning text-to-image diffusion model (T2I) with preference has been gaining increasing research attention. While prior works exist on directly optimizing T2I by preference data, these methods are developed under the bandit assumption of a latent reward on the entire diffusion reverse chain, while ignoring the sequential nature of the generation process. This may harm the efficacy and efficiency of preference alignment. In this paper, we take on a finer dense reward perspective and derive a tractable alignment objective that emphasizes the initial steps of the T2I reverse chain. In particular, we introduce temporal discounting into DPO-style explicit-reward-free objectives, to break the temporal symmetry therein and suit the T2I generation hierarchy. In experiments on single and multiple prompt generation, our method is competitive with strong relevant baselines, both quantitatively and qualitatively. Further investigations are conducted to illustrate the insight of our approach.
5/14/2024
👀
Discffusion: Discriminative Diffusion Models as Few-shot Vision and Language Learners
Xuehai He, Weixi Feng, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, William Yang Wang, Xin Eric Wang
0
0
Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach mainly uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via efficient attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
4/26/2024