Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving

0

Sign in to get full access
Overview
- Presents a deformable convolution-based approach for semantic segmentation of fisheye images in autonomous driving scenarios
- Aims to address the distortion and wide field-of-view challenges of fisheye cameras
- Proposes a novel network architecture that leverages deformable convolutions to adaptively capture spatial context
Plain English Explanation
Autonomous driving systems rely on cameras to perceive the surrounding environment, but the wide-angle fisheye lenses used in these cameras can cause significant distortion in the images. This can make it challenging to accurately identify and segment the different elements of the road scene, such as roads, vehicles, pedestrians, and other objects.
The researchers in this paper propose a new method to tackle this problem. They developed a deep neural network architecture that uses deformable convolutions - a type of convolutional layer that can adaptively adjust its shape and position to better capture the spatial context in the distorted fisheye images.
By using this deformable convolution approach, the network is able to more effectively learn the complex patterns and relationships in the fisheye imagery, leading to improved semantic segmentation performance compared to standard convolutional networks. This allows the autonomous driving system to better understand the road scene and make more informed decisions about navigation and safety.
Technical Explanation
The paper proposes a deformable convolution-based network architecture for semantic segmentation of fisheye images in autonomous driving scenarios. Deformable convolutions are a type of convolutional layer that can adaptively adjust the shape and position of the convolution kernels to better capture spatial context, which is particularly important for handling the distortion and wide field-of-view of fisheye cameras.
The network starts with a backbone feature extractor, followed by a deformable convolution module that learns the spatial offsets for the convolution kernels. This is then followed by additional convolutional and upsampling layers to produce the final segmentation map.
The authors evaluate their approach on a fisheye image dataset for autonomous driving, and show that the deformable convolution-based model outperforms standard convolutional networks in terms of segmentation accuracy. This demonstrates the effectiveness of the proposed method in addressing the unique challenges of fisheye imagery in the context of road scene understanding for self-driving cars.
Critical Analysis
The paper presents a well-designed and comprehensive study on the use of deformable convolutions for semantic segmentation of fisheye images in autonomous driving. The authors have thoroughly evaluated their approach and demonstrated its superiority over standard convolutional networks.
However, one potential limitation is that the evaluation was conducted on a single dataset, so the generalizability of the approach to other fisheye image datasets or real-world autonomous driving scenarios may need further investigation. Additionally, the paper does not delve into the computational complexity or inference time of the deformable convolution-based model, which could be an important consideration for real-time autonomous driving applications.
Further research could explore integrating the deformable convolution module with other advanced segmentation architectures, or investigating the use of deformable convolutions for other computer vision tasks in the context of autonomous driving, such as object detection or depth estimation. Additionally, evaluating the model's performance on more diverse and challenging fisheye image datasets would help validate the approach's robustness and generalization capabilities.
Conclusion
This paper presents a deformable convolution-based approach for semantic segmentation of fisheye images in autonomous driving scenarios. By leveraging the adaptive spatial modeling capabilities of deformable convolutions, the proposed network architecture is able to effectively handle the distortion and wide field-of-view challenges of fisheye cameras, leading to improved segmentation performance compared to standard convolutional networks.
The proposed method represents an important step forward in enhancing the computer vision capabilities of autonomous driving systems, which rely on accurate understanding of the surrounding environment for safe and efficient navigation. As the field of autonomous driving continues to evolve, approaches like the one described in this paper will play a crucial role in enabling more robust and reliable self-driving technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deformable Convolution Based Road Scene Semantic Segmentation of Fisheye Images in Autonomous Driving
Anam Manzoor, Aryan Singh, Ganesh Sistu, Reenu Mohandas, Eoin Grua, Anthony Scanlan, Ciar'an Eising
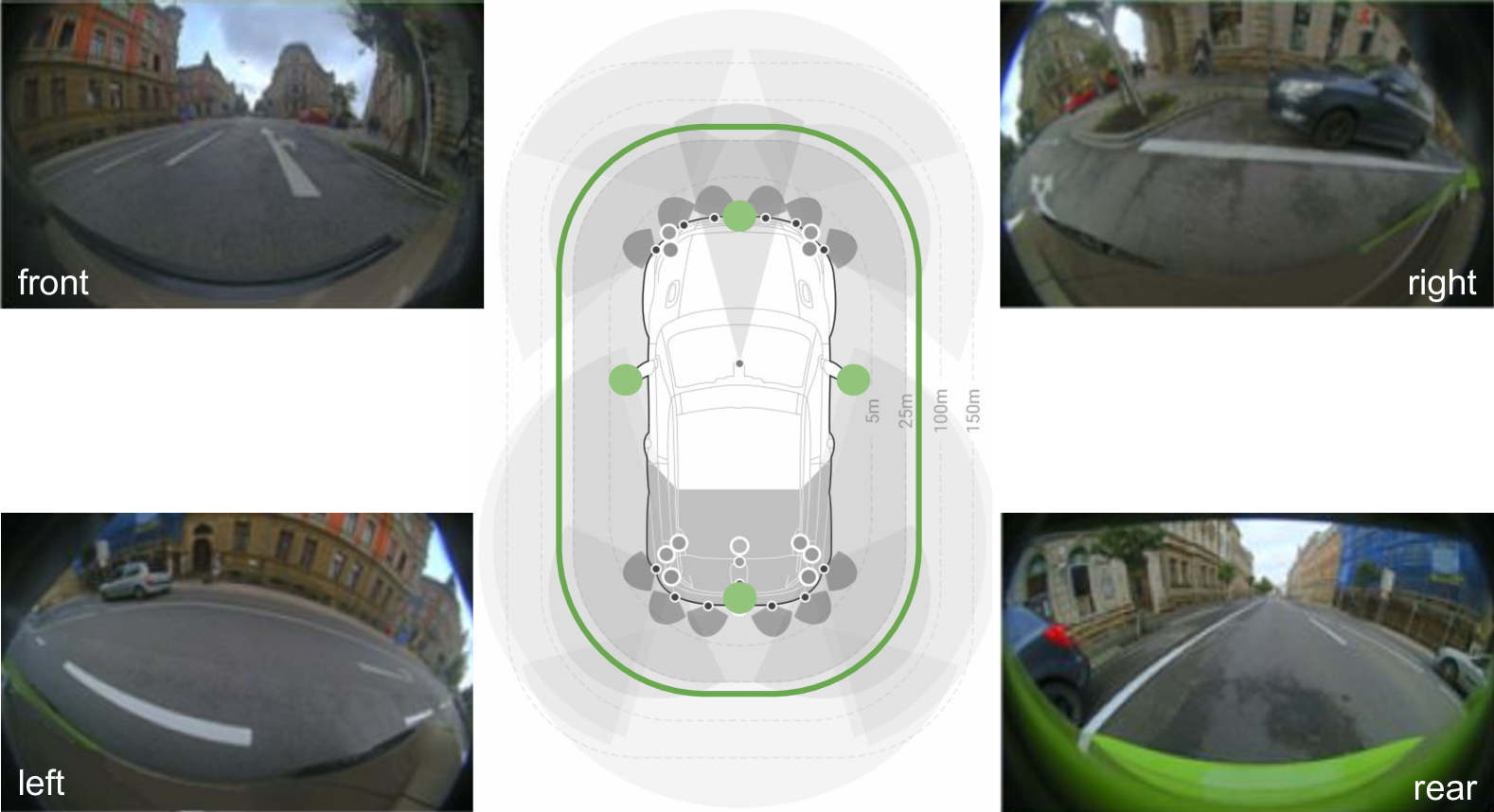
This study investigates the effectiveness of modern Deformable Convolutional Neural Networks (DCNNs) for semantic segmentation tasks, particularly in autonomous driving scenarios with fisheye images. These images, providing a wide field of view, pose unique challenges for extracting spatial and geometric information due to dynamic changes in object attributes. Our experiments focus on segmenting the WoodScape fisheye image dataset into ten distinct classes, assessing the Deformable Networks' ability to capture intricate spatial relationships and improve segmentation accuracy. Additionally, we explore different loss functions to address class imbalance issues and compare the performance of conventional CNN architectures with Deformable Convolution-based CNNs, including Vanilla U-Net and Residual U-Net architectures. The significant improvement in mIoU score resulting from integrating Deformable CNNs demonstrates their effectiveness in handling the geometric distortions present in fisheye imagery, exceeding the performance of traditional CNN architectures. This underscores the significant role of Deformable convolution in enhancing semantic segmentation performance for fisheye imagery.
Read more7/24/2024

0
DaF-BEVSeg: Distortion-aware Fisheye Camera based Bird's Eye View Segmentation with Occlusion Reasoning
Senthil Yogamani, David Unger, Venkatraman Narayanan, Varun Ravi Kumar
Semantic segmentation is an effective way to perform scene understanding. Recently, segmentation in 3D Bird's Eye View (BEV) space has become popular as its directly used by drive policy. However, there is limited work on BEV segmentation for surround-view fisheye cameras, commonly used in commercial vehicles. As this task has no real-world public dataset and existing synthetic datasets do not handle amodal regions due to occlusion, we create a synthetic dataset using the Cognata simulator comprising diverse road types, weather, and lighting conditions. We generalize the BEV segmentation to work with any camera model; this is useful for mixing diverse cameras. We implement a baseline by applying cylindrical rectification on the fisheye images and using a standard LSS-based BEV segmentation model. We demonstrate that we can achieve better performance without undistortion, which has the adverse effects of increased runtime due to pre-processing, reduced field-of-view, and resampling artifacts. Further, we introduce a distortion-aware learnable BEV pooling strategy that is more effective for the fisheye cameras. We extend the model with an occlusion reasoning module, which is critical for estimating in BEV space. Qualitative performance of DaF-BEVSeg is showcased in the video at https://streamable.com/ge4v51.
Read more4/10/2024
0
FisheyeDetNet: Object Detection on Fisheye Surround View Camera Systems for Automated Driving
Ganesh Sistu, Senthil Yogamani
Object detection is a mature problem in autonomous driving with pedestrian detection being one of the first deployed algorithms. It has been comprehensively studied in the literature. However, object detection is relatively less explored for fisheye cameras used for surround-view near field sensing. The standard bounding box representation fails in fisheye cameras due to heavy radial distortion, particularly in the periphery. To mitigate this, we explore extending the standard object detection output representation of bounding box. We design rotated bounding boxes, ellipse, generic polygon as polar arc/angle representations and define an instance segmentation mIOU metric to analyze these representations. The proposed model FisheyeDetNet with polygon outperforms others and achieves a mAP score of 49.5 % on Valeo fisheye surround-view dataset for automated driving applications. This dataset has 60K images captured from 4 surround-view cameras across Europe, North America and Asia. To the best of our knowledge, this is the first detailed study on object detection on fisheye cameras for autonomous driving scenarios.
Read more4/30/2024

0
Adapting CNNs for Fisheye Cameras without Retraining
Ryan Griffiths, Donald G. Dansereau
The majority of image processing approaches assume images are in or can be rectified to a perspective projection. However, in many applications it is beneficial to use non conventional cameras, such as fisheye cameras, that have a larger field of view (FOV). The issue arises that these large-FOV images can't be rectified to a perspective projection without significant cropping of the original image. To address this issue we propose Rectified Convolutions (RectConv); a new approach for adapting pre-trained convolutional networks to operate with new non-perspective images, without any retraining. Replacing the convolutional layers of the network with RectConv layers allows the network to see both rectified patches and the entire FOV. We demonstrate RectConv adapting multiple pre-trained networks to perform segmentation and detection on fisheye imagery from two publicly available datasets. Our approach requires no additional data or training, and operates directly on the native image as captured from the camera. We believe this work is a step toward adapting the vast resources available for perspective images to operate across a broad range of camera geometries.
Read more4/15/2024