Depth-guided Texture Diffusion for Image Semantic Segmentation

0

Sign in to get full access
Overview
- This research paper presents a novel approach for improving image semantic segmentation using depth-guided texture diffusion.
- The key idea is to leverage depth information to guide the diffusion of texture features, which can then be used to enhance the performance of semantic segmentation models.
- The proposed method outperforms existing state-of-the-art techniques on several benchmark datasets, demonstrating the effectiveness of incorporating depth cues for this task.
Plain English Explanation
The researchers developed a new way to improve the accuracy of image segmentation, which is the process of dividing an image into different meaningful parts or "segments." Image segmentation is an important task in computer vision, with applications ranging from self-driving cars to medical image analysis.
To enhance segmentation performance, the researchers used information about the depth or distance of objects in the image. Depth can provide valuable cues about the spatial arrangement and texture of objects, which are important for accurately distinguishing different elements in a scene.
The key innovation is the use of "texture diffusion" - a technique that spreads or diffuses texture information throughout the image, guided by the depth data. This allows the segmentation model to better capture the relationship between an object's appearance and its location in 3D space.
By incorporating this depth-guided texture diffusion, the researchers were able to achieve better segmentation results compared to existing methods that do not explicitly leverage depth information. This suggests that depth data can be a powerful signal for improving image understanding and analysis tasks.
Technical Explanation
The proposed Depth-guided Texture Diffusion (DTD) approach consists of several key components:
-
Depth Estimation: The method first estimates the depth map of the input image using a pre-trained monocular depth estimation model.
-
Texture Feature Extraction: Visual texture features are extracted from the input image using a pre-trained convolutional neural network (CNN).
-
Depth-guided Texture Diffusion: The texture features are then diffused across the image, with the depth map used to guide the diffusion process. This helps propagate texture information based on the spatial arrangement of objects.
-
Segmentation Head: The diffused texture features are then fed into a segmentation network, which produces the final semantic segmentation output.
The researchers evaluated their DTD approach on several standard benchmarks for image semantic segmentation, including PASCAL VOC and Cityscapes. They showed that incorporating depth-guided texture diffusion can significantly improve performance compared to segmentation models that do not use depth information.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed DTD approach, with experiments on multiple datasets and comparisons to state-of-the-art methods. The results demonstrate the clear benefits of leveraging depth cues to enhance semantic segmentation.
However, the paper does not discuss potential limitations or caveats of the DTD method. For example, the approach relies on the availability of accurate depth estimation, which may not always be feasible, especially in challenging real-world scenarios. Additionally, the computational overhead of the depth estimation and texture diffusion steps may limit the practical deployment of this technique.
Further research could explore ways to make the DTD method more robust to depth estimation errors or to optimize its computational efficiency. Investigating the transferability of the depth-guided texture features to other computer vision tasks would also be an interesting direction for future work.
Conclusion
This research paper introduces a novel Depth-guided Texture Diffusion (DTD) approach that leverages depth information to improve the performance of image semantic segmentation. By diffusing texture features based on spatial cues provided by the depth map, the method can better capture the relationship between object appearance and 3D structure.
The results demonstrate the effectiveness of this depth-guided approach, which outperforms existing state-of-the-art segmentation techniques on multiple benchmark datasets. This work highlights the importance of incorporating depth information for enhancing image understanding tasks and suggests promising avenues for future research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Depth-guided Texture Diffusion for Image Semantic Segmentation
Wei Sun, Yuan Li, Qixiang Ye, Jianbin Jiao, Yanzhao Zhou
Depth information provides valuable insights into the 3D structure especially the outline of objects, which can be utilized to improve the semantic segmentation tasks. However, a naive fusion of depth information can disrupt feature and compromise accuracy due to the modality gap between the depth and the vision. In this work, we introduce a Depth-guided Texture Diffusion approach that effectively tackles the outlined challenge. Our method extracts low-level features from edges and textures to create a texture image. This image is then selectively diffused across the depth map, enhancing structural information vital for precisely extracting object outlines. By integrating this enriched depth map with the original RGB image into a joint feature embedding, our method effectively bridges the disparity between the depth map and the image, enabling more accurate semantic segmentation. We conduct comprehensive experiments across diverse, commonly-used datasets spanning a wide range of semantic segmentation tasks, including Camouflaged Object Detection (COD), Salient Object Detection (SOD), and indoor semantic segmentation. With source-free estimated depth or depth captured by depth cameras, our method consistently outperforms existing baselines and achieves new state-of-theart results, demonstrating the effectiveness of our Depth-guided Texture Diffusion for image semantic segmentation.
Read more8/20/2024
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
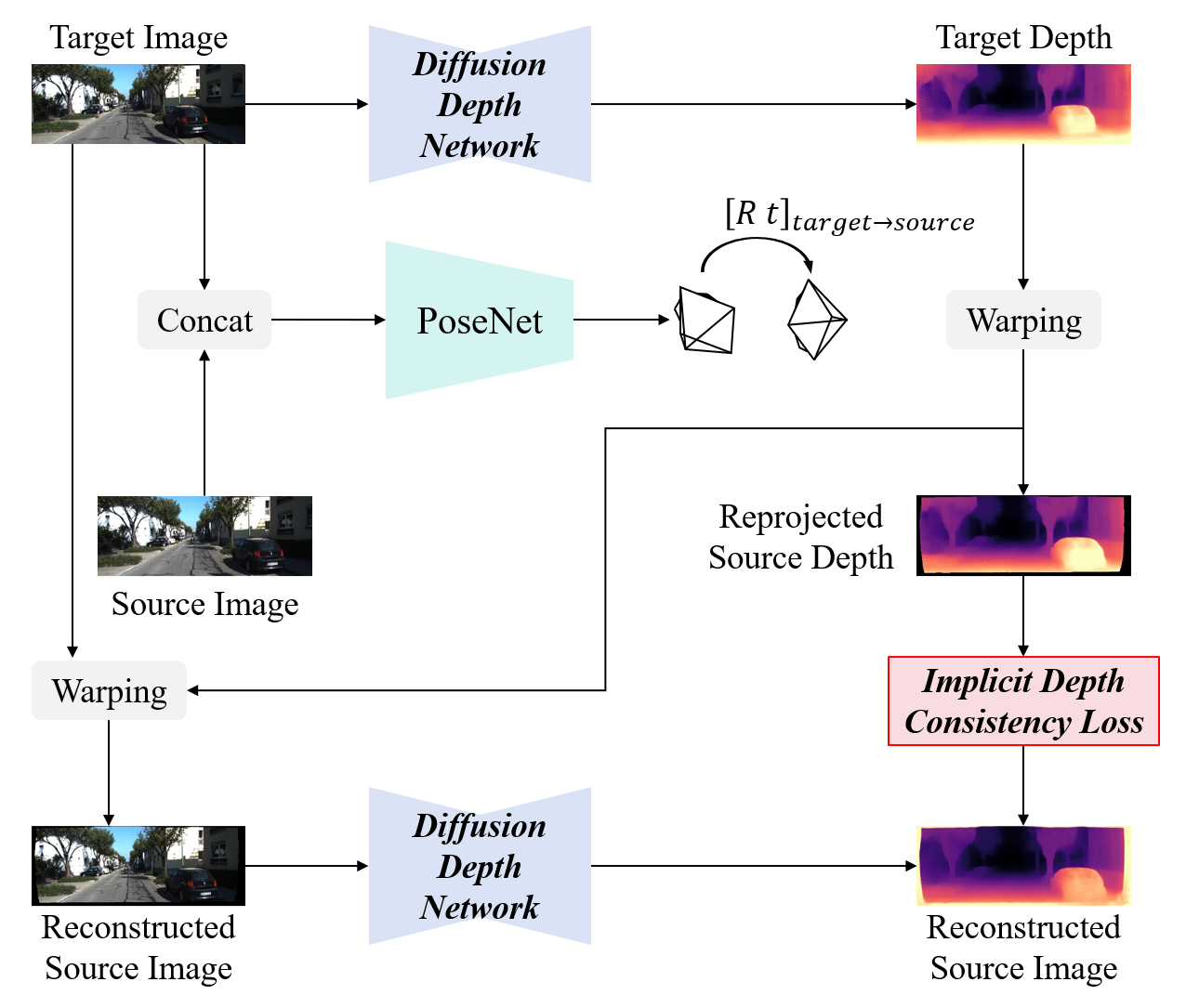
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024

0
Texture-guided Coding for Deep Features
Lei Xiong, Xin Luo, Zihao Wang, Chaofan He, Shuyuan Zhu, Bing Zeng
With the rapid development of machine vision technology in recent years, many researchers have begun to focus on feature compression that is better suited for machine vision tasks. The target of feature compression is deep features, which arise from convolution in the middle layer of a pre-trained convolutional neural network. However, due to the large volume of data and high level of abstraction of deep features, their application is primarily limited to machine-centric scenarios, which poses significant constraints in situations requiring human-computer interaction. This paper investigates features and textures and proposes a texture-guided feature compression strategy based on their characteristics. Specifically, the strategy comprises feature layers and texture layers. The feature layers serve the machine, including a feature selection module and a feature reconstruction network. With the assistance of texture images, they selectively compress and transmit channels relevant to visual tasks, reducing feature data while providing high-quality features for the machine. The texture layers primarily serve humans and consist of an image reconstruction network. This image reconstruction network leverages features and texture images to reconstruct preview images for humans. Our method fully exploits the characteristics of texture and features. It eliminates feature redundancy, reconstructs high-quality preview images for humans, and supports decision-making. The experimental results demonstrate excellent performance when employing our proposed method to compress the deep features.
Read more5/31/2024

0
Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Yuxiang Ji, Boyong He, Chenyuan Qu, Zhuoyue Tan, Chuan Qin, Liaoni Wu
Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84%$ mIoU across various datasets. The implementation code will be released soon.
Read more6/4/2024