Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning

0
Sign in to get full access
Overview
• This paper explores ways to measure and improve the faithfulness of chain-of-thought reasoning in large language models.
• The researchers propose using a "reasoning chain" as a mediator between the model's input and output, which can be used to assess how well the model's reasoning aligns with the correct steps to solve a problem.
• They develop metrics to quantify the faithfulness of the reasoning chain and present techniques to improve it, such as prompting the model to generate more faithful reasoning steps.
Plain English Explanation
Towards Faithful Chain-of-Thought Reasoning in Large Language Models is a research paper that looks at how to make the step-by-step reasoning process of large language models more accurate and trustworthy.
Large language models, like GPT-3, are powerful AI systems that can generate human-like text. However, it's often unclear how these models arrive at their answers - their reasoning process is hidden "under the hood." The researchers in this paper wanted to find a way to open up that black box and understand the model's reasoning.
Their key insight was to focus on the "reasoning chain" - the sequence of intermediate steps the model takes to arrive at a final answer. By analyzing this reasoning chain, they could assess how faithful or accurate it was compared to the correct reasoning process a human would use.
The paper describes several ways to measure the faithfulness of the reasoning chain, such as comparing it to ground truth reasoning steps or checking if the intermediate conclusions logically lead to the final answer. The researchers also developed techniques to improve the faithfulness of the reasoning, like prompting the model to generate more detailed, step-by-step explanations.
Overall, the goal is to make large language models more transparent and trustworthy, so we can better understand their decision-making and rely on their outputs for important real-world applications. The work in this paper represents an important step towards that goal.
Technical Explanation
Towards Faithful Chain-of-Thought Reasoning in Large Language Models presents a framework for measuring and improving the faithfulness of the step-by-step reasoning process in large language models.
The key innovation is the idea of a "reasoning chain" - a sequence of intermediate conclusions or reasoning steps that a model generates to arrive at a final answer. By analyzing this reasoning chain, the researchers can assess how well it aligns with the correct, human-like reasoning process.
They develop several metrics to quantify reasoning chain faithfulness, such as:
- Reasoning Chain Faithfulness: How well each step in the reasoning chain logically connects to the next.
- Reasoning Chain Completeness: Whether the reasoning chain includes all the necessary steps to solve the problem.
- Reasoning Chain Grounding: How well the reasoning chain connects back to the original problem statement and facts.
The paper also introduces techniques to improve reasoning chain faithfulness, such as:
- Prompting the model to generate more detailed, step-by-step explanations
- Using smaller, more specialized models to verify the reasoning chain
Overall, this work aims to make large language models' decision-making more transparent and reliable, which is crucial for real-world applications where trust and accountability are paramount.
Critical Analysis
The researchers make a compelling case for the importance of faithfulness in chain-of-thought reasoning for large language models. Their proposed metrics and techniques for measuring and improving reasoning chain faithfulness are rigorous and well-designed.
However, one potential limitation is the reliance on human-annotated ground truth reasoning chains for evaluation. While necessary for assessing faithfulness, this approach may not scale easily to the vast range of possible problems and reasoning processes that large language models could encounter.
Additionally, the paper does not deeply explore potential biases or inconsistencies that could arise within the reasoning chains generated by these models. Further research may be needed to fully understand and mitigate such issues.
Overall, this work represents an important step towards making large language models more transparent and trustworthy. By focusing on the reasoning process rather than just the final output, the researchers are opening up the black box and empowering users to better understand and rely on these powerful AI systems.
Conclusion
Towards Faithful Chain-of-Thought Reasoning in Large Language Models presents a novel framework for measuring and improving the faithfulness of the step-by-step reasoning process in large language models.
The key innovation is the concept of a "reasoning chain" - a sequence of intermediate conclusions that the model generates to arrive at a final answer. By analyzing the faithfulness of this reasoning chain, the researchers can assess how well the model's decision-making aligns with correct, human-like logic.
The paper introduces several metrics to quantify reasoning chain faithfulness, as well as techniques to improve it, such as prompting the model to provide more detailed, step-by-step explanations. This work represents an important step towards making large language models more transparent and trustworthy, which is crucial for real-world applications where accountability and reliability are essential.
Overall, this research contributes valuable insights and methods for opening up the black box of large language models and ensuring their decision-making processes are faithful and reliable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Debjit Paul, Robert West, Antoine Bosselut, Boi Faltings
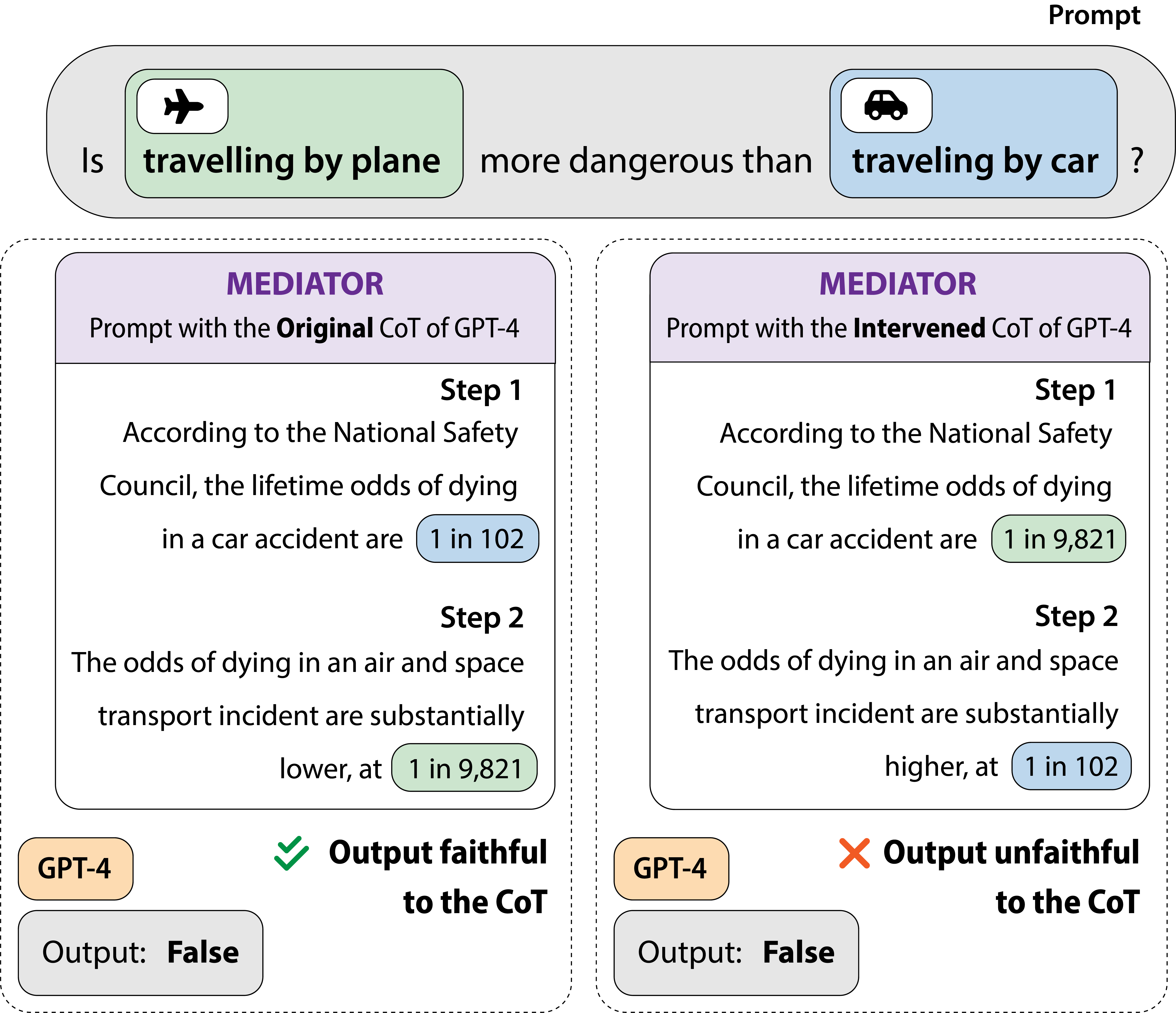
Large language models (LLMs) have been shown to perform better when asked to reason step-by-step before answering a question. However, it is unclear to what degree the model's final answer is faithful to the stated reasoning steps. In this paper, we perform a causal mediation analysis on twelve LLMs to examine how intermediate reasoning steps generated by the LLM influence the final outcome and find that LLMs do not reliably use their intermediate reasoning steps when generating an answer. To address this issue, we introduce FRODO, a framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective. Our experiments show that FRODO significantly outperforms four competitive baselines. Furthermore, FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets. Finally, we find that FRODO's rationales are more faithful to its final answer predictions than standard supervised fine-tuning.
Read more7/19/2024
0
Towards Faithful Chain-of-Thought: Large Language Models are Bridging Reasoners
Jiachun Li, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
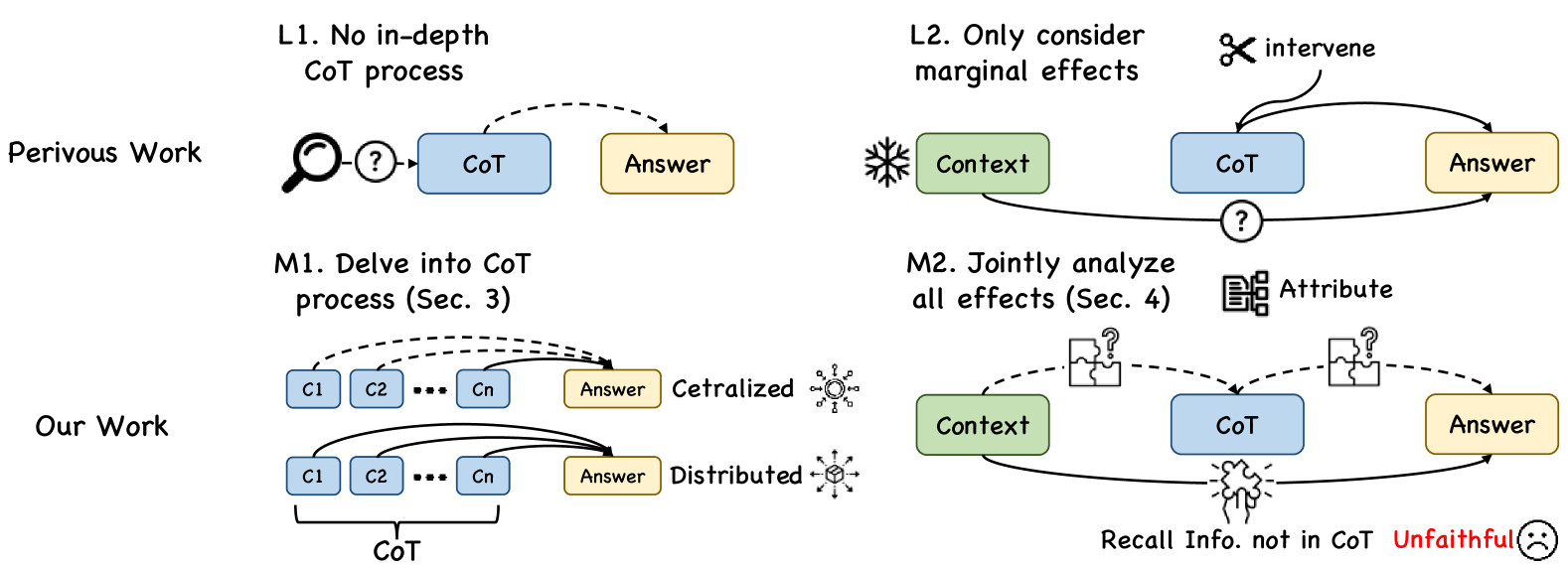
Large language models (LLMs) suffer from serious unfaithful chain-of-thought (CoT) issues. Previous work attempts to measure and explain it but lacks in-depth analysis within CoTs and does not consider the interactions among all reasoning components jointly. In this paper, we first study the CoT faithfulness issue at the granularity of CoT steps, identify two reasoning paradigms: centralized reasoning and distributed reasoning, and find their relationship with faithfulness. Subsequently, we conduct a joint analysis of the causal relevance among the context, CoT, and answer during reasoning. The result proves that, when the LLM predicts answers, it can recall correct information missing in the CoT from the context, leading to unfaithfulness issues. Finally, we propose the inferential bridging method to mitigate this issue, in which we use the attribution method to recall information as hints for CoT generation and filter out noisy CoTs based on their semantic consistency and attribution scores. Extensive experiments demonstrate that our approach effectively alleviates the unfaithful CoT problem.
Read more5/30/2024
0
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Sree Harsha Tanneru, Dan Ley, Chirag Agarwal, Himabindu Lakkaraju
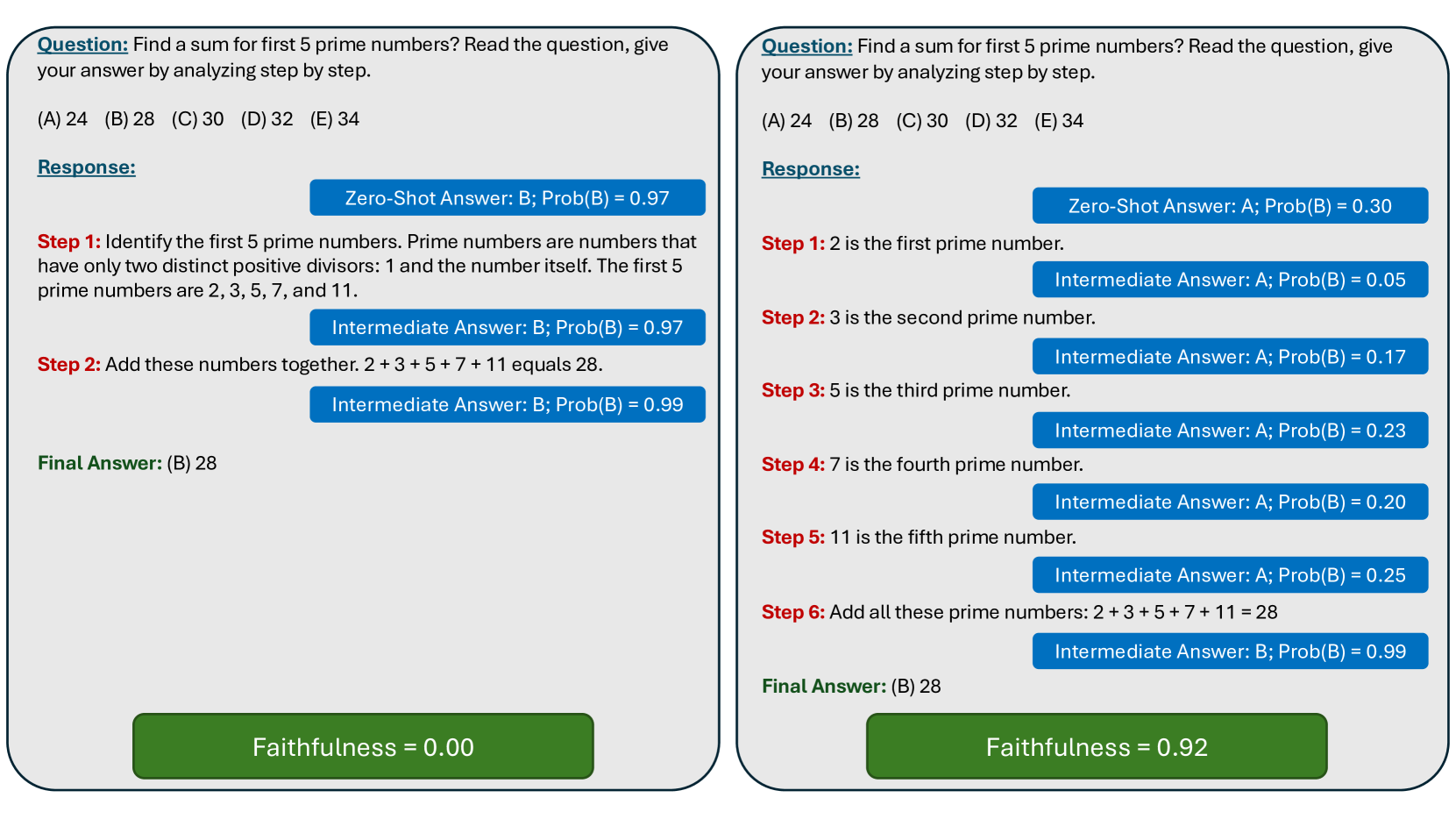
As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
Read more7/2/2024

0
General Purpose Verification for Chain of Thought Prompting
Robert Vacareanu, Anurag Pratik, Evangelia Spiliopoulou, Zheng Qi, Giovanni Paolini, Neha Anna John, Jie Ma, Yassine Benajiba, Miguel Ballesteros
Many of the recent capabilities demonstrated by Large Language Models (LLMs) arise primarily from their ability to exploit contextual information. In this paper, we explore ways to improve reasoning capabilities of LLMs through (1) exploration of different chains of thought and (2) validation of the individual steps of the reasoning process. We propose three general principles that a model should adhere to while reasoning: (i) Relevance, (ii) Mathematical Accuracy, and (iii) Logical Consistency. We apply these constraints to the reasoning steps generated by the LLM to improve the accuracy of the final generation. The constraints are applied in the form of verifiers: the model itself is asked to verify if the generated steps satisfy each constraint. To further steer the generations towards high-quality solutions, we use the perplexity of the reasoning steps as an additional verifier. We evaluate our method on 4 distinct types of reasoning tasks, spanning a total of 9 different datasets. Experiments show that our method is always better than vanilla generation, and, in 6 out of the 9 datasets, it is better than best-of N sampling which samples N reasoning chains and picks the lowest perplexity generation.
Read more5/2/2024