Pixel-wise RL on Diffusion Models: Reinforcement Learning from Rich Feedback
2404.04356
0
0

Abstract
Latent diffusion models are the state-of-the-art for synthetic image generation. To align these models with human preferences, training the models using reinforcement learning on human feedback is crucial. Black et. al 2024 introduced denoising diffusion policy optimisation (DDPO), which accounts for the iterative denoising nature of the generation by modelling it as a Markov chain with a final reward. As the reward is a single value that determines the model's performance on the entire image, the model has to navigate a very sparse reward landscape and so requires a large sample count. In this work, we extend the DDPO by presenting the Pixel-wise Policy Optimisation (PXPO) algorithm, which can take feedback for each pixel, providing a more nuanced reward to the model.
Get summaries of the top AI research delivered straight to your inbox:
Method
Overview
- The paper proposes a method for training diffusion models using reinforcement learning (RL) from rich feedback, such as human preferences or reward functions.
- The key idea is to directly optimize the diffusion model's parameters to generate images that maximize the RL reward, rather than relying on a separate RL agent.
- This "pixel-wise RL" approach allows the diffusion model to learn useful representations and generate high-quality images that align with the desired objectives.
Plain English Explanation
The researchers have developed a new way to train diffusion models, which are a type of AI system that can generate images. Typically, diffusion models are trained using a self-supervised approach, where the model learns to reconstruct images from gradually added noise. In this paper, the researchers show that you can also train diffusion models using reinforcement learning (RL) - a technique where the model learns by receiving rewards for generating desirable outputs.
The key insight is that you can directly optimize the diffusion model's parameters to generate images that maximize an RL reward, rather than having a separate RL agent control the diffusion process. This "pixel-wise RL" approach allows the diffusion model to learn useful representations and generate high-quality images that closely match the desired objectives, such as human preferences or specific reward functions.
This is an interesting approach because it combines the strengths of diffusion models (their ability to generate high-fidelity images) with the flexibility of RL (the ability to directly optimize for desired objectives). The researchers demonstrate the effectiveness of their method on several image generation tasks, showing that it can outperform traditional diffusion models and RL-based approaches.
Technical Explanation
The paper introduces a novel method for training diffusion models using reinforcement learning (RL) from rich feedback, such as human preferences or reward functions. The key idea is to directly optimize the diffusion model's parameters to generate images that maximize the RL reward, rather than relying on a separate RL agent to control the diffusion process.
The authors formulate the problem as a pixel-wise RL objective, where the diffusion model's output is treated as the "action" taken by the agent, and the RL reward is computed based on the generated image. This allows the diffusion model to learn useful representations and generate high-quality images that closely align with the desired objectives.
The proposed method consists of two main components:
-
Diffusion Model: The authors use a standard latent diffusion model [https://aimodels.fyi/papers/arxiv/missing-u-efficient-diffusion-models] as the base generator. The diffusion model is trained to generate images that match the input distribution, using a self-supervised approach.
-
Pixel-wise RL: The diffusion model's parameters are further optimized using a pixel-wise RL objective. The model is trained to generate images that maximize the provided RL reward, which can be a human preference function, a task-specific reward, or a combination of both [https://aimodels.fyi/papers/arxiv/rl-consistency-models-faster-reward-guided-text, https://aimodels.fyi/papers/arxiv/direct-preference-optimization-video-large-multimodal-models].
The authors demonstrate the effectiveness of their method on several image generation tasks, including generating images that match human preferences and optimizing for specific reward functions. They show that their pixel-wise RL approach outperforms traditional diffusion models and RL-based image generation methods.
Critical Analysis
The paper presents a compelling approach for training diffusion models using reinforcement learning, which allows the model to directly optimize for desired objectives. The authors' pixel-wise RL formulation is a clever way to integrate the strengths of diffusion models and RL, and the results suggest that this combined approach can lead to significant performance improvements.
However, the paper does not discuss potential limitations or caveats of the proposed method. For example, it is not clear how the method scales to more complex RL rewards or preferences, or how the performance might be affected by the choice of the base diffusion model architecture [https://aimodels.fyi/papers/arxiv/3d-diffusion-policy-generalizable-visuomotor-policy-learning].
Additionally, the paper does not address potential biases or safety concerns that may arise when training diffusion models using RL, particularly when the reward function is based on human preferences [https://aimodels.fyi/papers/arxiv/addp-learning-general-representations-image-recognition-generation]. Further research may be needed to understand the implications and limitations of this approach.
Conclusion
The paper presents a novel method for training diffusion models using pixel-wise reinforcement learning, which allows the model to directly optimize for desired objectives such as human preferences or task-specific rewards. This combined approach leverages the strengths of diffusion models and RL, leading to significant performance improvements in image generation tasks.
The proposed method is an interesting and promising development in the field of generative AI, as it opens up new possibilities for training highly capable image generators that can be tailored to specific user preferences or objectives. While the paper does not address potential limitations or caveats, the results suggest that this pixel-wise RL approach is a valuable contribution to the ongoing research in diffusion models and reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DPO Meets PPO: Reinforced Token Optimization for RLHF
Han Zhong, Guhao Feng, Wei Xiong, Li Zhao, Di He, Jiang Bian, Liwei Wang
0
0
In the classical Reinforcement Learning from Human Feedback (RLHF) framework, Proximal Policy Optimization (PPO) is employed to learn from sparse, sentence-level rewards -- a challenging scenario in traditional deep reinforcement learning. Despite the great successes of PPO in the alignment of state-of-the-art closed-source large language models (LLMs), its open-source implementation is still largely sub-optimal, as widely reported by numerous research studies. To address these issues, we introduce a framework that models RLHF problems as a Markov decision process (MDP), enabling the capture of fine-grained token-wise information. Furthermore, we provide theoretical insights that demonstrate the superiority of our MDP framework over the previous sentence-level bandit formulation. Under this framework, we introduce an algorithm, dubbed as Reinforced Token Optimization (texttt{RTO}), which learns the token-wise reward function from preference data and performs policy optimization based on this learned token-wise reward signal. Theoretically, texttt{RTO} is proven to have the capability of finding the near-optimal policy sample-efficiently. For its practical implementation, texttt{RTO} innovatively integrates Direct Preference Optimization (DPO) and PPO. DPO, originally derived from sparse sentence rewards, surprisingly provides us with a token-wise characterization of response quality, which is seamlessly incorporated into our subsequent PPO training stage. Extensive real-world alignment experiments verify the effectiveness of the proposed approach.
4/30/2024
Provably Robust DPO: Aligning Language Models with Noisy Feedback
Sayak Ray Chowdhury, Anush Kini, Nagarajan Natarajan
0
0
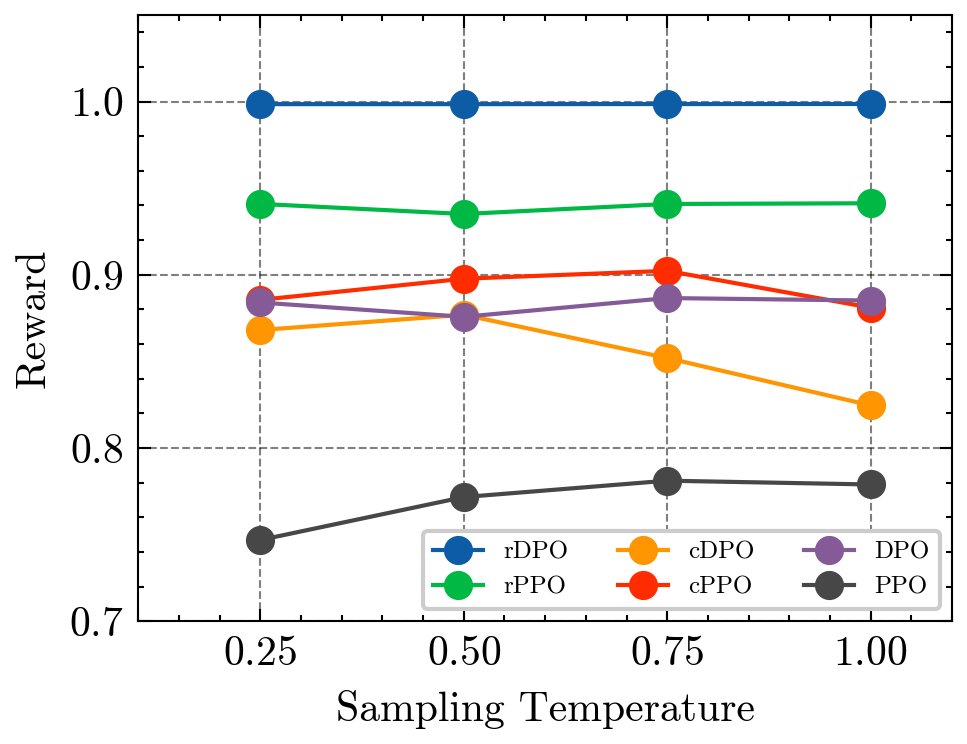
Learning from preference-based feedback has recently gained traction as a promising approach to align language models with human interests. While these aligned generative models have demonstrated impressive capabilities across various tasks, their dependence on high-quality human preference data poses a bottleneck in practical applications. Specifically, noisy (incorrect and ambiguous) preference pairs in the dataset might restrict the language models from capturing human intent accurately. While practitioners have recently proposed heuristics to mitigate the effect of noisy preferences, a complete theoretical understanding of their workings remain elusive. In this work, we aim to bridge this gap by by introducing a general framework for policy optimization in the presence of random preference flips. We focus on the direct preference optimization (DPO) algorithm in particular since it assumes that preferences adhere to the Bradley-Terry-Luce (BTL) model, raising concerns about the impact of noisy data on the learned policy. We design a novel loss function, which de-bias the effect of noise on average, making a policy trained by minimizing that loss robust to the noise. Under log-linear parameterization of the policy class and assuming good feature coverage of the SFT policy, we prove that the sub-optimality gap of the proposed robust DPO (rDPO) policy compared to the optimal policy is of the order $O(frac{1}{1-2epsilon}sqrt{frac{d}{n}})$, where $epsilon < 1/2$ is flip rate of labels, $d$ is policy parameter dimension and $n$ is size of dataset. Our experiments on IMDb sentiment generation and Anthropic's helpful-harmless dataset show that rDPO is robust to noise in preference labels compared to vanilla DPO and other heuristics proposed by practitioners.
4/15/2024
Dataset Reset Policy Optimization for RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kiant'e Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
0
0
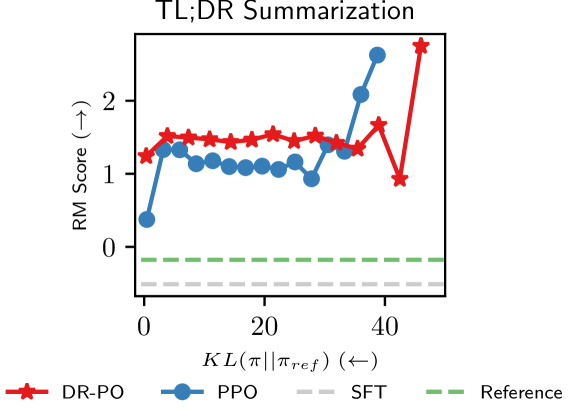
Reinforcement Learning (RL) from Human Preference-based feedback is a popular paradigm for fine-tuning generative models, which has produced impressive models such as GPT-4 and Claude3 Opus. This framework often consists of two steps: learning a reward model from an offline preference dataset followed by running online RL to optimize the learned reward model. In this work, leveraging the idea of reset, we propose a new RLHF algorithm with provable guarantees. Motivated by the fact that offline preference dataset provides informative states (i.e., data that is preferred by the labelers), our new algorithm, Dataset Reset Policy Optimization (DR-PO), integrates the existing offline preference dataset into the online policy training procedure via dataset reset: it directly resets the policy optimizer to the states in the offline dataset, instead of always starting from the initial state distribution. In theory, we show that DR-PO learns to perform at least as good as any policy that is covered by the offline dataset under general function approximation with finite sample complexity. In experiments, we demonstrate that on both the TL;DR summarization and the Anthropic Helpful Harmful (HH) dataset, the generation from DR-PO is better than that from Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO), under the metric of GPT4 win-rate. Code for this work can be found at https://github.com/Cornell-RL/drpo.
4/17/2024
🏅
REBEL: Reinforcement Learning via Regressing Relative Rewards
Zhaolin Gao, Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kiant'e Brantley, Thorsten Joachims, J. Andrew Bagnell, Jason D. Lee, Wen Sun
0
0
While originally developed for continuous control problems, Proximal Policy Optimization (PPO) has emerged as the work-horse of a variety of reinforcement learning (RL) applications including the fine-tuning of generative models. Unfortunately, PPO requires multiple heuristics to enable stable convergence (e.g. value networks, clipping) and is notorious for its sensitivity to the precise implementation of these components. In response, we take a step back and ask what a minimalist RL algorithm for the era of generative models would look like. We propose REBEL, an algorithm that cleanly reduces the problem of policy optimization to regressing the relative rewards via a direct policy parameterization between two completions to a prompt, enabling strikingly lightweight implementation. In theory, we prove that fundamental RL algorithms like Natural Policy Gradient can be seen as variants of REBEL, which allows us to match the strongest known theoretical guarantees in terms of convergence and sample complexity in the RL literature. REBEL can also cleanly incorporate offline data and handle the intransitive preferences we frequently see in practice. Empirically, we find that REBEL provides a unified approach to language modeling and image generation with stronger or similar performance as PPO and DPO, all while being simpler to implement and more computationally tractable than PPO.
4/26/2024