DetermLR: Augmenting LLM-based Logical Reasoning from Indeterminacy to Determinacy

0
🔍
Sign in to get full access
Overview
- Researchers propose a new approach called DetermLR to enhance the reasoning capabilities of large language models (LLMs)
- DetermLR models the reasoning process as an evolution from indeterminate to determinate conditions, guiding LLMs to convert uncertain data into reliable insights
- DetermLR outperforms existing multi-step reasoning methods on various logical reasoning benchmarks, demonstrating higher accuracy with fewer reasoning steps
Plain English Explanation
Large language models (LLMs) have made significant strides in reasoning tasks, but they still face challenges. Previous research has tried to enhance their reasoning by modeling the steps using predefined structures like chains, trees, or graphs. However, these preset structures may not adapt well to diverse tasks, and LLMs may struggle to precisely exploit known conditions to derive new ones or effectively leverage their past reasoning experiences.
To address these issues, the researchers introduce DetermLR, a new perspective that views the reasoning process as an evolution from indeterminacy to determinacy. First, they categorize the known conditions into two types: determinate and indeterminate premises. This provides an overall direction for the reasoning process and guides the LLMs in converting uncertain data into progressively more reliable insights.
DetermLR also uses quantitative measurements to prioritize the most relevant premises, helping the LLMs explore new insights more efficiently. Furthermore, it automates the storage and extraction of available premises and reasoning paths, preserving historical reasoning details for subsequent steps.
The researchers' comprehensive experiments show that DetermLR outperforms existing multi-step reasoning methods on various logical reasoning benchmarks. It achieves higher accuracy with fewer reasoning steps, highlighting its superior efficiency and effectiveness in solving these tasks.
Technical Explanation
The researchers propose DetermLR, a novel approach to enhance the reasoning capabilities of large language models (LLMs). Unlike previous methods that have focused on modeling reasoning steps using predefined structures like chains, trees, or graphs, DetermLR rethinks the reasoning process as an evolution from indeterminacy to determinacy.
First, DetermLR categorizes the known conditions into two types: determinate and indeterminate premises. This provides an overall direction for the reasoning process and guides the LLMs in converting uncertain data into progressively more determinate insights.
To prioritize the most relevant premises, DetermLR leverages quantitative measurements to explore new insights more efficiently. Additionally, it automates the storage and extraction of available premises and reasoning paths, preserving historical reasoning details for subsequent reasoning steps.
The researchers conduct comprehensive experiments on various logical reasoning benchmarks, including LogiQA, ProofWriter, FOLIO, PrOntoQA, and LogicalDeduction. The results demonstrate that DetermLR outperforms all baselines, achieving higher accuracy with fewer reasoning steps compared to previous multi-step reasoning methods.
Critical Analysis
The researchers have made a significant contribution to enhancing the reasoning capabilities of LLMs, but their approach is not without limitations. While DetermLR has shown promising results on logical reasoning tasks, it remains to be seen how well it would perform on more complex, open-ended reasoning problems that may not fit neatly into the determinate-indeterminate premise framework.
Additionally, the paper does not provide a detailed analysis of the types of errors or failure modes that the DetermLR approach may encounter. Further investigation into the specific weaknesses or biases of the model would be valuable for understanding its limitations and guiding future research.
The researchers also acknowledge that their work is focused on logical reasoning tasks, and it is unclear how well the DetermLR approach would translate to other types of reasoning, such as commonsense or analogical reasoning. Exploring the generalizability of the method to a wider range of reasoning tasks would be an important next step.
Overall, the DetermLR approach represents an important step forward in the quest to build more capable and reliable reasoning systems. However, as with any research, there is still room for further exploration and refinement to address the remaining challenges in this field.
Conclusion
The researchers have proposed a novel approach called DetermLR to enhance the reasoning capabilities of large language models (LLMs). By modeling the reasoning process as an evolution from indeterminacy to determinacy, DetermLR guides LLMs in converting uncertain data into progressively more reliable insights.
The comprehensive experimental results demonstrate that DetermLR outperforms existing multi-step reasoning methods on various logical reasoning benchmarks, achieving higher accuracy with fewer reasoning steps. This highlights the superior efficiency and effectiveness of the DetermLR approach in solving logical reasoning tasks.
While the DetermLR method represents an important advancement in the field, further research is needed to explore its generalizability to a wider range of reasoning problems and address any remaining limitations. Nonetheless, this work represents a significant step forward in the ongoing quest to build more capable and trustworthy reasoning systems powered by large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
DetermLR: Augmenting LLM-based Logical Reasoning from Indeterminacy to Determinacy
Hongda Sun, Weikai Xu, Wei Liu, Jian Luan, Bin Wang, Shuo Shang, Ji-Rong Wen, Rui Yan
Recent advances in large language models (LLMs) have revolutionized the landscape of reasoning tasks. To enhance the capabilities of LLMs to emulate human reasoning, prior studies have focused on modeling reasoning steps using various thought structures like chains, trees, or graphs. However, LLM-based reasoning still encounters the following challenges: (1) Limited adaptability of preset structures to diverse tasks; (2) Insufficient precision in exploiting known conditions to derive new ones; and (3) Inadequate consideration of historical reasoning experiences for subsequent reasoning steps. To this end, we propose DetermLR, a novel perspective that rethinks the reasoning process as an evolution from indeterminacy to determinacy. First, we categorize known conditions into two types: determinate and indeterminate premises This provides an oveall direction for the reasoning process and guides LLMs in converting indeterminate data into progressively determinate insights. Subsequently, we leverage quantitative measurements to prioritize more relevant premises to explore new insights. Furthermore, we automate the storage and extraction of available premises and reasoning paths with reasoning memory, preserving historical reasoning details for subsequent reasoning steps. Comprehensive experimental results demonstrate that DetermLR surpasses all baselines on various logical reasoning benchmarks: LogiQA, ProofWriter, FOLIO, PrOntoQA, and LogicalDeduction. Compared to previous multi-step reasoning methods, DetermLR achieves higher accuracy with fewer reasoning steps, highlighting its superior efficiency and effectiveness in solving logical reasoning tasks.
Read more5/28/2024

0
Inductive or Deductive? Rethinking the Fundamental Reasoning Abilities of LLMs
Kewei Cheng, Jingfeng Yang, Haoming Jiang, Zhengyang Wang, Binxuan Huang, Ruirui Li, Shiyang Li, Zheng Li, Yifan Gao, Xian Li, Bing Yin, Yizhou Sun
Reasoning encompasses two typical types: deductive reasoning and inductive reasoning. Despite extensive research into the reasoning capabilities of Large Language Models (LLMs), most studies have failed to rigorously differentiate between inductive and deductive reasoning, leading to a blending of the two. This raises an essential question: In LLM reasoning, which poses a greater challenge - deductive or inductive reasoning? While the deductive reasoning capabilities of LLMs, (i.e. their capacity to follow instructions in reasoning tasks), have received considerable attention, their abilities in true inductive reasoning remain largely unexplored. To investigate into the true inductive reasoning capabilities of LLMs, we propose a novel framework, SolverLearner. This framework enables LLMs to learn the underlying function (i.e., $y = f_w(x)$), that maps input data points $(x)$ to their corresponding output values $(y)$, using only in-context examples. By focusing on inductive reasoning and separating it from LLM-based deductive reasoning, we can isolate and investigate inductive reasoning of LLMs in its pure form via SolverLearner. Our observations reveal that LLMs demonstrate remarkable inductive reasoning capabilities through SolverLearner, achieving near-perfect performance with ACC of 1 in most cases. Surprisingly, despite their strong inductive reasoning abilities, LLMs tend to relatively lack deductive reasoning capabilities, particularly in tasks involving ``counterfactual'' reasoning.
Read more8/9/2024

0
Reliable Reasoning Beyond Natural Language
Nasim Borazjanizadeh, Steven T. Piantadosi
Despite their linguistic competence, Large Language models (LLMs) often exhibit limitations in their ability to reason reliably and flexibly. To address this, we propose a neurosymbolic approach that prompts LLMs to extract and encode all relevant information from a problem statement as logical code statements, and then use a logic programming language (Prolog) to conduct the iterative computations of explicit deductive reasoning. Our approach significantly enhances the performance of LLMs on the standard mathematical reasoning benchmark, GSM8k, and the Navigate dataset from the BIG-bench dataset. Additionally, we introduce a novel dataset, the Non-Linear Reasoning (NLR) dataset, consisting of 55 unique word problems that target the shortcomings of the next token prediction paradigm of LLMs and require complex non-linear reasoning but only basic arithmetic skills to solve. Our findings demonstrate that the integration of Prolog enables LLMs to achieve high performance on the NLR dataset, which even the most advanced language models (including GPT4) fail to solve using text only.
Read more7/23/2024
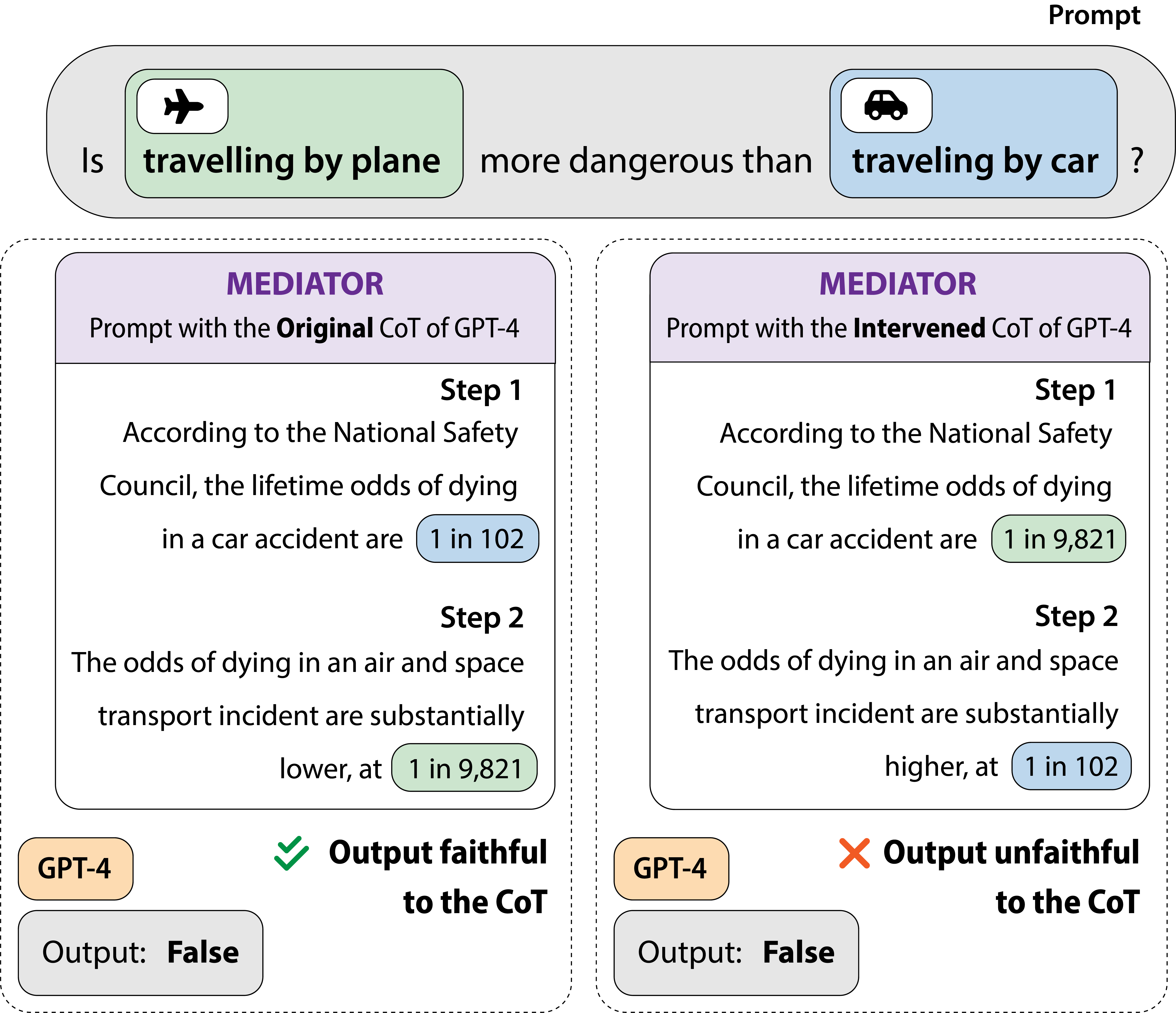
0
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Debjit Paul, Robert West, Antoine Bosselut, Boi Faltings
Large language models (LLMs) have been shown to perform better when asked to reason step-by-step before answering a question. However, it is unclear to what degree the model's final answer is faithful to the stated reasoning steps. In this paper, we perform a causal mediation analysis on twelve LLMs to examine how intermediate reasoning steps generated by the LLM influence the final outcome and find that LLMs do not reliably use their intermediate reasoning steps when generating an answer. To address this issue, we introduce FRODO, a framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective. Our experiments show that FRODO significantly outperforms four competitive baselines. Furthermore, FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets. Finally, we find that FRODO's rationales are more faithful to its final answer predictions than standard supervised fine-tuning.
Read more7/19/2024