Mathematical Entities: Corpora and Benchmarks
2406.11577
0
0

Abstract
Mathematics is a highly specialized domain with its own unique set of challenges. Despite this, there has been relatively little research on natural language processing for mathematical texts, and there are few mathematical language resources aimed at NLP. In this paper, we aim to provide annotated corpora that can be used to study the language of mathematics in different contexts, ranging from fundamental concepts found in textbooks to advanced research mathematics. We preprocess the corpora with a neural parsing model and some manual intervention to provide part-of-speech tags, lemmas, and dependency trees. In total, we provide 182397 sentences across three corpora. We then aim to test and evaluate several noteworthy natural language processing models using these corpora, to show how well they can adapt to the domain of mathematics and provide useful tools for exploring mathematical language. We evaluate several neural and symbolic models against benchmarks that we extract from the corpus metadata to show that terminology extraction and definition extraction do not easily generalize to mathematics, and that additional work is needed to achieve good performance on these metrics. Finally, we provide a learning assistant that grants access to the content of these corpora in a context-sensitive manner, utilizing text search and entity linking. Though our corpora and benchmarks provide useful metrics for evaluating mathematical language processing, further work is necessary to adapt models to mathematics in order to provide more effective learning assistants and apply NLP methods to different mathematical domains.
Create account to get full access
Overview
- This paper presents a comprehensive review of the current state of research on mathematical entities, including corpora and benchmarks used in the field.
- The authors examine the role of natural language processing (NLP) and large language models (LLMs) in mathematical problem-solving and explore the challenges and opportunities in this domain.
- The paper also discusses the development of efficient corpora using ensemble data cleaning techniques and the use of general LLMs for classifying mathematical entities.
- Finally, the authors conduct a case study to investigate the internal numeracy of language models.
Plain English Explanation
The paper discusses the current state of research on mathematical entities, which are the building blocks of mathematical concepts and problems. The authors explore how natural language processing (NLP) and large language models (LLMs) can be used to understand and solve mathematical problems.
One of the key challenges in this field is the development of reliable corpora, or collections of data, that can be used to train and test these models. The paper presents methods for developing efficient corpora using ensemble data cleaning techniques, which can help improve the quality and consistency of the data used in these models.
The authors also discuss using general LLMs to classify mathematical entities, which can be a useful tool for identifying and categorizing the different components of mathematical problems. This can be particularly helpful in areas like mathematical language processing, where understanding the structure and relationships between mathematical concepts is crucial.
Finally, the paper presents a case study that explores the internal numeracy of language models, or their ability to understand and reason about numerical concepts. This is an important area of research, as it can help us understand how LLMs can be effectively used in mathematical problem-solving.
Overall, this paper provides a comprehensive overview of the current state of research on mathematical entities and the role of NLP and LLMs in this field. It highlights the challenges and opportunities in this area and lays the groundwork for future research and development.
Technical Explanation
The paper begins by reviewing the existing work on NLP and mathematical language processing, highlighting the challenges and opportunities in this domain. The authors discuss the importance of developing reliable corpora and benchmarks for training and evaluating models in this field.
One of the key contributions of the paper is the presentation of methods for developing efficient corpora using ensemble data cleaning techniques. The authors demonstrate how this approach can improve the quality and consistency of the data used in training and evaluating models, which is crucial for ensuring the accuracy and robustness of these systems.
The paper also examines the use of general LLMs for classifying mathematical entities, exploring the potential of these models to identify and categorize the different components of mathematical problems. This can be particularly useful in the context of mathematical language processing, where understanding the structure and relationships between mathematical concepts is essential.
Finally, the authors present a case study that investigates the internal numeracy of language models, or their ability to understand and reason about numerical concepts. This is a crucial aspect of effectively using LLMs in mathematical problem-solving, as it can help us better understand the limitations and capabilities of these models in this domain.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the current state of research on mathematical entities, corpora, and benchmarks. The authors have done a thorough job of surveying the existing literature and identifying the key challenges and opportunities in this field.
One potential limitation of the paper is that it does not delve deeply into the specific techniques and algorithms used in the various approaches discussed. While the high-level descriptions are informative, some readers may desire more technical details to fully understand the nuances of the different methods.
Additionally, the paper does not address some of the potential biases and limitations of LLMs, particularly in the context of mathematical problem-solving. As these models are increasingly being used in this domain, it is important to carefully consider their shortcomings and any potential negative impacts they may have.
Overall, the paper provides a valuable contribution to the literature on mathematical entities and the role of NLP and LLMs in this field. The authors' insights and the research directions they outline will likely inspire further exploration and innovation in this important area.
Conclusion
This paper presents a comprehensive review of the current state of research on mathematical entities, including corpora and benchmarks used in the field. The authors explore the role of natural language processing (NLP) and large language models (LLMs) in mathematical problem-solving, highlighting the challenges and opportunities in this domain.
The paper discusses the development of efficient corpora using ensemble data cleaning techniques, the use of general LLMs for classifying mathematical entities, and a case study on the internal numeracy of language models. These contributions provide important insights and lay the groundwork for future research and development in this field.
While the paper offers a thorough overview, it could be enhanced by delving deeper into the technical details of the various approaches discussed and considering the potential biases and limitations of LLMs in the context of mathematical problem-solving. Nonetheless, this paper serves as a valuable resource for researchers and practitioners interested in the intersection of NLP, LLMs, and mathematical entities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
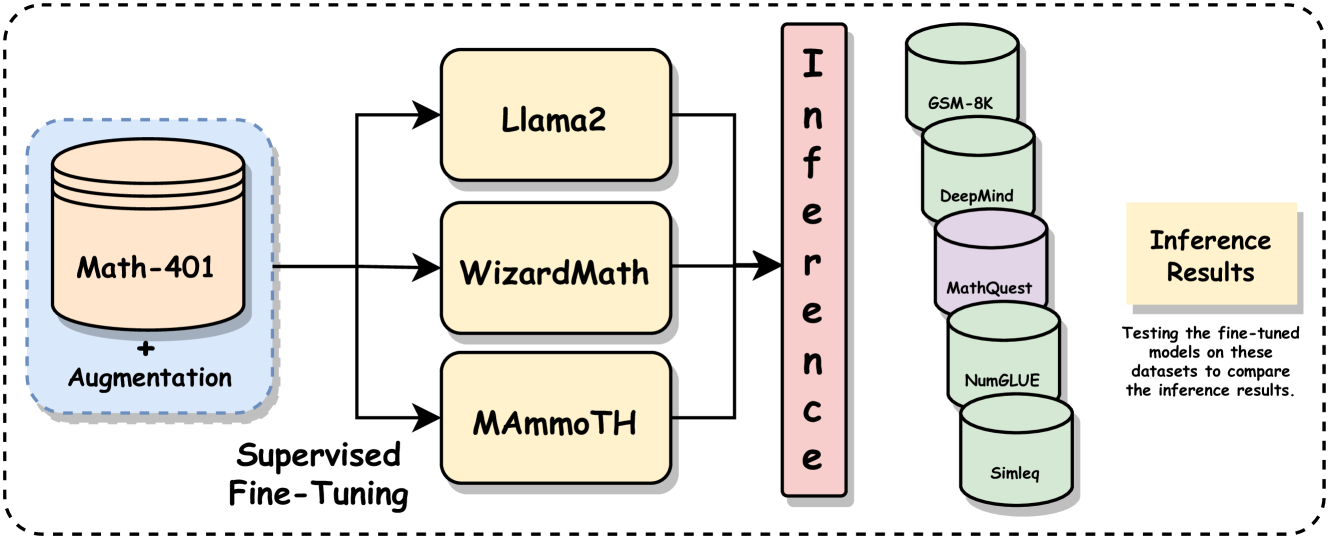
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024
💬
A Survey in Mathematical Language Processing
Jordan Meadows, Andre Freitas
0
0
Informal mathematical text underpins real-world quantitative reasoning and communication. Developing sophisticated methods of retrieval and abstraction from this dual modality is crucial in the pursuit of the vision of automating discovery in quantitative science and mathematics. We track the development of informal mathematical language processing approaches across five strategic sub-areas in recent years, highlighting the prevailing successful methodological elements along with existing limitations.
4/9/2024
📊
Developing an efficient corpus using Ensemble Data cleaning approach
Md Taimur Ahad
0
0
Despite the observable benefit of Natural Language Processing (NLP) in processing a large amount of textual medical data within a limited time for information retrieval, a handful of research efforts have been devoted to uncovering novel data-cleaning methods. Data cleaning in NLP is at the centre point for extracting validated information. Another observed limitation in the NLP domain is having limited medical corpora that provide answers to a given medical question. Realising the limitations and challenges from two perspectives, this research aims to clean a medical dataset using ensemble techniques and to develop a corpus. The corpora expect that it will answer the question based on the semantic relationship of corpus sequences. However, the data cleaning method in this research suggests that the ensemble technique provides the highest accuracy (94%) compared to the single process, which includes vectorisation, exploratory data analysis, and feeding the vectorised data. The second aim of having an adequate corpus was realised by extracting answers from the dataset. This research is significant in machine learning, specifically data cleaning and the medical sector, but it also underscores the importance of NLP in the medical field, where accurate and timely information extraction can be a matter of life and death. It establishes text data processing using NLP as a powerful tool for extracting valuable information like image data.
6/4/2024

Using General Large Language Models to Classify Mathematical Documents
Patrick D. F. Ion, Stephen M. Watt
0
0
In this article we report on an initial exploration to assess the viability of using the general large language models (LLMs), recently made public, to classify mathematical documents. Automated classification would be useful from the applied perspective of improving the navigation of the literature and the more open-ended goal of identifying relations among mathematical results. The Mathematical Subject Classification MSC 2020, from MathSciNet and zbMATH, is widely used and there is a significant corpus of ground truth material in the open literature. We have evaluated the classification of preprint articles from arXiv.org according to MSC 2020. The experiment used only the title and abstract alone -- not the entire paper. Since this was early in the use of chatbots and the development of their APIs, we report here on what was carried out by hand. Of course, the automation of the process will have to follow if it is to be generally useful. We found that in about 60% of our sample the LLM produced a primary classification matching that already reported on arXiv. In about half of those instances, there were additional primary classifications that were not detected. In about 40% of our sample, the LLM suggested a different classification than what was provided. A detailed examination of these cases, however, showed that the LLM-suggested classifications were in most cases better than those provided.
6/18/2024