Reliable Reasoning Beyond Natural Language

0

Sign in to get full access
Overview
- This paper introduces a new approach for enabling reliable reasoning beyond natural language processing in large language models (LLMs).
- The proposed method aims to improve the logical consistency and reasoning capabilities of LLMs by incorporating probabilistic reasoning techniques.
- The paper compares this approach to other recent efforts in improving the reasoning abilities of LLMs, such as LogicBench, Reasoning in Large Language Models: A Survey, and Probabilistic Reasoning in Generative Large Language Models.
Plain English Explanation
The paper presents a new way to make large language models (LLMs) better at logical reasoning and decision-making. LLMs are AI systems that can understand and generate human-like text, but they sometimes struggle with consistent, reliable reasoning beyond just processing natural language.
The key idea is to incorporate probabilistic reasoning techniques into LLMs. This means the models don't just output a single answer, but consider multiple possible outcomes and their likelihood. This can help the models reason more logically and make more thoughtful, well-rounded decisions.
The paper compares this approach to other recent efforts to improve the reasoning abilities of LLMs, such as benchmarks to systematically evaluate logical reasoning, surveys of different reasoning techniques, and methods for incorporating probabilistic reasoning directly into the language models.
Technical Explanation
The paper presents a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by integrating probabilistic reasoning techniques. Traditional LLMs often struggle with maintaining logical consistency and reliability when operating beyond the scope of natural language processing.
To address this, the authors propose a method that allows LLMs to reason probabilistically, considering multiple possible outcomes and their associated likelihoods. This probabilistic reasoning component is seamlessly integrated into the LLM architecture, enabling the model to make more logically sound and well-rounded decisions.
The paper compares this approach to other recent advancements in the field, such as LogicBench, which provides a benchmark for evaluating the logical reasoning abilities of LLMs, Reasoning in Large Language Models: A Survey, which examines various reasoning techniques applied to LLMs, and Probabilistic Reasoning in Generative Large Language Models, which explores the incorporation of probabilistic reasoning directly into the language model architecture.
Critical Analysis
The paper presents a promising approach for enhancing the logical reasoning capabilities of LLMs, but it is important to consider some potential limitations and areas for further research.
One potential caveat is the complexity involved in seamlessly integrating probabilistic reasoning components into existing LLM architectures. The authors acknowledge the technical challenges in achieving this integration, and further research may be needed to refine the implementation and ensure the approach is scalable and efficient.
Additionally, the paper does not provide a comprehensive evaluation of the proposed method's performance compared to other state-of-the-art approaches, such as those discussed in Beyond Accuracy: Evaluating Reasoning Behavior in Large Language Models and Towards Logically Consistent Language Models via Probabilistic. Further empirical studies and benchmarking against these related efforts would help contextualize the strengths and limitations of the proposed approach.
Conclusion
This paper introduces a novel method for enhancing the logical reasoning capabilities of large language models (LLMs) by integrating probabilistic reasoning techniques. The key innovation is the seamless integration of a probabilistic reasoning component into the LLM architecture, allowing the model to consider multiple possible outcomes and their associated likelihoods when making decisions.
This approach represents an important step forward in improving the reliability and consistency of LLMs when operating beyond natural language processing. By incorporating probabilistic reasoning, the models can make more thoughtful, logically sound decisions, which has the potential to significantly impact a wide range of applications, from conversational AI to decision support systems.
Further research and evaluation will be necessary to fully understand the strengths, limitations, and broader implications of this method, but the paper's contribution to the ongoing efforts to improve the reasoning abilities of LLMs is a valuable addition to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Reliable Reasoning Beyond Natural Language
Nasim Borazjanizadeh, Steven T. Piantadosi
Despite their linguistic competence, Large Language models (LLMs) often exhibit limitations in their ability to reason reliably and flexibly. To address this, we propose a neurosymbolic approach that prompts LLMs to extract and encode all relevant information from a problem statement as logical code statements, and then use a logic programming language (Prolog) to conduct the iterative computations of explicit deductive reasoning. Our approach significantly enhances the performance of LLMs on the standard mathematical reasoning benchmark, GSM8k, and the Navigate dataset from the BIG-bench dataset. Additionally, we introduce a novel dataset, the Non-Linear Reasoning (NLR) dataset, consisting of 55 unique word problems that target the shortcomings of the next token prediction paradigm of LLMs and require complex non-linear reasoning but only basic arithmetic skills to solve. Our findings demonstrate that the integration of Prolog enables LLMs to achieve high performance on the NLR dataset, which even the most advanced language models (including GPT4) fail to solve using text only.
Read more7/23/2024
0
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Read more6/7/2024

0
Reasoning with Large Language Models, a Survey
Aske Plaat, Annie Wong, Suzan Verberne, Joost Broekens, Niki van Stein, Thomas Back
Scaling up language models to billions of parameters has opened up possibilities for in-context learning, allowing instruction tuning and few-shot learning on tasks that the model was not specifically trained for. This has achieved breakthrough performance on language tasks such as translation, summarization, and question-answering. Furthermore, in addition to these associative System 1 tasks, recent advances in Chain-of-thought prompt learning have demonstrated strong System 2 reasoning abilities, answering a question in the field of artificial general intelligence whether LLMs can reason. The field started with the question whether LLMs can solve grade school math word problems. This paper reviews the rapidly expanding field of prompt-based reasoning with LLMs. Our taxonomy identifies different ways to generate, evaluate, and control multi-step reasoning. We provide an in-depth coverage of core approaches and open problems, and we propose a research agenda for the near future. Finally, we highlight the relation between reasoning and prompt-based learning, and we discuss the relation between reasoning, sequential decision processes, and reinforcement learning. We find that self-improvement, self-reflection, and some metacognitive abilities of the reasoning processes are possible through the judicious use of prompts. True self-improvement and self-reasoning, to go from reasoning with LLMs to reasoning by LLMs, remains future work.
Read more7/17/2024
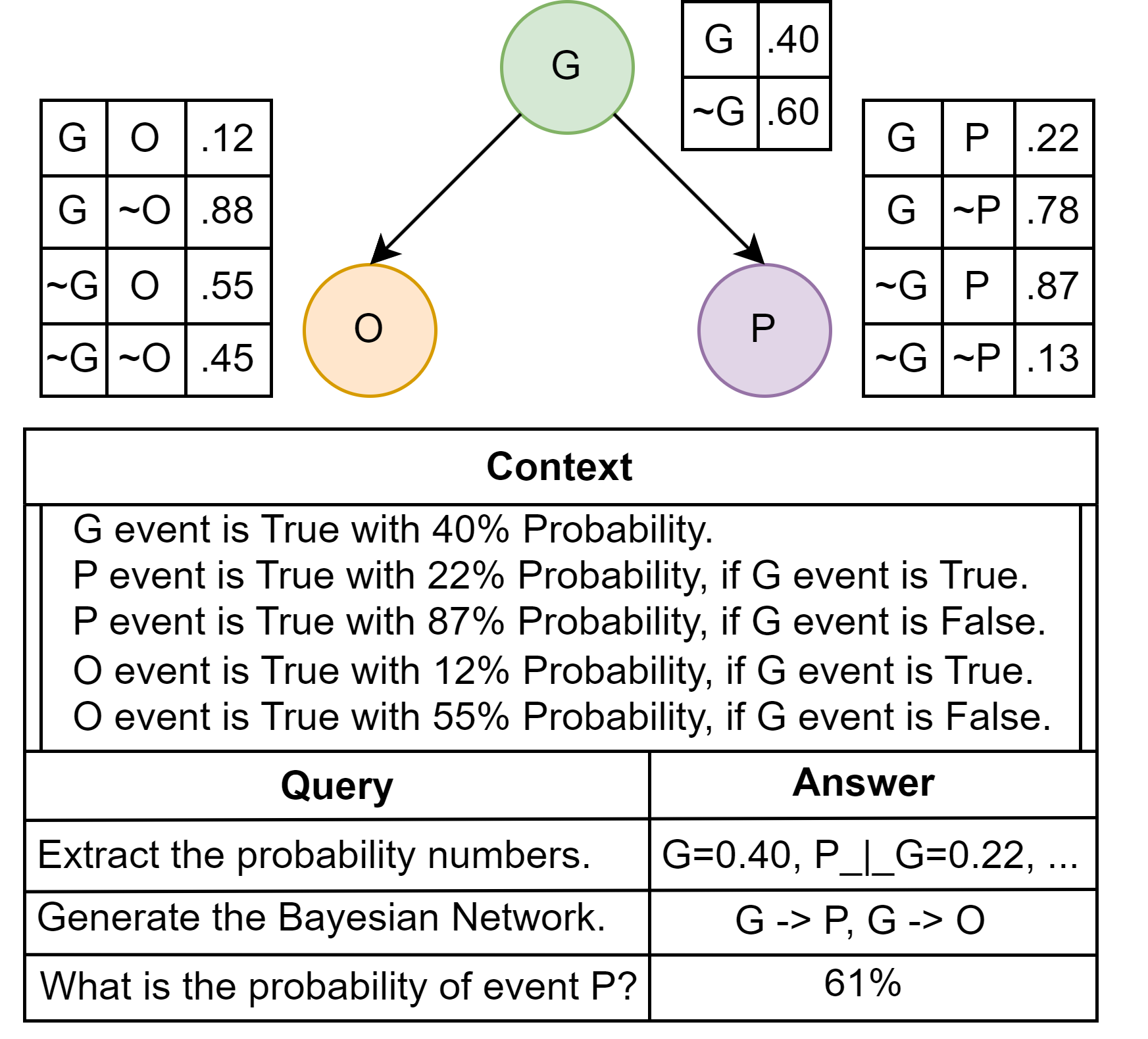
0
Probabilistic Reasoning in Generative Large Language Models
Aliakbar Nafar, Kristen Brent Venable, Parisa Kordjamshidi
This paper considers the challenges Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We use BLInD to find out the limitations of LLMs for tasks involving probabilistic reasoning. In addition, we present several prompting strategies that map the problem to different formal representations, including Python code, probabilistic algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and an adaptation of a causal reasoning question-answering dataset. Our empirical results highlight the effectiveness of our proposed strategies for multiple LLMs.
Read more6/18/2024