Demystifying the Compression of Mixture-of-Experts Through a Unified Framework
2406.02500
0
0

Abstract
Scaling large language models has revolutionized the performance across diverse domains, yet the continual growth in model size poses significant challenges for real-world deployment. The Mixture of Experts (MoE) approach addresses this by dynamically selecting and activating only a subset of experts, significantly reducing computational costs while maintaining high performance. However, MoE introduces potential redundancy (e.g., parameters) and extra costs (e.g., communication overhead). Despite numerous compression techniques developed for mitigating the redundancy in dense models, the compression of MoE remains under-explored. We first bridge this gap with a cutting-edge unified framework that not only seamlessly integrates mainstream compression methods but also helps systematically understand MoE compression. This framework approaches compression from two perspectives: Expert Slimming which compresses individual experts and Expert Trimming which removes structured modules. Within this framework, we explore the optimization space unexplored by existing methods,and further introduce aggressive Expert Trimming techniques, i.e., Layer Drop and Block Drop, to eliminate redundancy at larger scales. Based on these insights,we present a comprehensive recipe to guide practitioners in compressing MoE effectively. Extensive experimental results demonstrate the effectiveness of the compression methods under our framework and the proposed recipe, achieving a 6.05x speedup and only 20.0GB memory usage while maintaining over 92% of performance on Mixtral-8x7B.
Create account to get full access
Overview
- This paper presents a unified framework for understanding the compression of mixture-of-experts (MoE) models, which are a type of neural network architecture that combines multiple specialized "expert" models to solve complex tasks.
- The authors aim to demystify the compression of MoE models, providing insights into how these models can be efficiently compressed while maintaining their performance.
- The paper analyzes the trade-offs between the number of experts, the compression of individual experts, and the overall model performance, offering a comprehensive understanding of the compression dynamics in MoE models.
Plain English Explanation
The paper explores a type of artificial intelligence (AI) model called a "mixture-of-experts" (MoE). MoE models work by combining multiple specialized "expert" models, each of which is good at a specific task, to solve more complex problems. This approach can be very effective, but it also means the models can become large and unwieldy.
The researchers in this paper have developed a framework to help understand how MoE models can be compressed, or made smaller and more efficient, while still maintaining their high performance. They analyze the trade-offs involved, such as how reducing the number of experts or compressing the individual experts affects the overall model performance.
By providing a deeper understanding of the compression dynamics in MoE models, the paper aims to help researchers and engineers design more efficient and practical MoE-based AI systems. This could be particularly useful for deploying MoE models on resource-constrained devices or scaling up MoE-based language models.
Technical Explanation
The paper presents a unified framework for understanding the compression of mixture-of-experts (MoE) models. MoE models are a type of neural network architecture that combines multiple specialized "expert" models to solve complex tasks. The authors analyze the trade-offs between the number of experts, the compression of individual experts, and the overall model performance.
The researchers first provide a formal definition of the MoE model and its compression. They then derive a set of analytical results that characterize the compression-performance trade-offs in MoE models. These insights are validated through extensive experiments on various MoE-based models, including HyperMoE and Uni-MoE.
The paper also discusses the implications of their findings for practical MoE model design and compression, particularly in the context of large language models and sparse expert models. The authors provide guidelines and strategies for efficiently compressing MoE models while preserving their performance.
Critical Analysis
The paper provides a comprehensive and theoretically grounded approach to understanding the compression of MoE models. The authors' analytical framework offers valuable insights into the trade-offs involved in MoE compression, which can guide future research and practical applications of these models.
One potential limitation of the study is that it primarily focuses on the theoretical and empirical aspects of MoE compression, without delving deeply into the practical implications or real-world deployment challenges. For example, the paper does not address how the proposed compression techniques might interact with other model optimization strategies, such as hardware-aware design or specialized hardware acceleration.
Additionally, while the paper covers a range of MoE-based models, the experimental evaluation could be expanded to include a more diverse set of tasks, datasets, and model architectures to further validate the generalizability of the proposed framework.
Despite these minor limitations, the paper's contribution to the understanding of MoE compression is significant and will likely have a substantial impact on the continued development and deployment of these powerful AI models.
Conclusion
This paper presents a unified framework for demystifying the compression of mixture-of-experts (MoE) models, a type of neural network architecture that combines multiple specialized "expert" models to solve complex tasks. The authors provide a comprehensive analysis of the trade-offs between the number of experts, the compression of individual experts, and the overall model performance.
By offering a deeper understanding of the compression dynamics in MoE models, the paper can help researchers and engineers design more efficient and practical MoE-based AI systems. This could be particularly useful for deploying MoE models on resource-constrained devices or scaling up MoE-based language models, as the insights from this work can guide the development of compression strategies that maintain model performance.
Overall, the paper's contribution to the field of MoE compression is significant, and the proposed framework has the potential to drive further advancements in the design and optimization of these powerful AI architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Xudong Lu, Qi Liu, Yuhui Xu, Aojun Zhou, Siyuan Huang, Bo Zhang, Junchi Yan, Hongsheng Li
0
0
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
5/31/2024
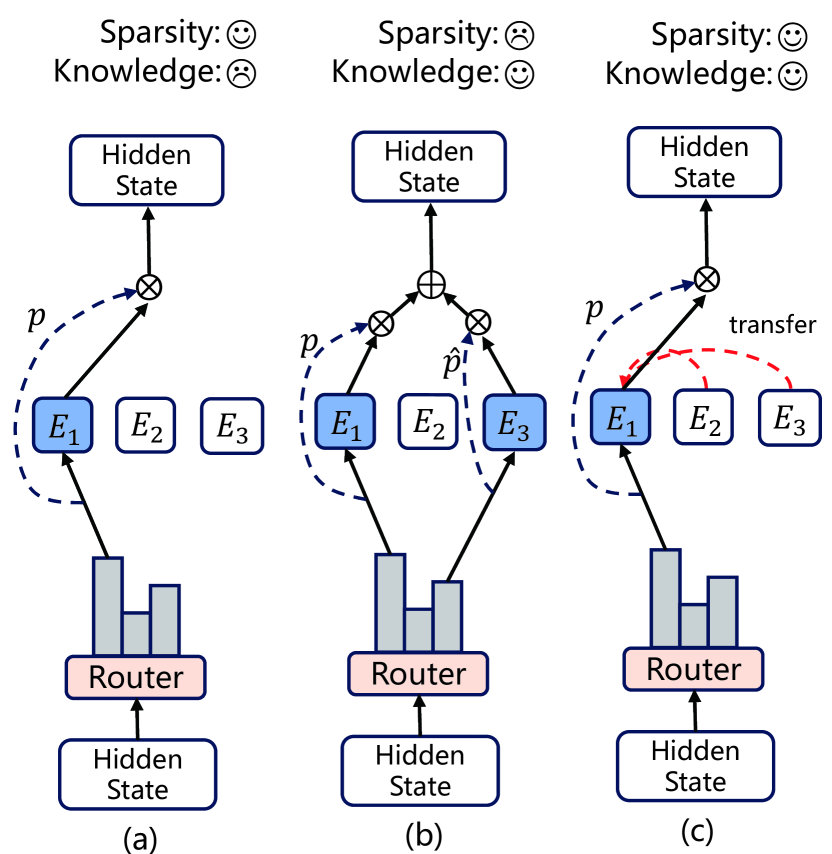
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024

A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
0
0
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
6/27/2024
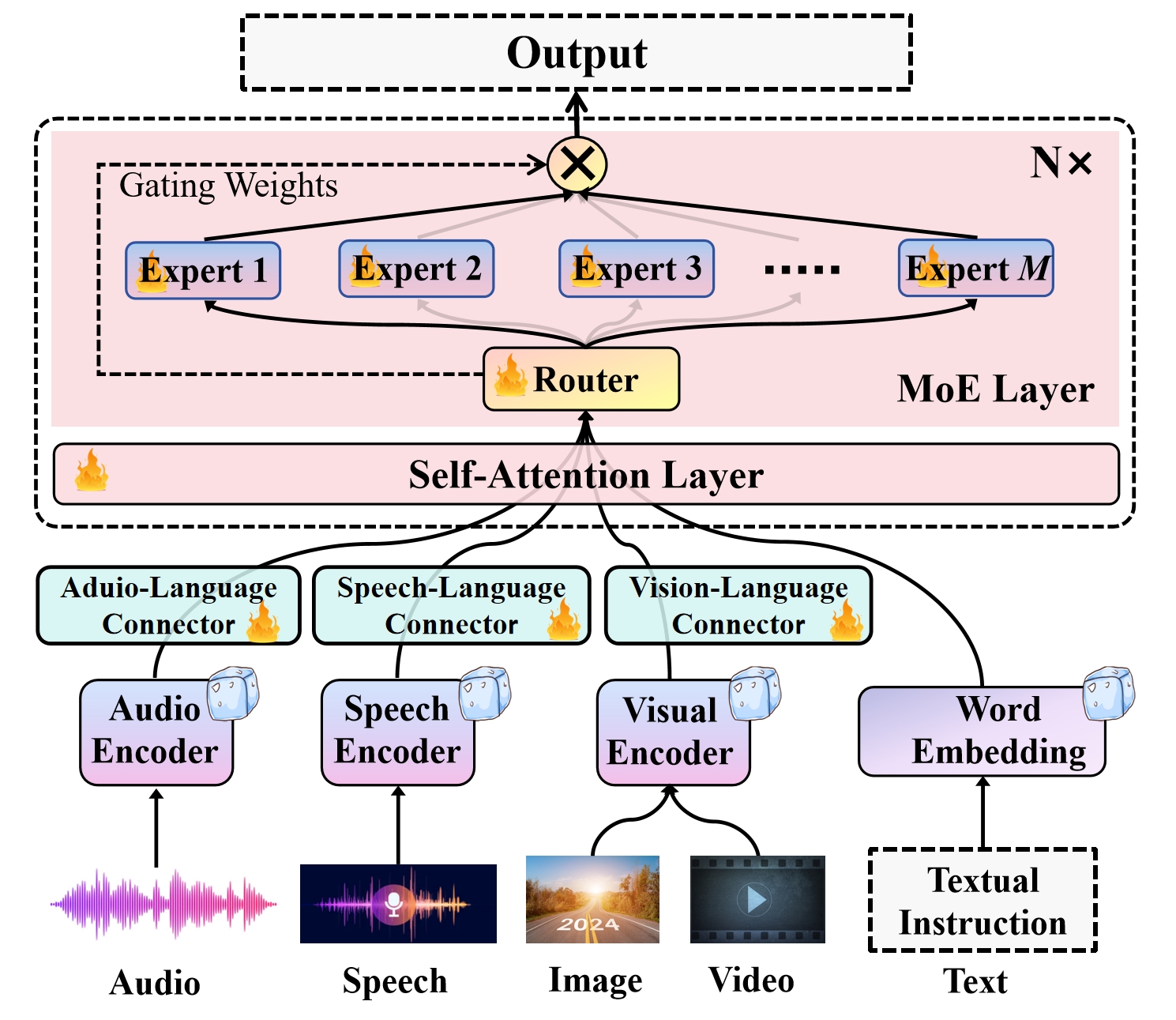
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, Min Zhang
0
0
Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
5/21/2024