In-depth analysis of recall initiators of medical devices with a Machine Learning-Natural language Processing workflow

0
💬
Sign in to get full access
Overview
- This study presents a machine learning and natural language processing (ML-NLP) tool to address the challenges in identifying and assessing medical device recall initiators.
- Conventional analysis tools are inadequate for processing large and diverse data to meet the growing expectations for effective recall management.
- The proposed ML-NLP tool can comprehensively and efficiently analyze medical device recall data from 2018 to 2024 to identify and assess the recall initiators.
Plain English Explanation
When a medical device is recalled, it's essential to understand what caused the recall in the first place. This is known as the "recall initiator." Accurately identifying and assessing these initiators is crucial for preventing future recalls and improving patient safety.
However, the conventional tools used for this task often struggle to handle the large volume and varied formats of data involved. This study introduces a new machine learning and natural language processing (ML-NLP) tool that can tackle these challenges more effectively.
The researchers used this ML-NLP tool to analyze medical device recall data from 2018 to 2024. The tool was able to identify and assess the recall initiators in a comprehensive and efficient manner, which can help practitioners quickly understand the reasons behind each recall.
The tool uses a clustering algorithm called DBSCAN to group similar recall initiators together, making it easier to spot patterns and trends. It also employs text similarity-based classification to provide insights at different management levels, from operational to strategic.
Overall, this ML-NLP tool can not only capture the details of each recall initiator but also help identify the connections between them. This can lead to more proactive and effective strategies for preventing medical device recalls in the future.
Technical Explanation
The researchers developed a machine learning and natural language processing (ML-NLP) tool to address the limitations of conventional analysis tools in identifying and assessing medical device recall initiators. They used this tool to analyze recall data from 2018 to 2024 from a public medical device recall database.
The key components of the ML-NLP tool include:
-
DBSCAN Clustering: The researchers employed the Density-Based Spatial Clustering of Applications with Noise (DBSCAN) algorithm to group similar recall initiators together, enabling practitioners to quickly identify the reasons behind each recall.
-
Text Similarity-based Classification: The tool also uses text similarity-based classification to provide insights at different management levels, from operational to strategic. This helps practitioners control the size of recall initiator groups and derive meaningful insights.
The results suggest that this ML-NLP tool can effectively capture the specific details of each recall initiator and uncover the connections between them. This can support risk identification and assessment in the medical device supply chain, leading to more proactive and comprehensive recall management strategies.
Critical Analysis
The study presents a promising approach to address the challenges in identifying and assessing medical device recall initiators, which is an important task for improving patient safety and supply chain management. The use of machine learning and natural language processing techniques, such as DBSCAN clustering and text similarity-based classification, appears to be a suitable solution for handling the large and diverse data involved.
However, the study does not provide detailed information on the performance and accuracy of the ML-NLP tool, which would be crucial for evaluating its practical value. Additionally, the researchers do not discuss any potential limitations or challenges in implementing the tool in real-world scenarios, such as the availability and quality of the recall data or the integration with existing medical device supply chain management systems.
Further research and validation would be beneficial to assess the scalability, robustness, and generalizability of the proposed approach, as well as to explore potential applications in other areas of medical data extraction and analysis. Engaging with medical device manufacturers and regulatory authorities could also provide valuable insights for refining the tool and ensuring its alignment with industry needs and best practices.
Conclusion
This study presents a novel machine learning and natural language processing (ML-NLP) tool that can effectively identify and assess medical device recall initiators, addressing the limitations of conventional analysis tools. The tool's ability to comprehensively and efficiently process large and diverse recall data can support more proactive and effective recall management strategies, ultimately improving patient safety and supply chain resilience.
While the study demonstrates the potential of this approach, further research and validation are needed to fully realize its practical benefits. Continued collaboration between researchers, medical device manufacturers, and regulatory authorities will be crucial in developing and refining such data-driven tools to enhance the medical device industry's ability to anticipate and respond to recall events.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
In-depth analysis of recall initiators of medical devices with a Machine Learning-Natural language Processing workflow
Yang Hu
Recall initiator identification and assessment are the preliminary steps to prevent medical device recall. Conventional analysis tools are inappropriate for processing massive and multi-formatted data comprehensively and completely to meet the higher expectations of delicacy management with the increasing overall data volume and textual data format. This study presents a bigdata-analytics-based machine learning-natural language processing work tool to address the shortcomings in dealing efficiency and data process versatility of conventional tools in the practical context of big data volume and muti data format. This study identified, assessed and analysed the medical device recall initiators according to the public medical device recall database from 2018 to 2024 with the ML-NLP tool. The results suggest that the unsupervised Density-Based Spatial Clustering of Applications with Noise (DBSCAN) clustering algorithm can present each single recall initiator in a specific manner, therefore helping practitioners to identify the recall reasons comprehensively and completely within a short time frame. This is then followed by text similarity-based textual classification to assist practitioners in controlling the group size of recall initiators and provide managerial insights from the operational to the tactical and strategical levels. This ML-NLP work tool can not only capture specific details of each recall initiator but also interpret the inner connection of each existing initiator and can be implemented for risk identification and assessment in the forward SC. Finally, this paper suggests some concluding remarks and presents future works. More proactive practices and control solutions for medical device recalls are expected in the future.
Read more6/18/2024
📈
0
Towards Efficient Patient Recruitment for Clinical Trials: Application of a Prompt-Based Learning Model
Mojdeh Rahmanian, Seyed Mostafa Fakhrahmad, Seyedeh Zahra Mousavi
Objective: Clinical trials are essential for advancing pharmaceutical interventions, but they face a bottleneck in selecting eligible participants. Although leveraging electronic health records (EHR) for recruitment has gained popularity, the complex nature of unstructured medical texts presents challenges in efficiently identifying participants. Natural Language Processing (NLP) techniques have emerged as a solution with a recent focus on transformer models. In this study, we aimed to evaluate the performance of a prompt-based large language model for the cohort selection task from unstructured medical notes collected in the EHR. Methods: To process the medical records, we selected the most related sentences of the records to the eligibility criteria needed for the trial. The SNOMED CT concepts related to each eligibility criterion were collected. Medical records were also annotated with MedCAT based on the SNOMED CT ontology. Annotated sentences including concepts matched with the criteria-relevant terms were extracted. A prompt-based large language model (Generative Pre-trained Transformer (GPT) in this study) was then used with the extracted sentences as the training set. To assess its effectiveness, we evaluated the model's performance using the dataset from the 2018 n2c2 challenge, which aimed to classify medical records of 311 patients based on 13 eligibility criteria through NLP techniques. Results: Our proposed model showed the overall micro and macro F measures of 0.9061 and 0.8060 which were among the highest scores achieved by the experiments performed with this dataset. Conclusion: The application of a prompt-based large language model in this study to classify patients based on eligibility criteria received promising scores. Besides, we proposed a method of extractive summarization with the aid of SNOMED CT ontology that can be also applied to other medical texts.
Read more4/26/2024
0
DeviceBERT: Applied Transfer Learning With Targeted Annotations and Vocabulary Enrichment to Identify Medical Device and Component Terminology in FDA Recall Summaries
Miriam Farrington
FDA Medical Device recalls are critical and time-sensitive events, requiring swift identification of impacted devices to inform the public of a recall event and ensure patient safety. The OpenFDA device recall dataset contains valuable information about ongoing device recall actions, but manually extracting relevant device information from the recall action summaries is a time-consuming task. Named Entity Recognition (NER) is a task in Natural Language Processing (NLP) that involves identifying and categorizing named entities in unstructured text. Existing NER models, including domain-specific models like BioBERT, struggle to correctly identify medical device trade names, part numbers and component terms within these summaries. To address this, we propose DeviceBERT, a medical device annotation, pre-processing and enrichment pipeline, which builds on BioBERT to identify and label medical device terminology in the device recall summaries with improved accuracy. Furthermore, we demonstrate that our approach can be applied effectively for performing entity recognition tasks where training data is limited or sparse.
Read more6/11/2024
0
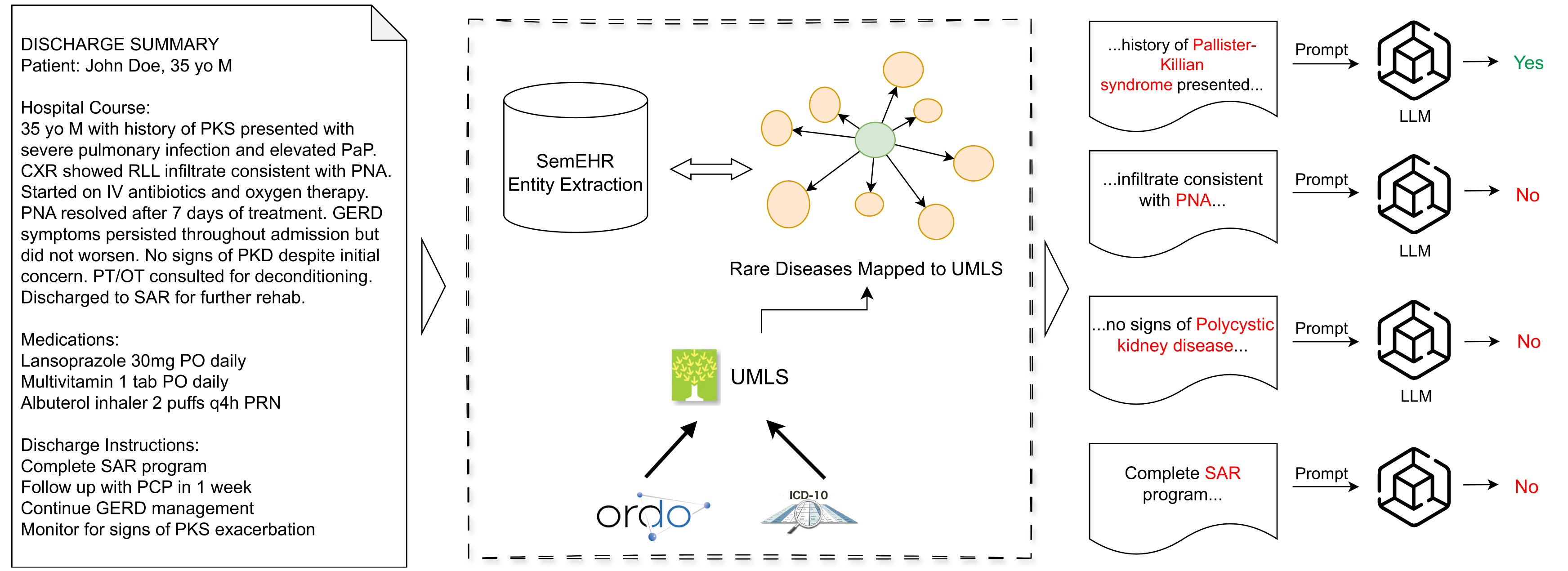
Retrieving and Refining: A Hybrid Framework with Large Language Models for Rare Disease Identification
Jinge Wu, Hang Dong, Zexi Li, Arijit Patra, Honghan Wu
The infrequency and heterogeneity of clinical presentations in rare diseases often lead to underdiagnosis and their exclusion from structured datasets. This necessitates the utilization of unstructured text data for comprehensive analysis. However, the manual identification from clinical reports is an arduous and intrinsically subjective task. This study proposes a novel hybrid approach that synergistically combines a traditional dictionary-based natural language processing (NLP) tool with the powerful capabilities of large language models (LLMs) to enhance the identification of rare diseases from unstructured clinical notes. We comprehensively evaluate various prompting strategies on six large language models (LLMs) of varying sizes and domains (general and medical). This evaluation encompasses zero-shot, few-shot, and retrieval-augmented generation (RAG) techniques to enhance the LLMs' ability to reason about and understand contextual information in patient reports. The results demonstrate effectiveness in rare disease identification, highlighting the potential for identifying underdiagnosed patients from clinical notes.
Read more5/20/2024