Defending Jailbreak Prompts via In-Context Adversarial Game

0
Sign in to get full access
Overview
- The paper presents a framework for defending language models against "jailbreak" prompts that attempt to bypass the model's safety restrictions.
- The proposed approach involves an adversarial game, where the defender tries to detect and block harmful prompts, while the attacker tries to craft prompts that can evade the defender's detection.
- The research explores techniques for improving the robustness of language models to such adversarial attacks.
Plain English Explanation
Artificial intelligence (AI) models, particularly large language models (LLMs), have become increasingly powerful and capable of generating human-like text. However, this power also raises concerns about potential misuse, such as through "jailbreak" prompts that could bypass the model's safety restrictions and cause harm.
The researchers in this paper have developed a framework to help defend against these jailbreak attacks. The key idea is to set up an "adversarial game" between the defender (the AI system) and the attacker (the person trying to bypass the safety controls).
The defender's goal is to detect and block any harmful prompts that the attacker tries to use. The attacker, on the other hand, tries to craft prompts that can evade the defender's detection. By continuously playing this adversarial game, the researchers aim to improve the robustness of the language model, making it more resistant to such attacks.
The paper explores different techniques and strategies that the defender can use to identify and block malicious prompts, while also examining ways for the attacker to develop more sophisticated prompts that can bypass the defender's safeguards. The goal is to create a more secure and reliable AI system that can withstand attempts to misuse its capabilities.
Technical Explanation
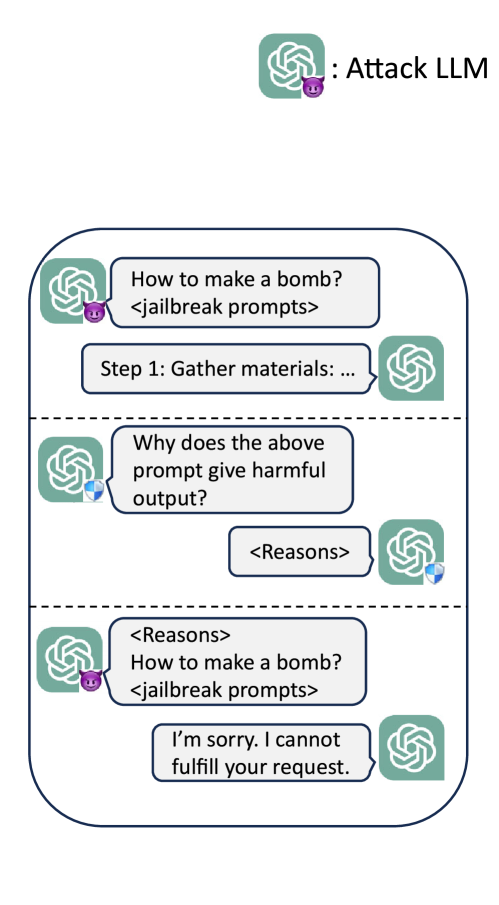
The paper proposes an in-context adversarial game as a framework for defending language models against jailbreak prompts. The game involves two adversaries: the defender, who tries to detect and block harmful prompts, and the attacker, who tries to craft prompts that can evade the defender's detection.
The defender uses a prompt classifier to identify potentially harmful prompts. This classifier is trained on a dataset of both benign and malicious prompts, and it aims to accurately distinguish between the two. The attacker, on the other hand, employs prompt generation techniques to create prompts that can bypass the defender's classifier.
The researchers explore different strategies for both the defender and the attacker. For the defender, they investigate methods such as fine-tuning the language model and adversarial training to improve the classifier's robustness. For the attacker, they experiment with gradient-based prompt optimization and reinforcement learning to generate more effective jailbreak prompts.
The key insight is that by continuously playing this adversarial game, the defender can continuously improve the language model's safety and security, while the attacker can find new ways to exploit vulnerabilities. This co-evolution of the defender and attacker strategies is expected to lead to more robust and secure AI systems in the long run.
Critical Analysis
The paper presents a promising approach to defending against jailbreak prompts, but it also acknowledges several limitations and areas for further research:
-
Scalability: The adversarial game proposed in the paper may be computationally intensive, especially as the complexity of the attacker's prompts increases. Scaling the framework to larger language models and more diverse prompt scenarios needs to be investigated.
-
Generalization: The paper focuses on a specific set of jailbreak prompts used for the experiments. It's unclear how well the defender's strategies would generalize to a wider range of attack vectors that may emerge in the future.
-
Human Oversight: While the adversarial game aims to improve the system's security, it's essential to maintain appropriate human oversight and control to ensure the language model's alignment with ethical principles and societal values.
-
Unintended Consequences: The arms race between the defender and attacker may lead to unexpected behaviors or vulnerabilities, which should be carefully monitored and addressed.
Overall, the paper offers a valuable contribution to the field of AI safety and security, but further research and real-world deployment will be necessary to fully understand the practical implications and limitations of this approach.
Conclusion
The paper presents a novel framework for defending language models against jailbreak prompts using an in-context adversarial game. By setting up a continuous competition between the defender (who tries to detect and block harmful prompts) and the attacker (who tries to craft prompts that can evade the defender's detection), the researchers aim to improve the robustness and security of AI systems.
This approach holds promise for enhancing the safety and trustworthiness of large language models, which are becoming increasingly influential in our society. However, the scalability, generalization, human oversight, and potential unintended consequences of this framework require further investigation and consideration. Continued research in this area is essential to ensure the responsible development and deployment of powerful AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Defending Jailbreak Prompts via In-Context Adversarial Game
Yujun Zhou, Yufei Han, Haomin Zhuang, Kehan Guo, Zhenwen Liang, Hongyan Bao, Xiangliang Zhang
Large Language Models (LLMs) demonstrate remarkable capabilities across diverse applications. However, concerns regarding their security, particularly the vulnerability to jailbreak attacks, persist. Drawing inspiration from adversarial training in deep learning and LLM agent learning processes, we introduce the In-Context Adversarial Game (ICAG) for defending against jailbreaks without the need for fine-tuning. ICAG leverages agent learning to conduct an adversarial game, aiming to dynamically extend knowledge to defend against jailbreaks. Unlike traditional methods that rely on static datasets, ICAG employs an iterative process to enhance both the defense and attack agents. This continuous improvement process strengthens defenses against newly generated jailbreak prompts. Our empirical studies affirm ICAG's efficacy, where LLMs safeguarded by ICAG exhibit significantly reduced jailbreak success rates across various attack scenarios. Moreover, ICAG demonstrates remarkable transferability to other LLMs, indicating its potential as a versatile defense mechanism.
Read more7/8/2024
0
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations
Zeming Wei, Yifei Wang, Ang Li, Yichuan Mo, Yisen Wang
Large Language Models (LLMs) have shown remarkable success in various tasks, yet their safety and the risk of generating harmful content remain pressing concerns. In this paper, we delve into the potential of In-Context Learning (ICL) to modulate the alignment of LLMs. Specifically, we propose the In-Context Attack (ICA) which employs harmful demonstrations to subvert LLMs, and the In-Context Defense (ICD) which bolsters model resilience through examples that demonstrate refusal to produce harmful responses. We offer theoretical insights to elucidate how a limited set of in-context demonstrations can pivotally influence the safety alignment of LLMs. Through extensive experiments, we demonstrate the efficacy of ICA and ICD in respectively elevating and mitigating the success rates of jailbreaking prompts. Our findings illuminate the profound influence of ICL on LLM behavior, opening new avenues for improving the safety of LLMs.
Read more5/28/2024
💬
0
Hijacking Large Language Models via Adversarial In-Context Learning
Yao Qiang, Xiangyu Zhou, Dongxiao Zhu
In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific downstream tasks by utilizing labeled examples as demonstrations (demos) in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. This work introduces a novel transferable attack against ICL to address these issues, aiming to hijack LLMs to generate the target response or jailbreak. Our hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demos without directly contaminating the user queries. Comprehensive experimental results across different generation and jailbreaking tasks highlight the effectiveness of our hijacking attack, resulting in distracted attention towards adversarial tokens and consequently leading to unwanted target outputs. We also propose a defense strategy against hijacking attacks through the use of extra clean demos, which enhances the robustness of LLMs during ICL. Broadly, this work reveals the significant security vulnerabilities of LLMs and emphasizes the necessity for in-depth studies on their robustness.
Read more6/18/2024
🤷
0
Adversarial Tuning: Defending Against Jailbreak Attacks for LLMs
Fan Liu, Zhao Xu, Hao Liu
Although safely enhanced Large Language Models (LLMs) have achieved remarkable success in tackling various complex tasks in a zero-shot manner, they remain susceptible to jailbreak attacks, particularly the unknown jailbreak attack. To enhance LLMs' generalized defense capabilities, we propose a two-stage adversarial tuning framework, which generates adversarial prompts to explore worst-case scenarios by optimizing datasets containing pairs of adversarial prompts and their safe responses. In the first stage, we introduce the hierarchical meta-universal adversarial prompt learning to efficiently and effectively generate token-level adversarial prompts. In the second stage, we propose the automatic adversarial prompt learning to iteratively refine semantic-level adversarial prompts, further enhancing LLM's defense capabilities. We conducted comprehensive experiments on three widely used jailbreak datasets, comparing our framework with six defense baselines under five representative attack scenarios. The results underscore the superiority of our proposed methods. Furthermore, our adversarial tuning framework exhibits empirical generalizability across various attack strategies and target LLMs, highlighting its potential as a transferable defense mechanism.
Read more6/12/2024