Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning

0

Sign in to get full access
Overview
- The research paper investigates shortcut learning in vision-language representation models.
- It demonstrates that these models can exploit superficial correlations in the data, rather than learning truly meaningful representations.
- The paper proposes techniques to reduce these shortcuts and improve the robustness and generalization of vision-language models.
Plain English Explanation
Vision-language models are AI systems that can process and understand both visual and textual information. These models are trained on large datasets that pair images with corresponding captions or descriptions.
However, the researchers found that these models can sometimes take "shortcuts" during the learning process. Instead of learning meaningful, generalizable representations, the models may simply learn to exploit superficial patterns or correlations in the training data. For example, a model might associate certain visual features with specific words or phrases, without truly understanding the deeper semantic relationships.
This can lead to models that perform well on the original training data, but struggle to generalize to new, unseen situations. The researchers demonstrate several examples of this shortcut learning behavior, showing how the models can be "fooled" by subtle changes to the input data.
To address this issue, the paper proposes techniques to reduce these shortcuts and encourage the models to learn more robust, generalizable representations. This includes modifying the training data, adjusting the model architecture, and incorporating additional training objectives.
By mitigating shortcut learning, the researchers aim to improve the reliability and real-world applicability of vision-language models, ensuring they can truly understand the underlying relationships between visual and textual information, rather than relying on superficial cues.
Technical Explanation
The paper begins by defining the problem of shortcut learning in vision-language models. Specifically, the authors show that these models can exploit "superficial statistical regularities" in the training data, rather than learning meaningful representations that generalize well to new situations.
To demonstrate this, the researchers conduct a series of experiments using various vision-language models and datasets. They introduce "probing tasks" that are designed to reveal the models' reliance on shortcuts, such as predicting captions from images that have been transformed in subtle ways.
The results indicate that the models often fail these probing tasks, suggesting they have not learned robust, generalizable representations. The authors also explore the impact of shortcut learning on downstream applications, such as visual question answering.
To mitigate these issues, the paper proposes several techniques, including data augmentation, contrastive learning, and multi-task training. These methods aim to encourage the models to learn more meaningful representations that are less susceptible to shortcut learning.
Overall, the paper provides valuable insights into the limitations of current vision-language models and proposes practical solutions to improve their robustness and generalization capabilities.
Critical Analysis
The paper makes a strong case for the problem of shortcut learning in vision-language models, providing compelling experimental evidence to support its claims. The probing tasks and analyses are well-designed and thorough, giving the reader confidence in the validity of the findings.
However, the paper could be strengthened by a more in-depth discussion of the potential causes and underlying mechanisms of shortcut learning. While the proposed solutions are promising, a deeper understanding of the root causes could lead to even more effective mitigation strategies.
Additionally, the paper could explore the broader implications of shortcut learning, such as its impact on real-world applications, the ethical considerations of deploying such models, and the potential challenges in scaling the proposed techniques to larger and more complex models and datasets.
Finally, the paper could acknowledge some of the inherent limitations of the research, such as the specific model architectures and datasets used, and suggest avenues for future work to further refine and validate the findings.
Conclusion
This research paper provides a crucial examination of the shortcut learning phenomenon in vision-language models, highlighting a critical limitation in the current state of the art. By demonstrating the problem and proposing techniques to mitigate it, the authors make a valuable contribution to the field, paving the way for more robust and generalizable vision-language models that can better serve real-world applications.
The insights and solutions presented in this paper have the potential to significantly improve the reliability and trustworthiness of these powerful AI systems, ensuring they can truly understand the rich relationships between visual and textual information, rather than relying on superficial cues. As the field of vision-language AI continues to evolve, this work serves as an important step towards more reliable and trustworthy models that can better serve societal needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Demonstrating and Reducing Shortcuts in Vision-Language Representation Learning
Maurits Bleeker, Mariya Hendriksen, Andrew Yates, Maarten de Rijke
Vision-language models (VLMs) mainly rely on contrastive training to learn general-purpose representations of images and captions. We focus on the situation when one image is associated with several captions, each caption containing both information shared among all captions and unique information per caption about the scene depicted in the image. In such cases, it is unclear whether contrastive losses are sufficient for learning task-optimal representations that contain all the information provided by the captions or whether the contrastive learning setup encourages the learning of a simple shortcut that minimizes contrastive loss. We introduce synthetic shortcuts for vision-language: a training and evaluation framework where we inject synthetic shortcuts into image-text data. We show that contrastive VLMs trained from scratch or fine-tuned with data containing these synthetic shortcuts mainly learn features that represent the shortcut. Hence, contrastive losses are not sufficient to learn task-optimal representations, i.e., representations that contain all task-relevant information shared between the image and associated captions. We examine two methods to reduce shortcut learning in our training and evaluation framework: (i) latent target decoding and (ii) implicit feature modification. We show empirically that both methods improve performance on the evaluation task, but only partly reduce shortcut learning when training and evaluating with our shortcut learning framework. Hence, we show the difficulty and challenge of our shortcut learning framework for contrastive vision-language representation learning.
Read more8/2/2024

0
Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
Read more4/26/2024
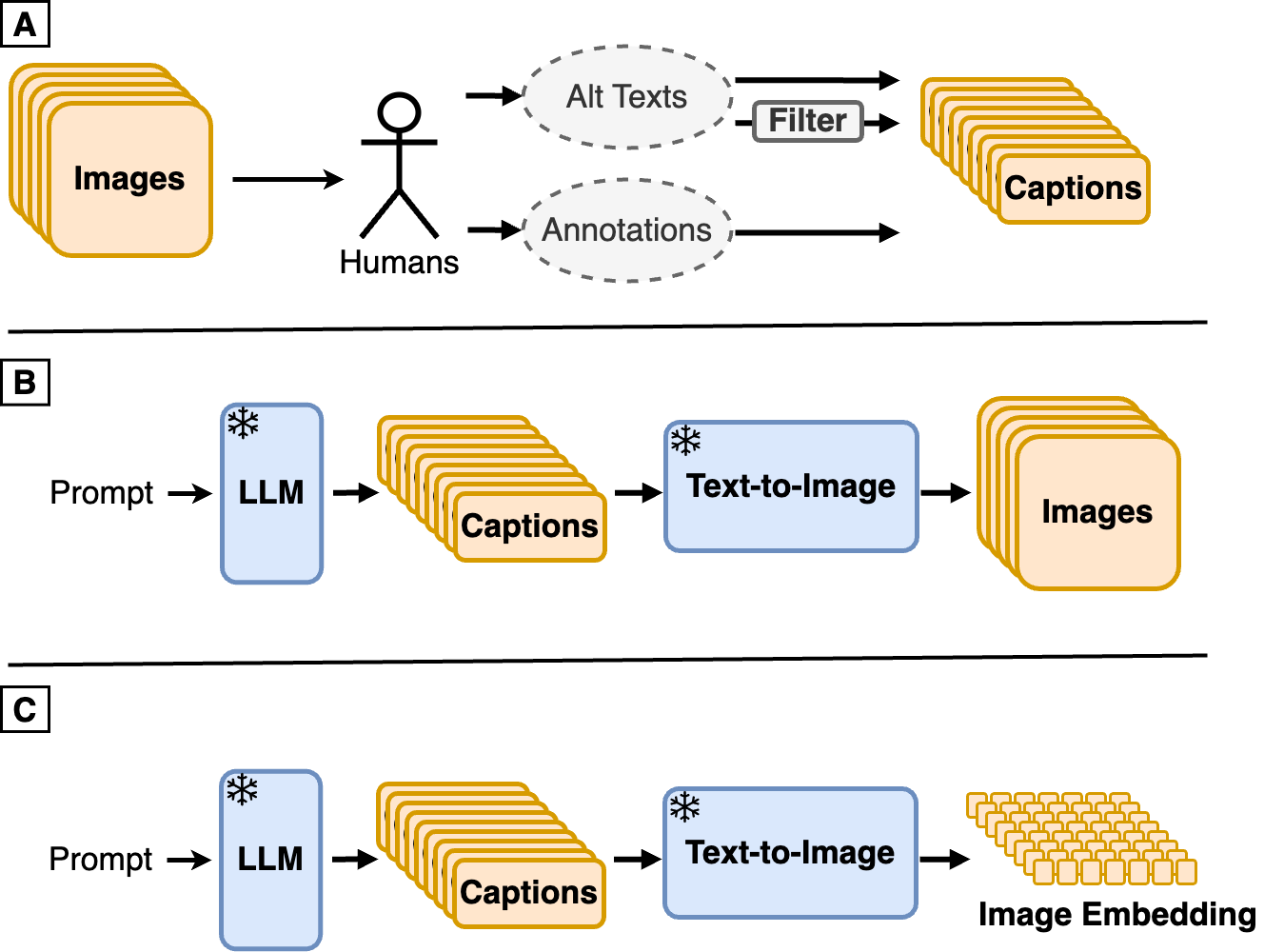
0
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
Read more6/10/2024
🔍
0
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
Read more5/24/2024