Why do small language models underperform? Studying Language Model Saturation via the Softmax Bottleneck
2404.07647
4
0
Abstract
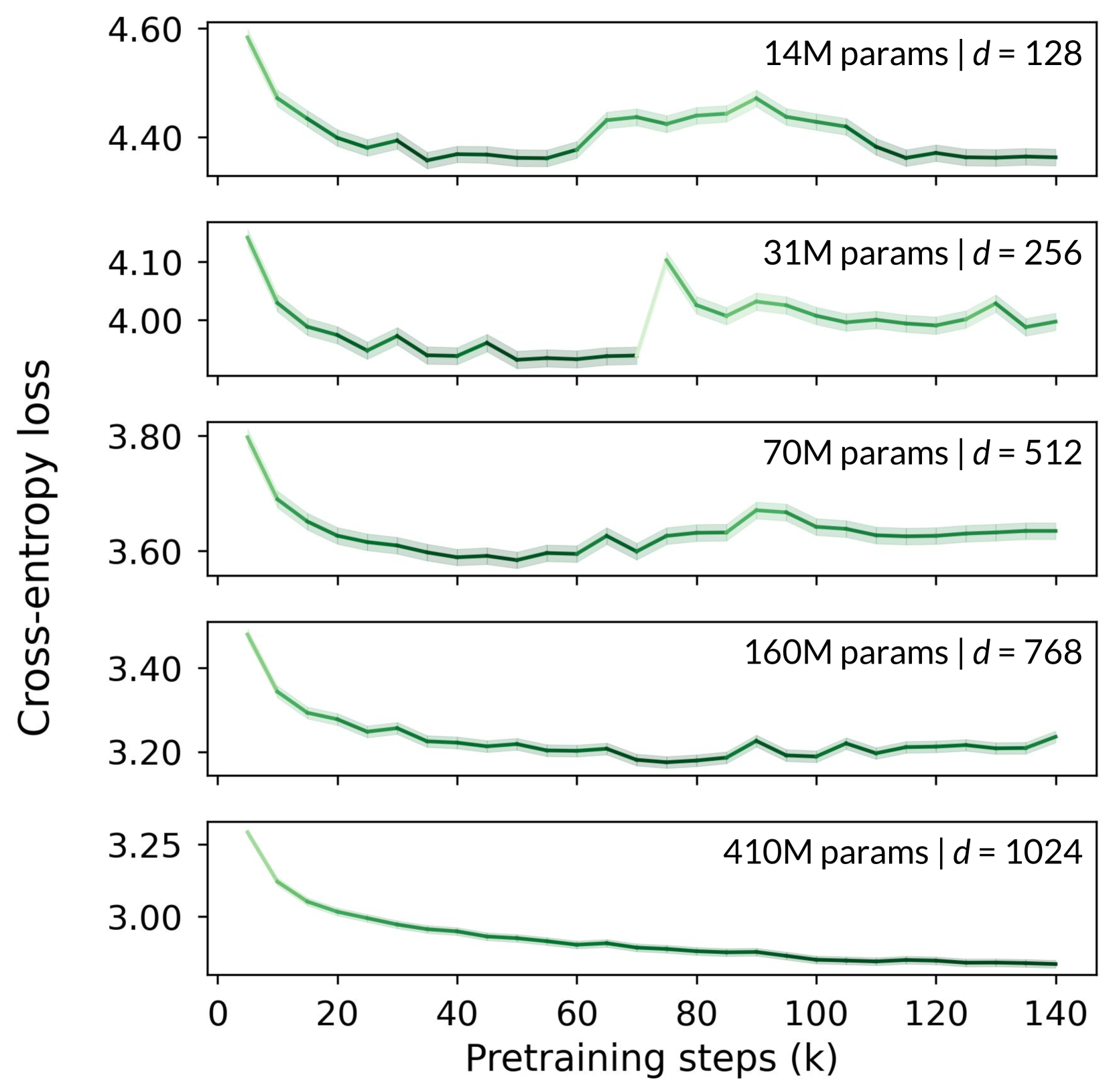
Recent advances in language modeling consist in pretraining highly parameterized neural networks on extremely large web-mined text corpora. Training and inference with such models can be costly in practice, which incentivizes the use of smaller counterparts. However, it has been observed that smaller models can suffer from saturation, characterized as a drop in performance at some advanced point in training followed by a plateau. In this paper, we find that such saturation can be explained by a mismatch between the hidden dimension of smaller models and the high rank of the target contextual probability distribution. This mismatch affects the performance of the linear prediction head used in such models through the well-known softmax bottleneck phenomenon. We measure the effect of the softmax bottleneck in various settings and find that models based on less than 1000 hidden dimensions tend to adopt degenerate latent representations in late pretraining, which leads to reduced evaluation performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper examines why small language models (LMs) often underperform compared to larger models, and investigates the role of the "softmax bottleneck" in this phenomenon.
- The softmax bottleneck refers to the final layer of a language model, where the model outputs a probability distribution over the entire vocabulary to predict the next token.
- The authors hypothesize that the softmax bottleneck can limit the model's expressive capacity, leading to saturation and performance degradation, especially in smaller models.
Plain English Explanation
Language models are AI systems that can generate human-like text by predicting the next word in a sequence. These models are trained on massive amounts of text data and have become increasingly powerful, with larger models generally performing better than smaller ones.
However, the authors of this paper have observed that small language models often underperform compared to their larger counterparts. They wanted to understand why this is the case.
The key focus of their investigation is the "softmax bottleneck" - the final layer of the language model where the model outputs a probability distribution over the entire vocabulary to predict the next word. The authors hypothesize that this softmax bottleneck can limit the model's expressive capacity, leading to a phenomenon they call "saturation," where the model's performance degrades, especially in smaller models.
By studying the softmax bottleneck, the researchers hope to gain insights into why small language models struggle and identify potential strategies to improve their performance.
Technical Explanation
The paper presents a series of experiments and analyses aimed at understanding the role of the softmax bottleneck in the performance of small language models.
The authors first establish a performance gap between small and large language models on a range of tasks, confirming the observation that smaller models tend to underperform. They then investigate the softmax bottleneck, which is the final layer of the language model that outputs a probability distribution over the entire vocabulary to predict the next token.
Through a series of experiments, the researchers find that the softmax bottleneck can limit the expressive capacity of the model, leading to a phenomenon they call "saturation." This saturation effect is more pronounced in smaller models, where the softmax bottleneck can become a significant bottleneck to performance.
To further explore the softmax bottleneck, the authors experiment with different approaches to reducing its impact, such as sparse concept bottleneck models and iteratively generated interpretable models. They also investigate strategies to enhance the inference efficiency of large language models and optimize the throughput of small language models.
The paper provides a detailed analysis of the experimental results and offers insights into the mechanisms underlying the softmax bottleneck and its impact on small language model performance.
Critical Analysis
The paper presents a well-designed study that provides valuable insights into the performance limitations of small language models. The authors' focus on the softmax bottleneck as a potential contributing factor to this phenomenon is a compelling hypothesis that is supported by their experimental findings.
However, the paper also acknowledges several caveats and areas for further research. For example, the authors note that the softmax bottleneck may not be the sole contributor to the performance gap between small and large models, and other architectural or training factors may also play a role.
Additionally, while the researchers explore several strategies to mitigate the impact of the softmax bottleneck, such as sparse concept bottleneck models and iterative model generation, the effectiveness of these approaches may be limited to specific tasks or domains. More research is needed to understand the broader applicability and scalability of these techniques.
It would also be interesting to see the authors further investigate the relationship between model size, task complexity, and the role of the softmax bottleneck. Exploring how these factors interact could yield additional insights and inform the development of more robust and performant small language models.
Conclusion
This paper offers a valuable contribution to the understanding of why small language models often underperform compared to their larger counterparts. By focusing on the softmax bottleneck, the authors have identified a key factor that can limit the expressive capacity of smaller models, leading to a phenomenon they call "saturation."
The insights gained from this research could inform the development of new techniques and architectural designs to improve the performance of small language models, making them more practical and accessible for a wider range of applications. Additionally, the study highlights the importance of carefully considering the impact of specific model components, such as the softmax layer, when designing and optimizing language models.
Overall, this paper provides a valuable foundation for further research into the challenges and opportunities presented by small language models, with the ultimate goal of bridging the performance gap and unlocking the full potential of these AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What Happens When Small Is Made Smaller? Exploring the Impact of Compression on Small Data Pretrained Language Models
Busayo Awobade, Mardiyyah Oduwole, Steven Kolawole
0
0
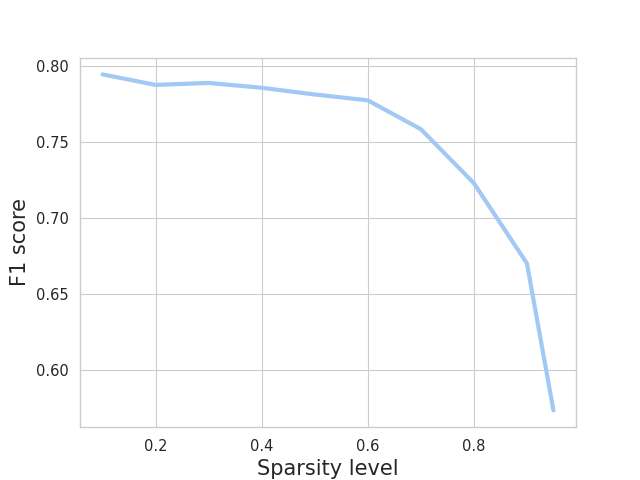
Compression techniques have been crucial in advancing machine learning by enabling efficient training and deployment of large-scale language models. However, these techniques have received limited attention in the context of low-resource language models, which are trained on even smaller amounts of data and under computational constraints, a scenario known as the low-resource double-bind. This paper investigates the effectiveness of pruning, knowledge distillation, and quantization on an exclusively low-resourced, small-data language model, AfriBERTa. Through a battery of experiments, we assess the effects of compression on performance across several metrics beyond accuracy. Our study provides evidence that compression techniques significantly improve the efficiency and effectiveness of small-data language models, confirming that the prevailing beliefs regarding the effects of compression on large, heavily parameterized models hold true for less-parameterized, small-data models.
4/9/2024
📶
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Nishant Luitel, Nirajan Bekoju, Anand Kumar Sah, Subarna Shakya
0
0
Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
4/30/2024
Sparse Concept Bottleneck Models: Gumbel Tricks in Contrastive Learning
Andrei Semenov, Vladimir Ivanov, Aleksandr Beznosikov, Alexander Gasnikov
0
0
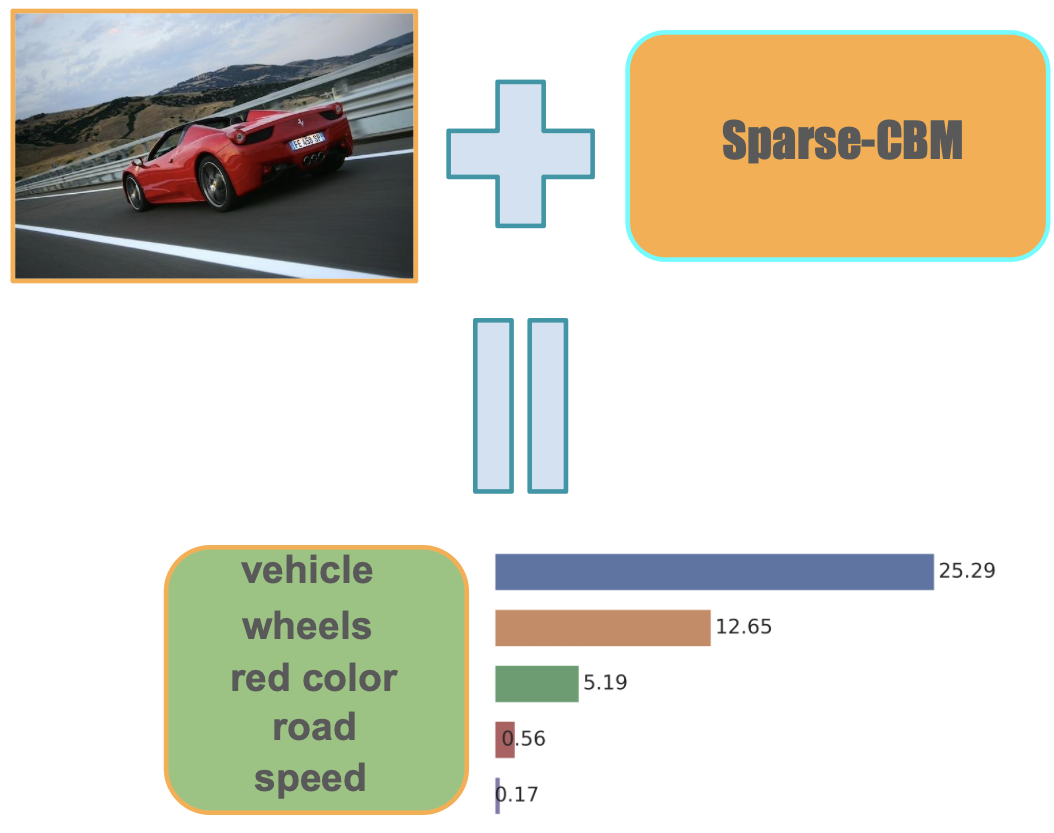
We propose a novel architecture and method of explainable classification with Concept Bottleneck Models (CBMs). While SOTA approaches to Image Classification task work as a black box, there is a growing demand for models that would provide interpreted results. Such a models often learn to predict the distribution over class labels using additional description of this target instances, called concepts. However, existing Bottleneck methods have a number of limitations: their accuracy is lower than that of a standard model and CBMs require an additional set of concepts to leverage. We provide a framework for creating Concept Bottleneck Model from pre-trained multi-modal encoder and new CLIP-like architectures. By introducing a new type of layers known as Concept Bottleneck Layers, we outline three methods for training them: with $ell_1$-loss, contrastive loss and loss function based on Gumbel-Softmax distribution (Sparse-CBM), while final FC layer is still trained with Cross-Entropy. We show a significant increase in accuracy using sparse hidden layers in CLIP-based bottleneck models. Which means that sparse representation of concepts activation vector is meaningful in Concept Bottleneck Models. Moreover, with our Concept Matrix Search algorithm we can improve CLIP predictions on complex datasets without any additional training or fine-tuning. The code is available at: https://github.com/Andron00e/SparseCBM.
4/5/2024
Delayed Bottlenecking: Alleviating Forgetting in Pre-trained Graph Neural Networks
Zhe Zhao, Pengkun Wang, Xu Wang, Haibin Wen, Xiaolong Xie, Zhengyang Zhou, Qingfu Zhang, Yang Wang
0
0
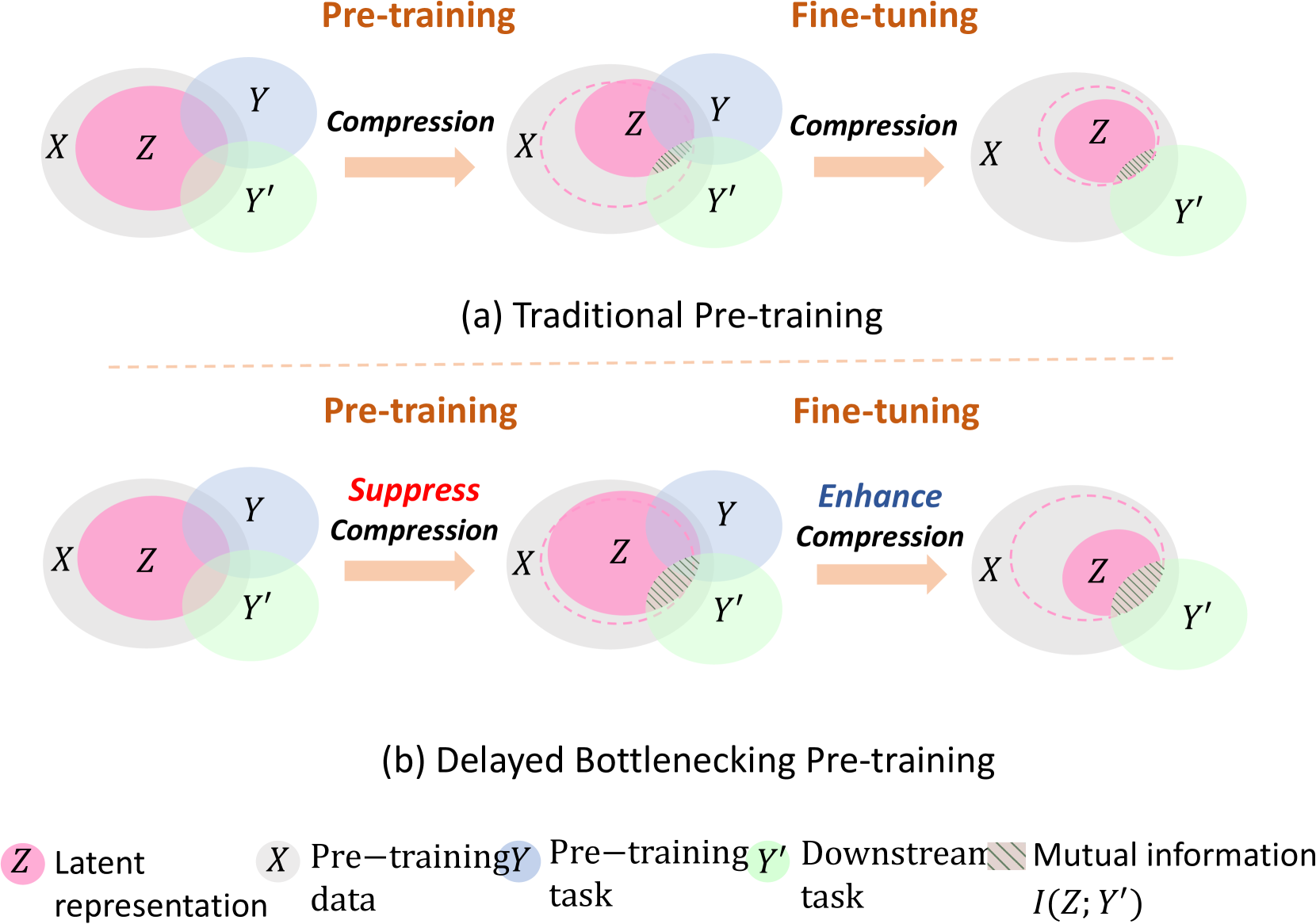
Pre-training GNNs to extract transferable knowledge and apply it to downstream tasks has become the de facto standard of graph representation learning. Recent works focused on designing self-supervised pre-training tasks to extract useful and universal transferable knowledge from large-scale unlabeled data. However, they have to face an inevitable question: traditional pre-training strategies that aim at extracting useful information about pre-training tasks, may not extract all useful information about the downstream task. In this paper, we reexamine the pre-training process within traditional pre-training and fine-tuning frameworks from the perspective of Information Bottleneck (IB) and confirm that the forgetting phenomenon in pre-training phase may cause detrimental effects on downstream tasks. Therefore, we propose a novel underline{D}elayed underline{B}ottlenecking underline{P}re-training (DBP) framework which maintains as much as possible mutual information between latent representations and training data during pre-training phase by suppressing the compression operation and delays the compression operation to fine-tuning phase to make sure the compression can be guided with labeled fine-tuning data and downstream tasks. To achieve this, we design two information control objectives that can be directly optimized and further integrate them into the actual model design. Extensive experiments on both chemistry and biology domains demonstrate the effectiveness of DBP.
4/24/2024