DG-RePlAce: A Dataflow-Driven GPU-Accelerated Analytical Global Placement Framework for Machine Learning Accelerators
2404.13049
0
0
Abstract
Global placement is a fundamental step in VLSI physical design. The wide use of 2D processing element (PE) arrays in machine learning accelerators poses new challenges of scalability and Quality of Results (QoR) for state-of-the-art academic global placers. In this work, we develop DG-RePlAce, a new and fast GPU-accelerated global placement framework built on top of the OpenROAD infrastructure, which exploits the inherent dataflow and datapath structures of machine learning accelerators. Experimental results with a variety of machine learning accelerators using a commercial 12nm enablement show that, compared with RePlAce (DREAMPlace), our approach achieves an average reduction in routed wirelength by 10% (7%) and total negative slack (TNS) by 31% (34%), with faster global placement and on-par total runtimes relative to DREAMPlace. Empirical studies on the TILOS MacroPlacement Benchmarks further demonstrate that post-route improvements over RePlAce and DREAMPlace may reach beyond the motivating application to machine learning accelerators.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents DG-RePlAce, a GPU-accelerated analytical global placement framework for machine learning accelerators.
- The framework aims to optimize the placement of components in ML accelerator designs to improve performance and energy efficiency.
- It leverages dataflow analysis and GPU acceleration to achieve faster placement optimization compared to traditional methods.
Plain English Explanation
DG-RePlAce is a new tool that helps design better hardware for machine learning (ML) systems. When you build an ML accelerator chip, you need to carefully place all the different components - like processors, memory, and communication links - to get the best performance and efficiency.
DG-RePlAce uses a couple key ideas to do this placement more effectively. First, it analyzes the "dataflow" - how data moves between different parts of the chip. This gives it a better understanding of the chip's behavior and how to optimize the placement. Second, it uses the power of graphics processing units (GPUs) to speed up the placement optimization process, which can be very computationally intensive.
By combining dataflow analysis and GPU acceleration, DG-RePlAce can find good placements for ML accelerator chips faster than previous methods. This allows chip designers to explore more design options and ultimately create more powerful and efficient ML hardware.
Technical Explanation
The DG-RePlAce framework employs dataflow analysis and GPU acceleration to optimize the global placement of components in machine learning accelerator designs.
The key innovations include:
-
Dataflow-Driven Placement: DG-RePlAce models the dataflow between different modules on the chip and uses this to guide the placement optimization. This provides better insights into the chip's behavior compared to traditional placement approaches.
-
GPU Acceleration: The framework leverages the parallel processing capabilities of GPUs to speed up the computationally intensive global placement optimization. This allows exploring more design alternatives in less time.
-
Analytical Formulation: DG-RePlAce casts the placement problem as an analytical optimization, which can be solved efficiently using gradient-based methods. This is in contrast to previous placement approaches that rely on heuristics or reinforcement learning.
The authors evaluate DG-RePlAce on several industrial-scale ML accelerator designs and demonstrate significant improvements in placement quality and optimization runtime compared to state-of-the-art placement tools.
Critical Analysis
The authors present a compelling approach to accelerator placement optimization, but a few limitations and areas for further research are worth noting:
-
Dataflow Modeling Assumptions: The dataflow analysis in DG-RePlAce relies on certain assumptions about the structure and behavior of ML accelerators. While the authors show the approach works well for the evaluated designs, its generalizability to a wider range of accelerator architectures remains to be seen.
-
Hardware Integration: The paper does not discuss in detail how DG-RePlAce would integrate with existing hardware design flows. Seamless integration with popular electronic design automation (EDA) tools would be important for real-world adoption.
-
Specialized Hardware Support: Leveraging specialized hardware, such as processing-in-memory architectures, could further enhance the performance and efficiency of the placement optimizations. Exploring such hardware-software co-design opportunities could be a fruitful direction for future research.
Overall, DG-RePlAce represents a promising step forward in accelerator placement optimization, but continued research and development will be necessary to address the limitations and make the technology truly production-ready.
Conclusion
The DG-RePlAce framework introduces a novel approach to global placement for machine learning accelerators, leveraging dataflow analysis and GPU acceleration to achieve faster and more effective placement optimization. By modeling the underlying dataflow and harnessing the parallel processing power of GPUs, DG-RePlAce enables chip designers to explore more design alternatives and create more efficient and performant ML hardware. While the technique shows promise, further research is needed to improve its generalizability and integration with existing hardware design flows. Nonetheless, this work represents an important advancement in the field of accelerator design optimization.
Related Papers
FPGA Divide-and-Conquer Placement using Deep Reinforcement Learning
Shang Wang, Deepak Ranganatha Sastry Mamillapalli, Tianpei Yang, Matthew E. Taylor
0
0
This paper introduces the problem of learning to place logic blocks in Field-Programmable Gate Arrays (FPGAs) and a learning-based method. In contrast to previous search-based placement algorithms, we instead employ Reinforcement Learning (RL) with the goal of minimizing wirelength. In addition to our preliminary learning results, we also evaluated a novel decomposition to address the nature of large search space when placing many blocks on a chipboard. Empirical experiments evaluate the effectiveness of the learning and decomposition paradigms on FPGA placement tasks.
4/23/2024
🖼️
Chiplet Placement Order Exploration Based on Learning to Rank with Graph Representation
Zhihui Deng, Yuanyuan Duan, Leilai Shao, Xiaolei Zhu
0
0
Chiplet-based systems, integrating various silicon dies manufactured at different integrated circuit technology nodes on a carrier interposer, have garnered significant attention in recent years due to their cost-effectiveness and competitive performance. The widespread adoption of reinforcement learning as a sequential placement method has introduced a new challenge in determining the optimal placement order for each chiplet. The order in which chiplets are placed on the interposer influences the spatial resources available for earlier and later placed chiplets, making the placement results highly sensitive to the sequence of chiplet placement. To address these challenges, we propose a learning to rank approach with graph representation, building upon the reinforcement learning framework RLPlanner. This method aims to select the optimal chiplet placement order for each chiplet-based system. Experimental results demonstrate that compared to placement order obtained solely based on the descending order of the chiplet area and the number of interconnect wires between the chiplets, utilizing the placement order obtained from the learning to rank network leads to further improvements in system temperature and inter-chiplet wirelength. Specifically, applying the top-ranked placement order obtained from the learning to rank network results in a 10.05% reduction in total inter-chiplet wirelength and a 1.01% improvement in peak system temperature during the chiplet placement process.
4/9/2024
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
0
0
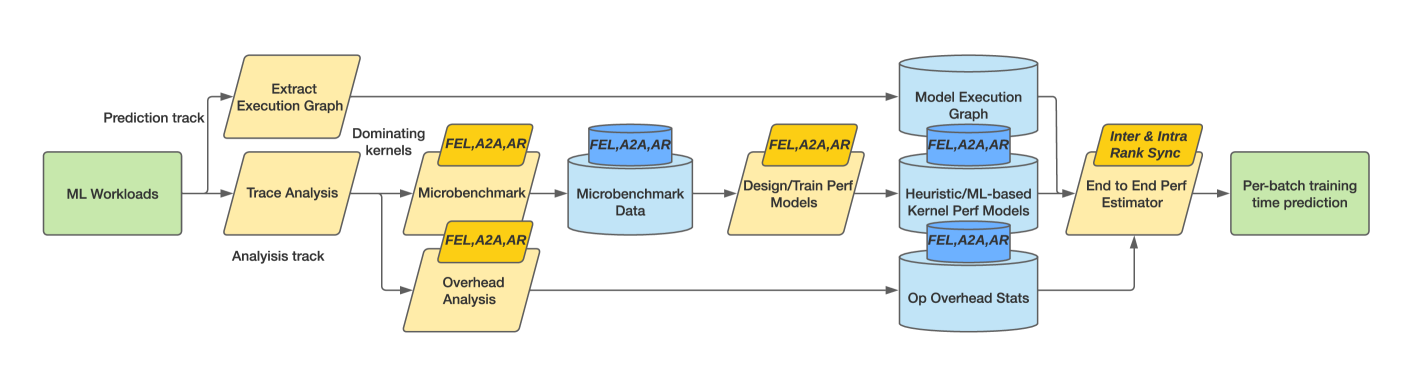
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
4/30/2024

Understanding the Potential of FPGA-Based Spatial Acceleration for Large Language Model Inference
Hongzheng Chen, Jiahao Zhang, Yixiao Du, Shaojie Xiang, Zichao Yue, Niansong Zhang, Yaohui Cai, Zhiru Zhang
0
0
Recent advancements in large language models (LLMs) boasting billions of parameters have generated a significant demand for efficient deployment in inference workloads. The majority of existing approaches rely on temporal architectures that reuse hardware units for different network layers and operators. However, these methods often encounter challenges in achieving low latency due to considerable memory access overhead. This paper investigates the feasibility and potential of model-specific spatial acceleration for LLM inference on FPGAs. Our approach involves the specialization of distinct hardware units for specific operators or layers, facilitating direct communication between them through a dataflow architecture while minimizing off-chip memory accesses. We introduce a comprehensive analytical model for estimating the performance of a spatial LLM accelerator, taking into account the on-chip compute and memory resources available on an FPGA. Through our analysis, we can determine the scenarios in which FPGA-based spatial acceleration can outperform its GPU-based counterpart. To enable more productive implementations of an LLM model on FPGAs, we further provide a library of high-level synthesis (HLS) kernels that are composable and reusable. This library will be made available as open-source. To validate the effectiveness of both our analytical model and HLS library, we have implemented BERT and GPT2 on an AMD Alveo U280 FPGA device. Experimental results demonstrate our approach can achieve up to 13.4x speedup when compared to previous FPGA-based accelerators for the BERT model. For GPT generative inference, we attain a 2.2x speedup compared to DFX, an FPGA overlay, in the prefill stage, while achieving a 1.9x speedup and a 5.7x improvement in energy efficiency compared to the NVIDIA A100 GPU in the decode stage.
4/9/2024