A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
2311.00344
1
0
🔗
Abstract
A lot of recent machine learning research papers have ``open-ended learning'' in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to produce elements from time to time (e.g., observations, options, reward functions, and goals), over an infinite horizon, that are considered novel from an observer's perspective. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems in which agents can learn a growing repertoire of goal-driven skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
Create account to get full access
Overview
- Recent machine learning research papers have focused on "open-ended learning," but there is little consensus on what the term actually means.
- This paper aims to provide a clear definition of open-ended learning and distinguish it from related concepts like continual learning and lifelong learning.
- The authors propose that the key property of open-ended learning is the ability to produce novel elements (observations, options, reward functions, and goals) over an infinite horizon.
- The paper focuses on open-ended goal-conditioned reinforcement learning, where agents can learn a growing repertoire of goal-driven skills.
Plain English Explanation
Many recent machine learning papers have used the term "open-ended learning," but it's not always clear what that means. This paper tries to fix that by defining open-ended learning and explaining how it's different from similar ideas like continual learning and lifelong learning.
The key idea is that open-ended learning is about an agent's ability to keep producing new and novel things - like observations, choices, rewards, or goals - over a very long period of time. This is different from systems that just try to learn a fixed set of skills or knowledge.
The paper focuses on a specific type of open-ended learning called "open-ended goal-conditioned reinforcement learning." In this setup, the agent can learn an ever-growing collection of skills that allow it to achieve different goals. This could be a step towards the kind of artificial general intelligence that some researchers dream of, where machines can learn and adapt in truly open-ended ways.
However, the paper also points out that there's still a lot of work to be done to fully capture the complexity of open-ended learning as envisioned by AI researchers working on developmental AI and reinforcement learning. The elementary definition provided in this paper is a starting point, but more work is needed to bridge the gap.
Technical Explanation
The paper begins by highlighting the lack of consensus around the term "open-ended learning" in recent machine learning research. The authors illustrate the genealogy of the concept and outline more recent perspectives on what open-ended learning truly means.
They propose that the key elementary property of open-ended processes is the ability to produce novel elements (such as observations, options, reward functions, and goals) over an infinite horizon, from the perspective of an observer. This is in contrast with previous approaches that have treated open-ended learning as a more complex, composite notion.
The paper then focuses on the specific case of open-ended goal-conditioned reinforcement learning, where agents can learn a growing repertoire of goal-driven skills. This is presented as a potential step towards the kind of artificial general intelligence envisioned by some researchers.
However, the authors acknowledge that their elementary definition of open-ended learning may not fully capture the more involved notions that developmental AI researchers have in mind. They highlight the need for further work to bridge this gap and more fully understand the complexities of open-ended learning.
Critical Analysis
The paper makes a valuable contribution by providing a clear and concise definition of open-ended learning, which can help bring more clarity to this important concept in machine learning research. By isolating the key property of producing novel elements over an infinite horizon, the authors offer a useful starting point for further exploration and investigation.
That said, the authors rightfully acknowledge that their definition may not fully capture the more complex and nuanced understanding of open-ended learning held by researchers in the field of developmental AI. More work is needed to bridge this gap and develop a more comprehensive theory of open-ended learning that can account for the diverse perspectives and goals in the AI research community.
Additionally, while the focus on open-ended goal-conditioned reinforcement learning is a promising direction, the paper does not provide a detailed analysis of the specific challenges and limitations of this approach. Further research may be needed to identify and address the potential issues that may arise when attempting to scale open-ended learning to more complex and open-ended environments.
Overall, this paper represents a valuable step forward in the ongoing effort to define and understand the concept of open-ended learning. By providing a clear and concise starting point, the authors have laid the groundwork for further advancements in this important area of AI research.
Conclusion
This paper aims to bring clarity to the concept of "open-ended learning" in machine learning research. The authors propose that the key property of open-ended learning is the ability to produce novel elements, such as observations, options, reward functions, and goals, over an infinite horizon.
The paper focuses on the specific case of open-ended goal-conditioned reinforcement learning, where agents can learn a growing repertoire of goal-driven skills. This is seen as a potential step towards the kind of artificial general intelligence that some researchers envision.
However, the authors acknowledge that their elementary definition may not fully capture the more complex and nuanced understanding of open-ended learning held by researchers in the field of developmental AI. Further work is needed to bridge this gap and develop a more comprehensive theory of open-ended learning that can account for the diverse perspectives and goals in the AI research community.
Overall, this paper represents a valuable contribution to the ongoing effort to define and understand the concept of open-ended learning, which is a critical component in the pursuit of more advanced and adaptable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
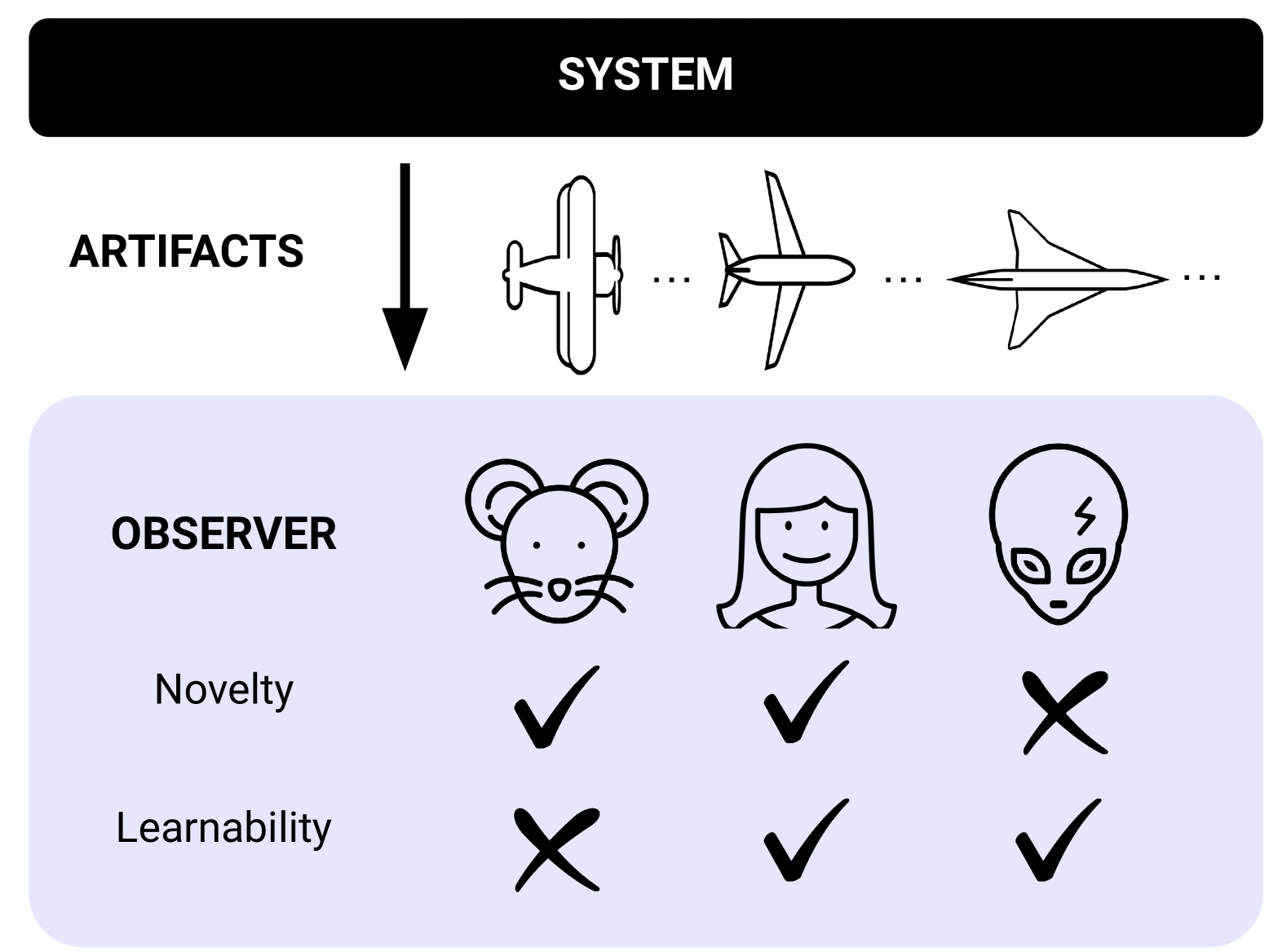
Open-Endedness is Essential for Artificial Superhuman Intelligence
Edward Hughes, Michael Dennis, Jack Parker-Holder, Feryal Behbahani, Aditi Mavalankar, Yuge Shi, Tom Schaul, Tim Rocktaschel
0
0
In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
6/7/2024
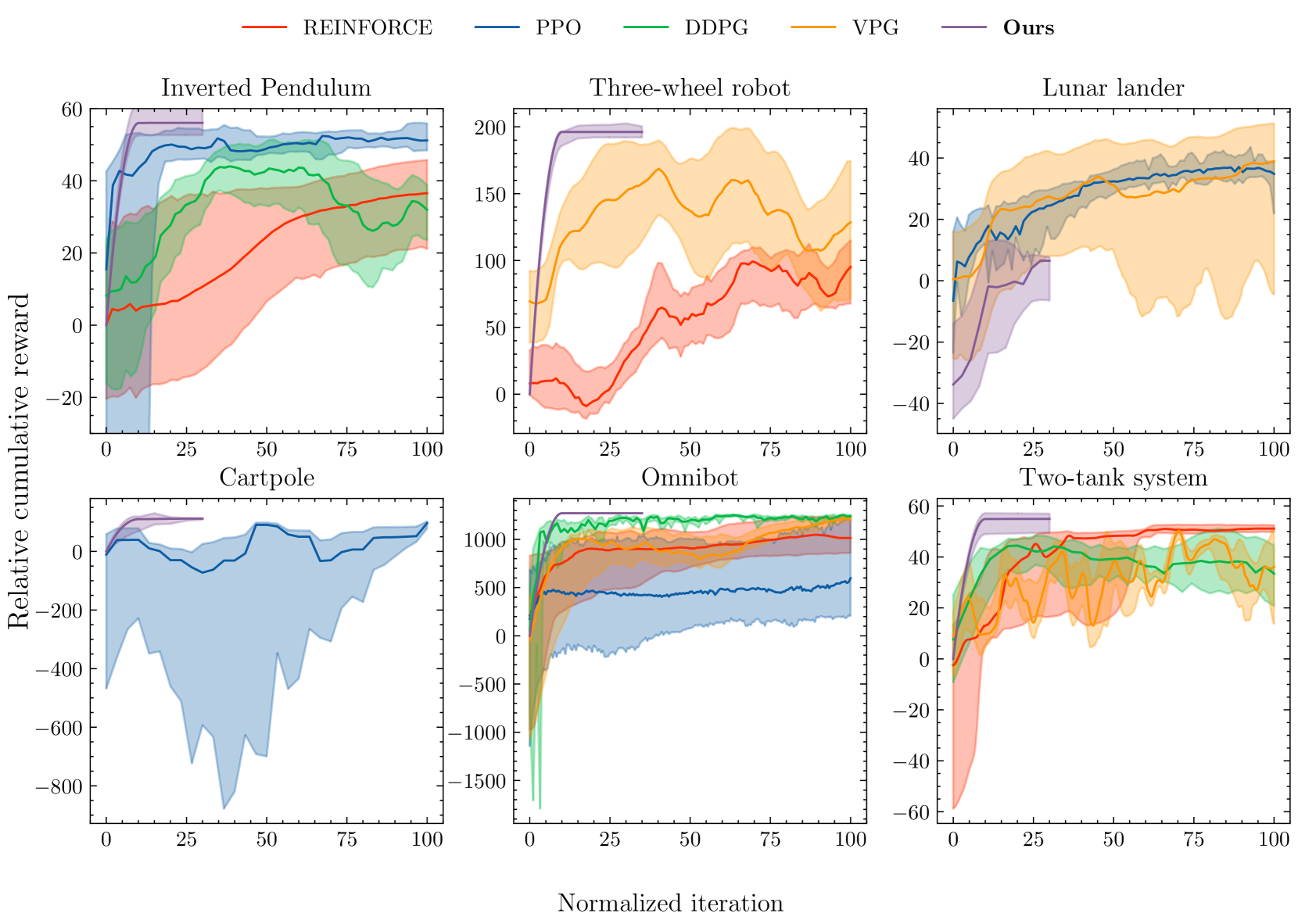
An approach to improve agent learning via guaranteeing goal reaching in all episodes
Pavel Osinenko, Grigory Yaremenko, Georgiy Malaniya, Anton Bolychev
0
0
Reinforcement learning is commonly concerned with problems of maximizing accumulated rewards in Markov decision processes. Oftentimes, a certain goal state or a subset of the state space attain maximal reward. In such a case, the environment may be considered solved when the goal is reached. Whereas numerous techniques, learning or non-learning based, exist for solving environments, doing so optimally is the biggest challenge. Say, one may choose a reward rate which penalizes the action effort. Reinforcement learning is currently among the most actively developed frameworks for solving environments optimally by virtue of maximizing accumulated reward, in other words, returns. Yet, tuning agents is a notoriously hard task as reported in a series of works. Our aim here is to help the agent learn a near-optimal policy efficiently while ensuring a goal reaching property of some basis policy that merely solves the environment. We suggest an algorithm, which is fairly flexible, and can be used to augment practically any agent as long as it comprises of a critic. A formal proof of a goal reaching property is provided. Simulation experiments on six problems under five agents, including the benchmarked one, provided an empirical evidence that the learning can indeed be boosted while ensuring goal reaching property.
5/30/2024
🤯
Emergence of Collective Open-Ended Exploration from Decentralized Meta-Reinforcement Learning
Richard Bornemann, Gautier Hamon, Eleni Nisioti, Cl'ement Moulin-Frier
0
0
Recent works have proven that intricate cooperative behaviors can emerge in agents trained using meta reinforcement learning on open ended task distributions using self-play. While the results are impressive, we argue that self-play and other centralized training techniques do not accurately reflect how general collective exploration strategies emerge in the natural world: through decentralized training and over an open-ended distribution of tasks. In this work we therefore investigate the emergence of collective exploration strategies, where several agents meta-learn independent recurrent policies on an open ended distribution of tasks. To this end we introduce a novel environment with an open ended procedurally generated task space which dynamically combines multiple subtasks sampled from five diverse task types to form a vast distribution of task trees. We show that decentralized agents trained in our environment exhibit strong generalization abilities when confronted with novel objects at test time. Additionally, despite never being forced to cooperate during training the agents learn collective exploration strategies which allow them to solve novel tasks never encountered during training. We further find that the agents learned collective exploration strategies extend to an open ended task setting, allowing them to solve task trees of twice the depth compared to the ones seen during training. Our open source code as well as videos of the agents can be found on our companion website.
5/8/2024
🏋️
Towards a theory of out-of-distribution learning
Jayanta Dey, Ali Geisa, Ronak Mehta, Tyler M. Tomita, Hayden S. Helm, Haoyin Xu, Eric Eaton, Jeffery Dick, Carey E. Priebe, Joshua T. Vogelstein
0
0
Learning is a process wherein a learning agent enhances its performance through exposure of experience or data. Throughout this journey, the agent may encounter diverse learning environments. For example, data may be presented to the leaner all at once, in multiple batches, or sequentially. Furthermore, the distribution of each data sample could be either identical and independent (iid) or non-iid. Additionally, there may exist computational and space constraints for the deployment of the learning algorithms. The complexity of a learning task can vary significantly, depending on the learning setup and the constraints imposed upon it. However, it is worth noting that the current literature lacks formal definitions for many of the in-distribution and out-of-distribution learning paradigms. Establishing proper and universally agreed-upon definitions for these learning setups is essential for thoroughly exploring the evolution of ideas across different learning scenarios and deriving generalized mathematical bounds for these learners. In this paper, we aim to address this issue by proposing a chronological approach to defining different learning tasks using the provably approximately correct (PAC) learning framework. We will start with in-distribution learning and progress to recently proposed lifelong or continual learning. We employ consistent terminology and notation to demonstrate how each of these learning frameworks represents a specific instance of a broader, more generalized concept of learnability. Our hope is that this work will inspire a universally agreed-upon approach to quantifying different types of learning, fostering greater understanding and progress in the field.
6/10/2024