On-device AI: Quantization-aware Training of Transformers in Time-Series

0
🏋️
Sign in to get full access
Overview
- This paper explores techniques for training Transformer models on time-series data for on-device AI applications.
- Key focus areas include quantization-aware training and efficient inference on low-power hardware.
- The authors propose methods to optimize Transformer models for deployment on embedded devices and mobile platforms.
Plain English Explanation
The paper discusses ways to make powerful Transformer models work well on small, low-power devices like smartphones and IoT sensors. Transformer models are a type of deep learning architecture that have shown great success in areas like natural language processing. However, they can be computationally intensive, making them challenging to run efficiently on resource-constrained hardware.
The researchers explore quantization-aware training techniques, which involve training the model using lower-precision numerical representations. This allows the model to be deployed with reduced memory and computation requirements, enabling on-device inference. They also investigate other optimization strategies, such as inter-series transformer architectures, to make the models more efficient for time-series applications.
The goal is to bring the power of Transformer models to a wider range of edge devices, enabling on-device AI without the need for a connection to the cloud. This could unlock new use cases in areas like time-series forecasting, where low-latency and privacy are important.
Technical Explanation
The paper focuses on training Transformer models for efficient inference on low-power hardware, with a specific focus on time-series applications. The authors explore quantization-aware training, which involves training the model using lower-precision numerical representations (e.g., 8-bit integers instead of 32-bit floats). This allows the model to be deployed with reduced memory and computation requirements, enabling on-device inference on embedded devices and mobile platforms.
The researchers experiment with different quantization techniques, such as integer-only quantization, and evaluate their impact on model accuracy and inference performance. They also investigate architectural modifications, like the inter-series transformer design, to further optimize the models for time-series forecasting tasks.
The paper presents experimental results on several time-series datasets, demonstrating the effectiveness of the proposed techniques in maintaining model accuracy while significantly reducing the computational and memory footprint. This paves the way for deploying powerful Transformer models on a wide range of edge devices, without the need for a connection to the cloud, unlocking new on-device AI use cases.
Critical Analysis
The paper provides a thorough exploration of techniques for training Transformer models to run efficiently on low-power hardware, which is a critical challenge for enabling on-device AI applications. The authors present a comprehensive set of experiments and results, demonstrating the effectiveness of their quantization-aware training approach.
However, the paper does not address some potential limitations or caveats of the proposed methods. For example, the impact of quantization on model robustness or the generalization of the techniques to other types of time-series data or tasks is not explored. Additionally, the paper could have provided more details on the specific hardware platforms and constraints used in the evaluation, as well as the trade-offs between model accuracy, inference latency, and power consumption.
Furthermore, the researchers could have delved deeper into the architectural modifications, such as the inter-series transformer, and provided more insights into the design choices and their theoretical or empirical justifications. Exploring the broader applicability of these techniques to other types of deep learning models or edge-computing scenarios could also have strengthened the paper's contribution.
Overall, the paper makes a valuable contribution to the field of on-device AI, but there are opportunities for further research and analysis to address the limitations and explore the broader implications of the proposed approaches.
Conclusion
This paper presents novel techniques for training Transformer models for efficient inference on low-power hardware, with a focus on time-series applications. The key contributions include:
- Quantization-aware training: The authors explore methods to train Transformer models using lower-precision numerical representations, enabling reduced memory and computation requirements for on-device deployment.
- Architectural optimization: The researchers investigate modifications to the Transformer architecture, such as the inter-series transformer, to further optimize the models for time-series forecasting tasks.
- Enabling on-device AI: The proposed techniques pave the way for deploying powerful Transformer models on a wide range of edge devices, unlocking new use cases in areas like time-series forecasting, where low-latency and privacy are important.
By addressing the computational and memory challenges of running Transformer models on resource-constrained hardware, this work contributes to the broader goal of bringing advanced deep learning capabilities to a wider range of edge devices and IoT applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
On-device AI: Quantization-aware Training of Transformers in Time-Series
Tianheng Ling, Gregor Schiele
Artificial Intelligence (AI) models for time-series in pervasive computing keep getting larger and more complicated. The Transformer model is by far the most compelling of these AI models. However, it is difficult to obtain the desired performance when deploying such a massive model on a sensor device with limited resources. My research focuses on optimizing the Transformer model for time-series forecasting tasks. The optimized model will be deployed as hardware accelerators on embedded Field Programmable Gate Arrays (FPGAs). I will investigate the impact of applying Quantization-aware Training to the Transformer model to reduce its size and runtime memory footprint while maximizing the advantages of FPGAs.
Read more8/30/2024

0
Integer-only Quantized Transformers for Embedded FPGA-based Time-series Forecasting in AIoT
Tianheng Ling, Chao Qian, Gregor Schiele
This paper presents the design of a hardware accelerator for Transformers, optimized for on-device time-series forecasting in AIoT systems. It integrates integer-only quantization and Quantization-Aware Training with optimized hardware designs to realize 6-bit and 4-bit quantized Transformer models, which achieved precision comparable to 8-bit quantized models from related research. Utilizing a complete implementation on an embedded FPGA (Xilinx Spartan-7 XC7S15), we examine the feasibility of deploying Transformer models on embedded IoT devices. This includes a thorough analysis of achievable precision, resource utilization, timing, power, and energy consumption for on-device inference. Our results indicate that while sufficient performance can be attained, the optimization process is not trivial. For instance, reducing the quantization bitwidth does not consistently result in decreased latency or energy consumption, underscoring the necessity of systematically exploring various optimization combinations. Compared to an 8-bit quantized Transformer model in related studies, our 4-bit quantized Transformer model increases test loss by only 0.63%, operates up to 132.33x faster, and consumes 48.19x less energy.
Read more9/9/2024
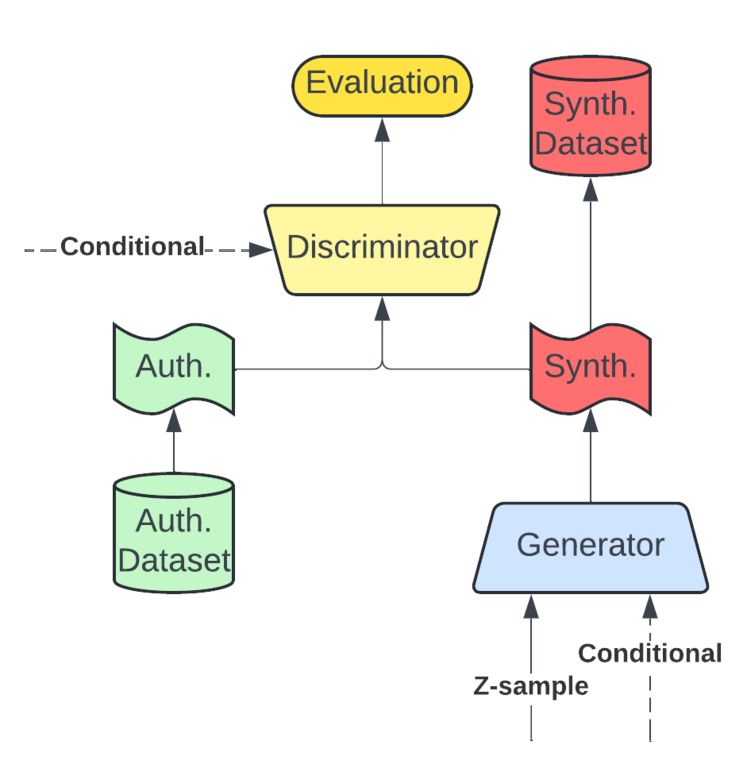
0
A Survey of Transformer Enabled Time Series Synthesis
Alexander Sommers, Logan Cummins, Sudip Mittal, Shahram Rahimi, Maria Seale, Joseph Jaboure, Thomas Arnold
Generative AI has received much attention in the image and language domains, with the transformer neural network continuing to dominate the state of the art. Application of these models to time series generation is less explored, however, and is of great utility to machine learning, privacy preservation, and explainability research. The present survey identifies this gap at the intersection of the transformer, generative AI, and time series data, and reviews works in this sparsely populated subdomain. The reviewed works show great variety in approach, and have not yet converged on a conclusive answer to the problems the domain poses. GANs, diffusion models, state space models, and autoencoders were all encountered alongside or surrounding the transformers which originally motivated the survey. While too open a domain to offer conclusive insights, the works surveyed are quite suggestive, and several recommendations for best practice, and suggestions of valuable future work, are provided.
Read more6/5/2024
🔮
0
Inter-Series Transformer: Attending to Products in Time Series Forecasting
Rares Cristian, Pavithra Harsha, Clemente Ocejo, Georgia Perakis, Brian Quanz, Ioannis Spantidakis, Hamza Zerhouni
Time series forecasting is an important task in many fields ranging from supply chain management to weather forecasting. Recently, Transformer neural network architectures have shown promising results in forecasting on common time series benchmark datasets. However, application to supply chain demand forecasting, which can have challenging characteristics such as sparsity and cross-series effects, has been limited. In this work, we explore the application of Transformer-based models to supply chain demand forecasting. In particular, we develop a new Transformer-based forecasting approach using a shared, multi-task per-time series network with an initial component applying attention across time series, to capture interactions and help address sparsity. We provide a case study applying our approach to successfully improve demand prediction for a medical device manufacturing company. To further validate our approach, we also apply it to public demand forecasting datasets as well and demonstrate competitive to superior performance compared to a variety of baseline and state-of-the-art forecast methods across the private and public datasets.
Read more8/9/2024