Detours for Navigating Instructional Videos

0
Sign in to get full access
Overview
- This paper explores techniques for navigating instructional videos more efficiently by identifying "detours" - short clips that can summarize or provide alternative explanations for specific steps in a video.
- The researchers propose a formulation of the video detour task and develop methods for automatically detecting and ranking detour candidates within instructional videos.
- They evaluate their approach on a dataset of how-to videos and demonstrate that the identified detours can help users more quickly find relevant information and complete tasks.
Plain English Explanation
The paper focuses on making it easier for people to navigate and learn from instructional videos, such as tutorials on how to complete a specific task or skill. Oftentimes, these videos can be long and contain information that may not be directly relevant to the viewer's needs at a given moment.
The researchers propose the idea of "detours" - short clips within the larger video that can provide alternative explanations or summaries of key steps. By automatically detecting and ranking these detour clips, the goal is to help viewers more quickly find the information they need without having to scrub through the entire video.
For example, imagine watching a video on how to change a tire. The full video may be 15 minutes long, but there may be 2-3 minute clips that focus specifically on loosening the lug nuts or jacking up the car - these could be considered "detours" that allow the viewer to quickly refresh or re-learn those crucial steps without having to rewatch the entire video.
The paper describes methods for identifying and ranking these detour clips, and evaluates the effectiveness of this approach on a dataset of real-world instructional videos. The results suggest that detours can indeed help viewers navigate videos more efficiently and complete tasks more quickly.
Technical Explanation
The paper first formalizes the "video detour task" - given an instructional video, the goal is to automatically identify short clips within the video that could serve as useful detours or alternative explanations for specific steps or concepts.
The researchers propose two main technical approaches for this task:
-
Detour Candidate Extraction: This involves using video and language processing techniques to identify segments of the video that are conceptually distinct from their surrounding context. These could be clips that introduce a new step, provide a summary, or present an alternative explanation.
-
Detour Ranking: Once detour candidates have been identified, the next step is to rank them in terms of their "detour quality" - how useful and relevant they would be to a viewer seeking to quickly understand a particular step or concept. This ranking is based on factors like semantic similarity to the overall video content, visual distinctiveness, and length.
The paper evaluates these detour detection and ranking methods on a dataset of how-to instructional videos covering a variety of tasks. The results show that the identified detours can indeed help users more efficiently navigate the videos and complete the demonstrated tasks.
Critical Analysis
The paper presents a novel and potentially impactful approach for enhancing the usability of instructional videos. The core ideas around automatically detecting and ranking "detours" within longer videos seem well-motivated and the experimental evaluation provides promising initial results.
However, the work also has some notable limitations:
-
The dataset used for evaluation, while sizable, is relatively narrow in scope, focusing only on how-to videos. It's unclear how well the techniques would generalize to other types of instructional content, such as lectures or DIY tutorials.
-
The paper does not provide detailed analysis of the types of detours that are most useful to viewers or the specific factors that contribute to a "high quality" detour. Further research into the cognitive and user experience aspects of navigating videos in this way could lead to improved detour detection and ranking.
-
While the detour identification is automated, the paper does not address how these detours would be surfaced or integrated into the video viewing experience. Developing intuitive user interface designs and interactions for leveraging detours remains an open challenge.
-
The long-term implications and potential unintended consequences of such detour-based video navigation systems are not explored. There may be concerns around bias, information fragmentation, or undermining the original video creator's intent.
Overall, the paper makes a valuable contribution by conceptualizing and validating the idea of video detours. But further research is needed to fully realize the potential of this approach and address the practical and ethical considerations.
Conclusion
This paper introduces the concept of "video detours" - short, conceptually distinct clips within longer instructional videos that can provide alternative explanations or summaries of key steps. The researchers develop techniques for automatically detecting and ranking these detour candidates, with the goal of helping viewers more efficiently navigate and learn from instructional video content.
The experimental results demonstrate the potential of this approach, showing that the identified detours can enable users to more quickly complete tasks demonstrated in the videos. However, the work also highlights areas for further research, such as expanding the scope of evaluated content, deepening the understanding of what makes an effective detour, and exploring the user experience and ethical implications of deploying such video navigation systems.
Ultimately, this paper lays important groundwork for enhancing the usability and pedagogical value of instructional videos - an increasingly important medium for learning and skill development in the digital age. As video continues to pervade education and training, techniques like video detours may prove crucial for transforming these resources into more focused, personalized, and efficient learning tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Detours for Navigating Instructional Videos
Kumar Ashutosh, Zihui Xue, Tushar Nagarajan, Kristen Grauman
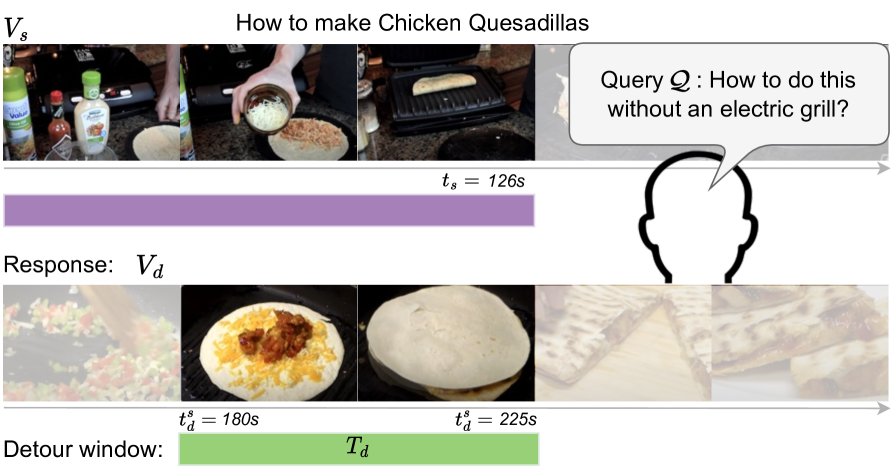
We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
Read more5/7/2024

10
Step Differences in Instructional Video
Tushar Nagarajan, Lorenzo Torresani
Comparing a user video to a reference how-to video is a key requirement for AR/VR technology delivering personalized assistance tailored to the user's progress. However, current approaches for language-based assistance can only answer questions about a single video. We propose an approach that first automatically generates large amounts of visual instruction tuning data involving pairs of videos from HowTo100M by leveraging existing step annotations and accompanying narrations, and then trains a video-conditioned language model to jointly reason across multiple raw videos. Our model achieves state-of-the-art performance at identifying differences between video pairs and ranking videos based on the severity of these differences, and shows promising ability to perform general reasoning over multiple videos. Project page: https://github.com/facebookresearch/stepdiff
Read more7/1/2024
🌿
0
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
Read more5/30/2024

0
Multimodal Language Models for Domain-Specific Procedural Video Summarization
Nafisa Hussain
Videos serve as a powerful medium to convey ideas, tell stories, and provide detailed instructions, especially through long-format tutorials. Such tutorials are valuable for learning new skills at one's own pace, yet they can be overwhelming due to their length and dense content. Viewers often seek specific information, like precise measurements or step-by-step execution details, making it essential to extract and summarize key segments efficiently. An intelligent, time-sensitive video assistant capable of summarizing and detecting highlights in long videos is highly sought after. Recent advancements in Multimodal Large Language Models offer promising solutions to develop such an assistant. Our research explores the use of multimodal models to enhance video summarization and step-by-step instruction generation within specific domains. These models need to understand temporal events and relationships among actions across video frames. Our approach focuses on fine-tuning TimeChat to improve its performance in specific domains: cooking and medical procedures. By training the model on domain-specific datasets like Tasty for cooking and MedVidQA for medical procedures, we aim to enhance its ability to generate concise, accurate summaries of instructional videos. We curate and restructure these datasets to create high-quality video-centric instruction data. Our findings indicate that when finetuned on domain-specific procedural data, TimeChat can significantly improve the extraction and summarization of key instructional steps in long-format videos. This research demonstrates the potential of specialized multimodal models to assist with practical tasks by providing personalized, step-by-step guidance tailored to the unique aspects of each domain.
Read more7/9/2024