Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment
2406.17957
0
0
Abstract
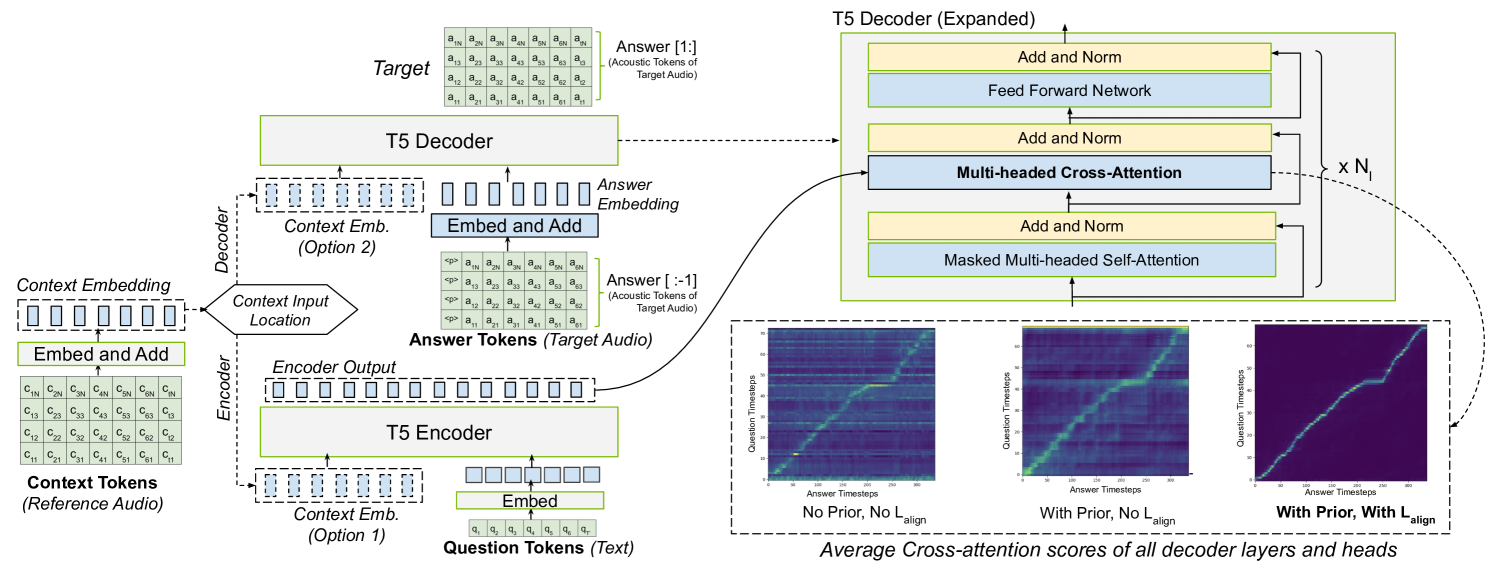
Large Language Model (LLM) based text-to-speech (TTS) systems have demonstrated remarkable capabilities in handling large speech datasets and generating natural speech for new speakers. However, LLM-based TTS models are not robust as the generated output can contain repeating words, missing words and mis-aligned speech (referred to as hallucinations or attention errors), especially when the text contains multiple occurrences of the same token. We examine these challenges in an encoder-decoder transformer model and find that certain cross-attention heads in such models implicitly learn the text and speech alignment when trained for predicting speech tokens for a given text. To make the alignment more robust, we propose techniques utilizing CTC loss and attention priors that encourage monotonic cross-attention over the text tokens. Our guided attention training technique does not introduce any new learnable parameters and significantly improves robustness of LLM-based TTS models.
Create account to get full access
Overview
- This paper proposes a novel approach to improving the robustness of large language model (LLM)-based speech synthesis by learning monotonic alignment between text and audio.
- The key idea is to enforce a monotonic relationship between the input text and the generated audio, which can help mitigate issues like mispronunciation and misalignment.
- The authors introduce a monotonic alignment module that can be integrated into existing LLM-based speech synthesis models, and evaluate its performance on several benchmark datasets.
Plain English Explanation
The paper is about making speech synthesis systems, which convert text into human-like speech, more reliable and accurate. Current speech synthesis models, especially those based on large language models (LLMs), can sometimes struggle with properly aligning the generated audio to the input text, leading to issues like mispronounced words or mismatched timing.
To address this, the researchers developed a new module that can be added to LLM-based speech synthesis models. This module enforces a monotonic alignment between the input text and the generated audio, ensuring a direct and consistent mapping. By doing this, the model is less likely to make mistakes in pronouncing words or synchronizing the audio with the text.
The authors tested this approach on several standard speech synthesis benchmarks and found that it significantly improves the robustness and quality of the generated speech, compared to existing LLM-based models. This could be particularly useful for applications like text-to-speech or zero-shot speech synthesis, where the ability to reliably convert text to natural-sounding audio is crucial.
Technical Explanation
The paper introduces a new method for improving the robustness of LLM-based speech synthesis models by incorporating a monotonic alignment module. This module enforces a direct, one-to-one mapping between the input text and the generated audio, addressing issues like mispronunciation and misalignment that can arise in standard LLM-based approaches.
The key innovation is the use of a monotonic attention mechanism, which ensures that the model's attention weights increase monotonically as it generates the audio output. This prevents the model from skipping or repeating parts of the input text, leading to more accurate and consistent text-to-speech conversion.
The authors integrate this monotonic alignment module into an existing LLM-based speech synthesis model, and evaluate its performance on several benchmark datasets, including VCTK and LJSpeech. Their results show that the proposed approach significantly outperforms the baseline LLM-based model in terms of both objective metrics (e.g., mel-cepstral distortion) and subjective human evaluations of speech quality and naturalness.
The authors also discuss potential limitations of their work, such as the need for further research on extending the monotonic alignment approach to handle more complex linguistic phenomena, such as long-range dependencies or prosodic features. They also note that the performance of the proposed method may be sensitive to the specific LLM used as the backbone of the speech synthesis model.
Critical Analysis
The paper presents a compelling approach to improving the robustness of LLM-based speech synthesis by enforcing monotonic alignment between text and audio. The key strength of the method is its simplicity and effectiveness, as the authors demonstrate significant performance gains on standard benchmarks without introducing substantial additional complexity.
One potential limitation is the reliance on a specific type of monotonic attention mechanism, which may not be the only or the best way to achieve the desired alignment properties. It would be interesting to see if other approaches, such as attention-constrained inference or denoising language models, could also be effectively incorporated into LLM-based speech synthesis to improve robustness.
Additionally, the authors acknowledge the need for further research on extending the monotonic alignment approach to handle more complex linguistic phenomena. It would be valuable to see how the proposed method performs on a wider range of speech synthesis tasks, such as multi-speaker or emotional speech generation, and to explore potential ways to make the approach more versatile and adaptable.
Overall, this paper presents a promising step towards more robust and reliable LLM-based speech synthesis, and the monotonic alignment module could be a valuable tool for researchers and practitioners working in this field.
Conclusion
The paper introduces a novel approach to improving the robustness of LLM-based speech synthesis by incorporating a monotonic alignment module. By enforcing a direct, one-to-one mapping between input text and generated audio, the proposed method helps mitigate issues like mispronunciation and misalignment that can plague current LLM-based speech synthesis models.
The authors demonstrate the effectiveness of their approach through extensive evaluations on standard speech synthesis benchmarks, showing significant improvements in both objective and subjective measures of speech quality. While the method has some limitations and potential areas for further research, it represents an important step forward in enhancing the reliability and accuracy of text-to-speech conversion, with important implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Attention-Constrained Inference for Robust Decoder-Only Text-to-Speech
Hankun Wang, Chenpeng Du, Yiwei Guo, Shuai Wang, Xie Chen, Kai Yu
0
0
Recent popular decoder-only text-to-speech models are known for their ability of generating natural-sounding speech. However, such models sometimes suffer from word skipping and repeating due to the lack of explicit monotonic alignment constraints. In this paper, we notice from the attention maps that some particular attention heads of the decoder-only model indicate the alignments between speech and text. We call the attention maps of those heads Alignment-Emerged Attention Maps (AEAMs). Based on this discovery, we propose a novel inference method without altering the training process, named Attention-Constrained Inference (ACI), to facilitate monotonic synthesis. It first identifies AEAMs using the Attention Sweeping algorithm and then applies constraining masks on AEAMs. Our experimental results on decoder-only TTS model VALL-E show that the WER of synthesized speech is reduced by up to 20.5% relatively with ACI while the naturalness and speaker similarity are comparable.
5/1/2024

Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Th'eodor Lemerle, Nicolas Obin, Axel Roebel
0
0
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
6/12/2024

VALL-E R: Robust and Efficient Zero-Shot Text-to-Speech Synthesis via Monotonic Alignment
Bing Han, Long Zhou, Shujie Liu, Sanyuan Chen, Lingwei Meng, Yanming Qian, Yanqing Liu, Sheng Zhao, Jinyu Li, Furu Wei
0
0
With the help of discrete neural audio codecs, large language models (LLM) have increasingly been recognized as a promising methodology for zero-shot Text-to-Speech (TTS) synthesis. However, sampling based decoding strategies bring astonishing diversity to generation, but also pose robustness issues such as typos, omissions and repetition. In addition, the high sampling rate of audio also brings huge computational overhead to the inference process of autoregression. To address these issues, we propose VALL-E R, a robust and efficient zero-shot TTS system, building upon the foundation of VALL-E. Specifically, we introduce a phoneme monotonic alignment strategy to strengthen the connection between phonemes and acoustic sequence, ensuring a more precise alignment by constraining the acoustic tokens to match their associated phonemes. Furthermore, we employ a codec-merging approach to downsample the discrete codes in shallow quantization layer, thereby accelerating the decoding speed while preserving the high quality of speech output. Benefiting from these strategies, VALL-E R obtains controllablity over phonemes and demonstrates its strong robustness by approaching the WER of ground truth. In addition, it requires fewer autoregressive steps, with over 60% time reduction during inference. This research has the potential to be applied to meaningful projects, including the creation of speech for those affected by aphasia. Audio samples will be available at: https://aka.ms/valler.
6/13/2024
DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment
Ke-Han Lu, Zhehuai Chen, Szu-Wei Fu, He Huang, Boris Ginsburg, Yu-Chiang Frank Wang, Hung-yi Lee
0
0
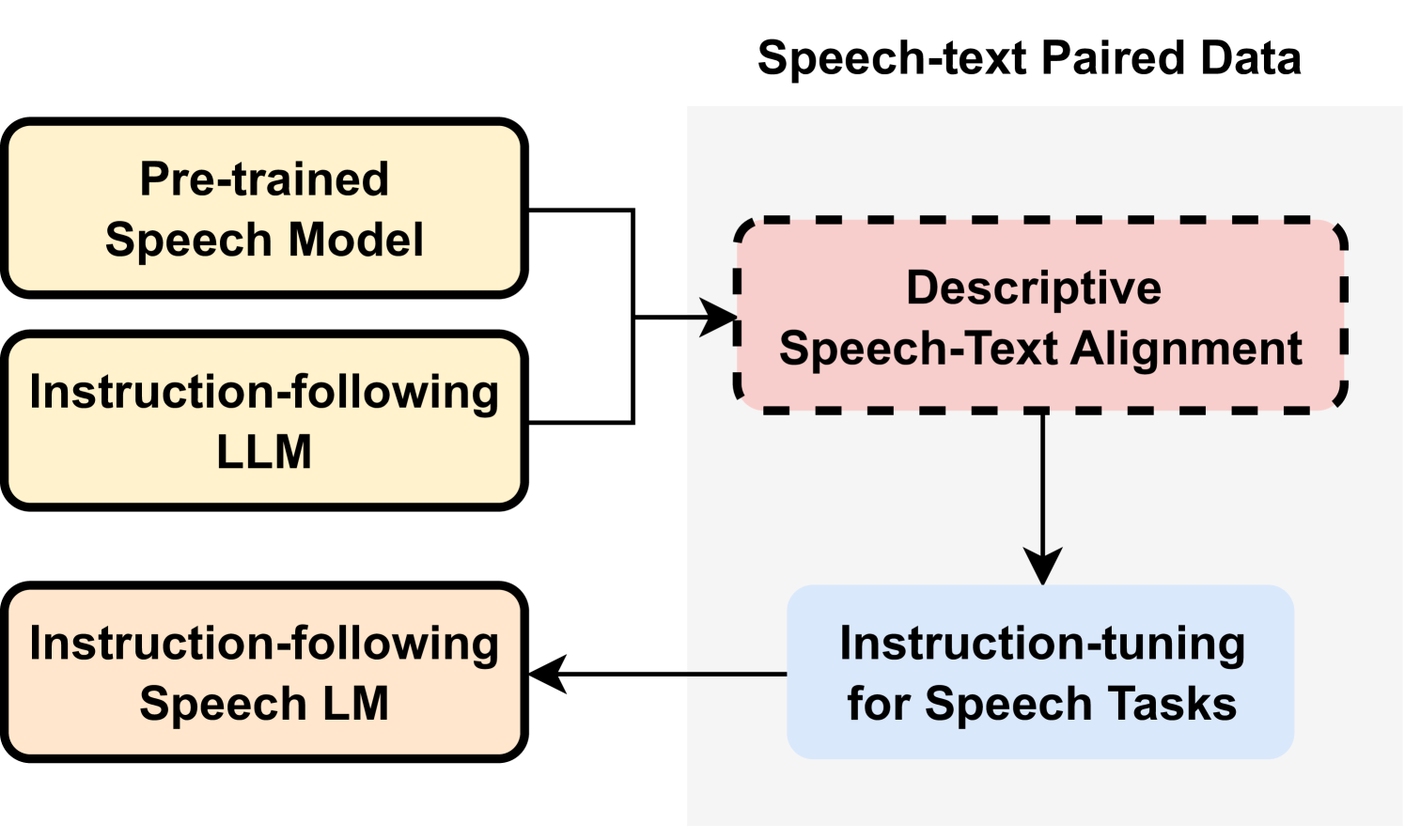
Recent speech language models (SLMs) typically incorporate pre-trained speech models to extend the capabilities from large language models (LLMs). In this paper, we propose a Descriptive Speech-Text Alignment approach that leverages speech captioning to bridge the gap between speech and text modalities, enabling SLMs to interpret and generate comprehensive natural language descriptions, thereby facilitating the capability to understand both linguistic and non-linguistic features in speech. Enhanced with the proposed approach, our model demonstrates superior performance on the Dynamic-SUPERB benchmark, particularly in generalizing to unseen tasks. Moreover, we discover that the aligned model exhibits a zero-shot instruction-following capability without explicit speech instruction tuning. These findings highlight the potential to reshape instruction-following SLMs by incorporating rich, descriptive speech captions.
6/28/2024