Step Differences in Instructional Video

10

Sign in to get full access
Overview
- This paper investigates the differences in step-by-step instructional videos, with a focus on understanding how the level of detail and the pacing of instructions can impact learning.
- The researchers analyze a dataset of instructional videos across various domains, such as cooking, crafting, and home repair, to identify patterns in the way instructions are presented.
- The goal is to gain insights that can inform the design of more effective instructional videos and enhance learning experiences for viewers.
Plain English Explanation
The paper examines how the step-by-step instructions in educational videos can differ in terms of the level of detail and the pace at which they are presented. By analyzing a collection of instructional videos across various topics, such as cooking, crafting, and home repairs, the researchers aim to identify patterns and insights that can help create more effective and engaging instructional videos.
The idea is that the way instructions are presented in these videos can have a significant impact on how well viewers are able to learn and follow the steps. Some videos might provide a lot of detailed information, while others might move through the steps more quickly. The researchers want to understand these differences and how they affect the learning process.
By uncovering these patterns, the researchers hope to provide guidance on how to design instructional videos that are more tailored to the needs of the viewers, helping them learn and retain the information more effectively. This could have applications in a wide range of educational and training contexts, from cooking classes to DIY tutorials.
Technical Explanation
The paper Distilling Vision-Language Models from Millions of Videos analyzes a dataset of instructional videos to investigate the differences in the way step-by-step instructions are presented. The researchers examine factors such as the level of detail provided in each step and the pacing of the instructions.
The analysis is conducted across a diverse set of instructional video domains, including cooking, crafting, and home repair. By identifying patterns in how instructions are delivered, the researchers aim to provide insights that can inform the design of more effective instructional videos. This aligns with related work on Generating Illustrated Instructions, Improving Interpretable Embeddings for Ad-Hoc Video Search, and Improving Video-Text Retrieval through Augmentation, which also explore ways to enhance the learning and information delivery in instructional media.
The key objective is to understand how the presentation of step-by-step instructions in videos can impact the viewers' ability to learn and retain the information. By uncovering these patterns, the researchers hope to provide guidelines and design principles that can lead to the creation of more effective and engaging instructional videos, ultimately improving the learning experiences for viewers.
Critical Analysis
The paper presents a comprehensive analysis of step differences in instructional videos, which is a valuable contribution to the field of video-based learning and instruction. However, the study is limited to a specific set of video domains, and it would be interesting to see if the identified patterns hold true across a wider range of instructional content.
Additionally, the paper does not delve into the potential cognitive and psychological factors that may influence how learners respond to different levels of detail and pacing in instructional videos. Incorporating insights from educational psychology and human learning research could further strengthen the implications and practical applications of the findings.
It would also be worthwhile to explore how factors such as the viewers' prior knowledge, learning styles, and personal preferences might interact with the presentation of step-by-step instructions. This could help identify more nuanced design guidelines that account for individual differences among learners.
Conclusion
This paper provides valuable insights into the differences in step-by-step instructional videos, highlighting the importance of understanding how the level of detail and pacing of instructions can impact learning. The findings can inform the design of more effective instructional videos, contributing to enhanced learning experiences across a variety of educational and training contexts.
By uncovering patterns in the way instructions are presented, the researchers lay the groundwork for developing design principles and guidelines that can guide the creation of instructional videos that are tailored to the needs and preferences of viewers. This research has the potential to positively impact the way educational and training content is delivered, ultimately improving learner outcomes and engagement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
10
Step Differences in Instructional Video
Tushar Nagarajan, Lorenzo Torresani
Comparing a user video to a reference how-to video is a key requirement for AR/VR technology delivering personalized assistance tailored to the user's progress. However, current approaches for language-based assistance can only answer questions about a single video. We propose an approach that first automatically generates large amounts of visual instruction tuning data involving pairs of videos from HowTo100M by leveraging existing step annotations and accompanying narrations, and then trains a video-conditioned language model to jointly reason across multiple raw videos. Our model achieves state-of-the-art performance at identifying differences between video pairs and ranking videos based on the severity of these differences, and shows promising ability to perform general reasoning over multiple videos. Project page: https://github.com/facebookresearch/stepdiff
Read more7/1/2024
0
Detours for Navigating Instructional Videos
Kumar Ashutosh, Zihui Xue, Tushar Nagarajan, Kristen Grauman
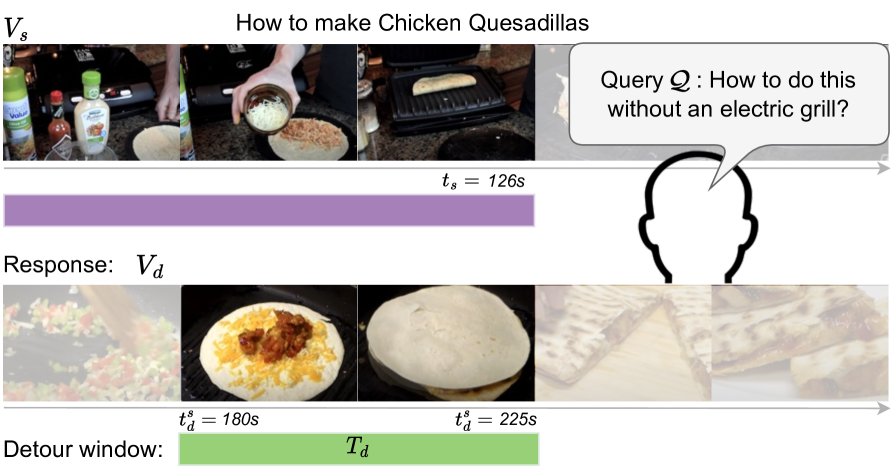
We introduce the video detours problem for navigating instructional videos. Given a source video and a natural language query asking to alter the how-to video's current path of execution in a certain way, the goal is to find a related ''detour video'' that satisfies the requested alteration. To address this challenge, we propose VidDetours, a novel video-language approach that learns to retrieve the targeted temporal segments from a large repository of how-to's using video-and-text conditioned queries. Furthermore, we devise a language-based pipeline that exploits how-to video narration text to create weakly supervised training data. We demonstrate our idea applied to the domain of how-to cooking videos, where a user can detour from their current recipe to find steps with alternate ingredients, tools, and techniques. Validating on a ground truth annotated dataset of 16K samples, we show our model's significant improvements over best available methods for video retrieval and question answering, with recall rates exceeding the state of the art by 35%.
Read more5/7/2024
🌿
0
InstructVid2Vid: Controllable Video Editing with Natural Language Instructions
Bosheng Qin, Juncheng Li, Siliang Tang, Tat-Seng Chua, Yueting Zhuang
We introduce InstructVid2Vid, an end-to-end diffusion-based methodology for video editing guided by human language instructions. Our approach empowers video manipulation guided by natural language directives, eliminating the need for per-example fine-tuning or inversion. The proposed InstructVid2Vid model modifies a pretrained image generation model, Stable Diffusion, to generate a time-dependent sequence of video frames. By harnessing the collective intelligence of disparate models, we engineer a training dataset rich in video-instruction triplets, which is a more cost-efficient alternative to collecting data in real-world scenarios. To enhance the coherence between successive frames within the generated videos, we propose the Inter-Frames Consistency Loss and incorporate it during the training process. With multimodal classifier-free guidance during the inference stage, the generated videos is able to resonate with both the input video and the accompanying instructions. Experimental results demonstrate that InstructVid2Vid is capable of generating high-quality, temporally coherent videos and performing diverse edits, including attribute editing, background changes, and style transfer. These results underscore the versatility and effectiveness of our proposed method.
Read more5/30/2024

0
Multimodal Language Models for Domain-Specific Procedural Video Summarization
Nafisa Hussain
Videos serve as a powerful medium to convey ideas, tell stories, and provide detailed instructions, especially through long-format tutorials. Such tutorials are valuable for learning new skills at one's own pace, yet they can be overwhelming due to their length and dense content. Viewers often seek specific information, like precise measurements or step-by-step execution details, making it essential to extract and summarize key segments efficiently. An intelligent, time-sensitive video assistant capable of summarizing and detecting highlights in long videos is highly sought after. Recent advancements in Multimodal Large Language Models offer promising solutions to develop such an assistant. Our research explores the use of multimodal models to enhance video summarization and step-by-step instruction generation within specific domains. These models need to understand temporal events and relationships among actions across video frames. Our approach focuses on fine-tuning TimeChat to improve its performance in specific domains: cooking and medical procedures. By training the model on domain-specific datasets like Tasty for cooking and MedVidQA for medical procedures, we aim to enhance its ability to generate concise, accurate summaries of instructional videos. We curate and restructure these datasets to create high-quality video-centric instruction data. Our findings indicate that when finetuned on domain-specific procedural data, TimeChat can significantly improve the extraction and summarization of key instructional steps in long-format videos. This research demonstrates the potential of specialized multimodal models to assist with practical tasks by providing personalized, step-by-step guidance tailored to the unique aspects of each domain.
Read more7/9/2024