Demonstration of an Adversarial Attack Against a Multimodal Vision Language Model for Pathology Imaging

0
Sign in to get full access
Overview
- This paper investigates vulnerabilities in a multimodal vision-language model for pathology imaging, showing how it can be adversarially attacked.
- The researchers demonstrate techniques for generating adversarial examples that can fool the model into producing incorrect predictions or outputs.
- The findings highlight the need for improved robustness and security in these types of AI systems, especially in sensitive domains like healthcare.
Plain English Explanation
Artificial intelligence (AI) models that can analyze medical images and text together, known as multimodal vision-language models, are becoming more common in healthcare. However, these models can have vulnerabilities that allow them to be tricked or "attacked" in ways that cause them to make mistakes.
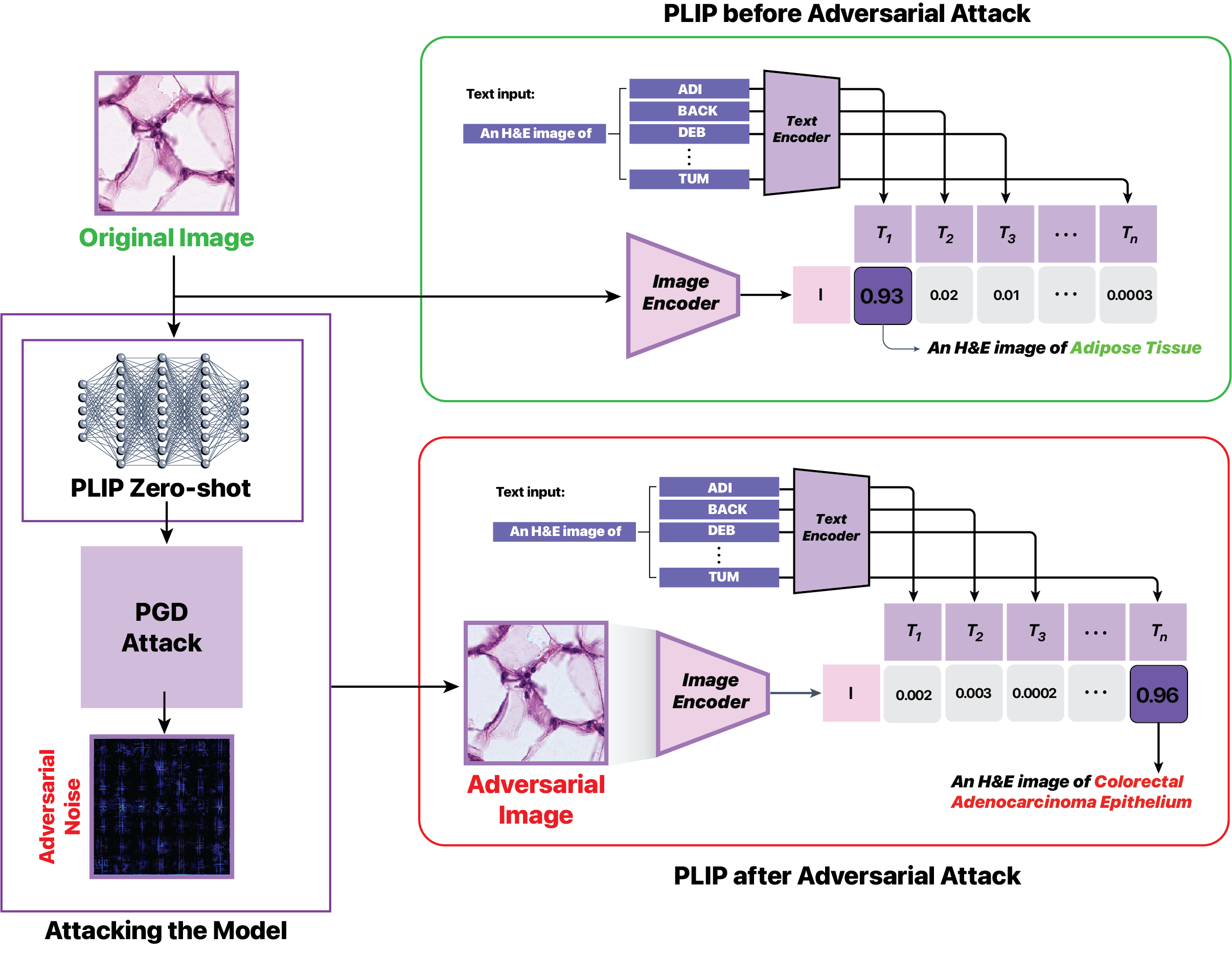
The researchers in this paper wanted to explore these vulnerabilities by intentionally trying to "attack" a multimodal model used for pathology imaging - the analysis of tissue samples to diagnose diseases. They developed techniques to generate "adversarial examples" - slightly modified images that would cause the model to output incorrect predictions, even though the changes to the images were nearly imperceptible to humans.
These findings are important because they highlight the need to make these AI models more robust and secure, especially when they are being used in sensitive medical settings. If the models can be easily fooled, it could lead to incorrect diagnoses or treatment decisions, which could have serious consequences for patients. The researchers hope their work will spur further efforts to improve the reliability and trustworthiness of these AI systems in healthcare.
Technical Explanation
The paper presents a study on adversarially attacking a multimodal vision-language model for computational pathology. The researchers developed techniques to generate adversarial examples - slightly modified images that can cause the model to output incorrect predictions, even though the changes to the images are nearly imperceptible to humans.
The team used a state-of-the-art multimodal model that was trained on a large dataset of pathology images and associated text descriptions. They then designed a threat model where the attacker has access to the target model and can generate adversarial examples.
The researchers developed several attack strategies, including adversarial perturbations that modify the input images, as well as latent space attacks that manipulate the internal representations of the model. They evaluated the effectiveness of these attacks on the multimodal model's performance on pathology tasks.
The results showed that the developed attacks were able to substantially degrade the model's performance, even with imperceptible changes to the input images. This highlights the need for improved robustness and security in these types of AI systems, especially in sensitive domains like healthcare.
Critical Analysis
The paper provides a comprehensive and technical analysis of vulnerabilities in a multimodal vision-language model for pathology imaging. The threat model and attack strategies developed by the researchers are well-designed and demonstrate the potential risks of these models being exploited.
One potential limitation of the study is that it focuses on a single model architecture and dataset. While the findings are likely relevant to other multimodal models, it would be valuable to see how the attacks generalize to different model types and datasets. Additionally, the paper does not provide much insight into the specific mechanisms by which the attacks degrade the model's performance, which could be an interesting area for further investigation.
More broadly, the paper raises important questions about the robustness and security of AI systems, especially in high-stakes domains like healthcare. As these technologies become more widely adopted, it is critical that researchers, developers, and end-users carefully consider the potential vulnerabilities and take proactive steps to mitigate them. This includes not only improving the technical defenses of the models, but also developing robust processes for deployment, monitoring, and oversight.
Conclusion
This paper presents a concerning exploration of vulnerabilities in a multimodal vision-language model for pathology imaging. The researchers demonstrated effective techniques for generating adversarial examples that can substantially degrade the model's performance, even with imperceptible changes to the input images.
The findings highlight the need for continued research and development to improve the robustness and security of these types of AI systems, especially when they are being used in sensitive domains like healthcare. As multimodal models become more prevalent, it is crucial that they are designed and deployed in a way that ensures their reliability and trustworthiness, in order to protect patients and support high-quality medical decision-making.
Overall, this paper contributes valuable insights to the ongoing efforts to make AI systems more secure and resilient in the face of adversarial attacks. Its implications extend beyond the specific domain of pathology imaging, serving as a cautionary tale for the broader AI community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Demonstration of an Adversarial Attack Against a Multimodal Vision Language Model for Pathology Imaging
Poojitha Thota, Jai Prakash Veerla, Partha Sai Guttikonda, Mohammad S. Nasr, Shirin Nilizadeh, Jacob M. Luber
In the context of medical artificial intelligence, this study explores the vulnerabilities of the Pathology Language-Image Pretraining (PLIP) model, a Vision Language Foundation model, under targeted attacks. Leveraging the Kather Colon dataset with 7,180 H&E images across nine tissue types, our investigation employs Projected Gradient Descent (PGD) adversarial perturbation attacks to induce misclassifications intentionally. The outcomes reveal a 100% success rate in manipulating PLIP's predictions, underscoring its susceptibility to adversarial perturbations. The qualitative analysis of adversarial examples delves into the interpretability challenges, shedding light on nuanced changes in predictions induced by adversarial manipulations. These findings contribute crucial insights into the interpretability, domain adaptation, and trustworthiness of Vision Language Models in medical imaging. The study emphasizes the pressing need for robust defenses to ensure the reliability of AI models. The source codes for this experiment can be found at https://github.com/jaiprakash1824/VLM_Adv_Attack.
Read more5/9/2024

0
Sample-agnostic Adversarial Perturbation for Vision-Language Pre-training Models
Haonan Zheng, Wen Jiang, Xinyang Deng, Wenrui Li
Recent studies on AI security have highlighted the vulnerability of Vision-Language Pre-training (VLP) models to subtle yet intentionally designed perturbations in images and texts. Investigating multimodal systems' robustness via adversarial attacks is crucial in this field. Most multimodal attacks are sample-specific, generating a unique perturbation for each sample to construct adversarial samples. To the best of our knowledge, it is the first work through multimodal decision boundaries to explore the creation of a universal, sample-agnostic perturbation that applies to any image. Initially, we explore strategies to move sample points beyond the decision boundaries of linear classifiers, refining the algorithm to ensure successful attacks under the top $k$ accuracy metric. Based on this foundation, in visual-language tasks, we treat visual and textual modalities as reciprocal sample points and decision hyperplanes, guiding image embeddings to traverse text-constructed decision boundaries, and vice versa. This iterative process consistently refines a universal perturbation, ultimately identifying a singular direction within the input space which is exploitable to impair the retrieval performance of VLP models. The proposed algorithms support the creation of global perturbations or adversarial patches. Comprehensive experiments validate the effectiveness of our method, showcasing its data, task, and model transferability across various VLP models and datasets. Code: https://github.com/LibertazZ/MUAP
Read more8/7/2024
🤯
0
Exploring Transferability of Multimodal Adversarial Samples for Vision-Language Pre-training Models with Contrastive Learning
Youze Wang, Wenbo Hu, Yinpeng Dong, Hanwang Zhang, Hang Su, Richang Hong
The integration of visual and textual data in Vision-Language Pre-training (VLP) models is crucial for enhancing vision-language understanding. However, the adversarial robustness of these models, especially in the alignment of image-text features, has not yet been sufficiently explored. In this paper, we introduce a novel gradient-based multimodal adversarial attack method, underpinned by contrastive learning, to improve the transferability of multimodal adversarial samples in VLP models. This method concurrently generates adversarial texts and images within imperceptive perturbation, employing both image-text and intra-modal contrastive loss. We evaluate the effectiveness of our approach on image-text retrieval and visual entailment tasks, using publicly available datasets in a black-box setting. Extensive experiments indicate a significant advancement over existing single-modal transfer-based adversarial attack methods and current multimodal adversarial attack approaches.
Read more7/23/2024

0
Probing the Robustness of Vision-Language Pretrained Models: A Multimodal Adversarial Attack Approach
Jiwei Guan, Tianyu Ding, Longbing Cao, Lei Pan, Chen Wang, Xi Zheng
Vision-language pretraining (VLP) with transformers has demonstrated exceptional performance across numerous multimodal tasks. However, the adversarial robustness of these models has not been thoroughly investigated. Existing multimodal attack methods have largely overlooked cross-modal interactions between visual and textual modalities, particularly in the context of cross-attention mechanisms. In this paper, we study the adversarial vulnerability of recent VLP transformers and design a novel Joint Multimodal Transformer Feature Attack (JMTFA) that concurrently introduces adversarial perturbations in both visual and textual modalities under white-box settings. JMTFA strategically targets attention relevance scores to disrupt important features within each modality, generating adversarial samples by fusing perturbations and leading to erroneous model predictions. Experimental results indicate that the proposed approach achieves high attack success rates on vision-language understanding and reasoning downstream tasks compared to existing baselines. Notably, our findings reveal that the textual modality significantly influences the complex fusion processes within VLP transformers. Moreover, we observe no apparent relationship between model size and adversarial robustness under our proposed attacks. These insights emphasize a new dimension of adversarial robustness and underscore potential risks in the reliable deployment of multimodal AI systems.
Read more8/27/2024