FPGA Divide-and-Conquer Placement using Deep Reinforcement Learning
2404.13061
2
0
Abstract
This paper introduces the problem of learning to place logic blocks in Field-Programmable Gate Arrays (FPGAs) and a learning-based method. In contrast to previous search-based placement algorithms, we instead employ Reinforcement Learning (RL) with the goal of minimizing wirelength. In addition to our preliminary learning results, we also evaluated a novel decomposition to address the nature of large search space when placing many blocks on a chipboard. Empirical experiments evaluate the effectiveness of the learning and decomposition paradigms on FPGA placement tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper presents a deep reinforcement learning approach for FPGA placement, a critical step in the electronic design automation (EDA) process.
- It introduces a divide-and-conquer strategy to tackle the complex FPGA placement problem, breaking it down into smaller, more manageable sub-problems.
- The proposed method leverages deep neural networks to learn efficient placement policies, aiming to outperform traditional EDA tools.
Plain English Explanation
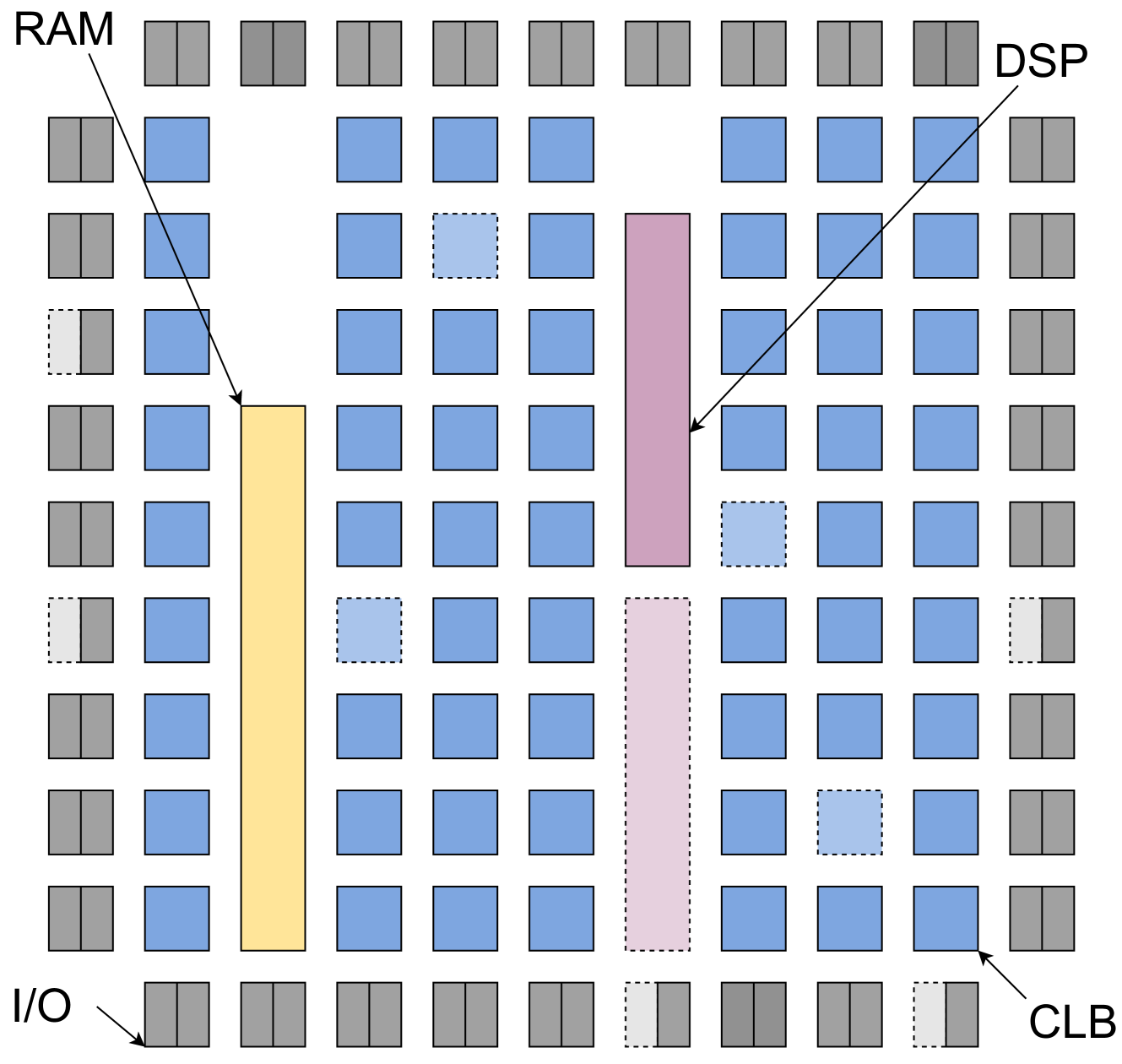
Field Programmable Gate Arrays (FPGAs) are a type of semiconductor device that can be programmed to perform specific tasks. Placing the various components of an FPGA design in the optimal locations is a crucial step in the FPGA placement process, as it significantly impacts the performance and efficiency of the final circuit.
The researchers in this paper recognized the complexity of the FPGA placement problem and developed a novel approach using deep reinforcement learning. Reinforcement learning is a type of machine learning where an agent learns to make decisions by interacting with an environment and receiving rewards or penalties for its actions.
The key idea is to break down the FPGA placement problem into smaller, more manageable sub-problems, using a "divide-and-conquer" strategy. This allows the deep neural network to learn placement policies for each sub-problem, rather than trying to solve the entire problem at once. The researchers train the neural network by having it explore different placement options and learn from the feedback it receives, much like a human learning a new skill through trial and error.
This divide-and-conquer approach, combined with the power of deep learning, aims to outperform traditional EDA tools for FPGA placement, leading to more efficient and high-performing FPGA designs.
Technical Explanation
The paper presents a deep reinforcement learning-based approach for FPGA placement, a critical step in the electronic design automation (EDA) process. The authors tackle the complex FPGA placement problem using a divide-and-conquer strategy, breaking it down into smaller, more manageable sub-problems.
The core of the proposed method is a deep neural network that learns efficient placement policies for each sub-problem. The neural network takes the current state of the FPGA placement problem as input and outputs a placement decision for the next set of components. The network is trained using deep reinforcement learning, where it explores different placement options and learns from the feedback it receives, aiming to maximize a reward signal that reflects the quality of the placement.
The divide-and-conquer strategy is implemented by recursively partitioning the FPGA area into smaller regions, and then assigning components to these regions using the trained neural network. This approach allows the system to tackle large-scale FPGA placement problems by breaking them down into smaller, more manageable sub-problems.
The researchers evaluate their method on a range of FPGA benchmark circuits and compare its performance to traditional EDA tools. The results demonstrate that the proposed deep reinforcement learning-based approach can outperform existing techniques, leading to more efficient and high-performing FPGA designs.
Critical Analysis
The paper presents a promising approach to FPGA placement using deep reinforcement learning, but there are a few potential limitations and areas for further research that could be explored.
One key concern is the computational complexity of the divide-and-conquer approach, which may still be challenging for very large FPGA designs. The authors mention that the method can handle large-scale problems, but the scalability of the technique could be further investigated, especially as FPGA designs continue to grow in size and complexity.
Additionally, the paper focuses on optimizing a single objective (e.g., wirelength or congestion), but in practice, FPGA placement often involves balancing multiple, sometimes conflicting objectives. Extending the approach to handle multi-objective optimization could be an interesting area for future research, as seen in constrained object placement using reinforcement learning.
Another potential limitation is the reliance on a single deep neural network for the entire placement process. Exploring alternative architectures, such as model-based deep reinforcement learning or advancing forest fire prevention with deep reinforcement learning, could lead to further improvements in placement quality and efficiency.
Overall, the paper presents a novel and promising approach to FPGA placement using deep reinforcement learning. While the method shows strong performance, the authors have identified several areas for potential improvement, which could be valuable avenues for future research in this field.
Conclusion
This paper introduces a deep reinforcement learning-based approach for FPGA placement, a critical step in the electronic design automation (EDA) process. The key innovation is the use of a divide-and-conquer strategy, where the complex FPGA placement problem is broken down into smaller, more manageable sub-problems.
The proposed method leverages deep neural networks to learn efficient placement policies for each sub-problem, aiming to outperform traditional EDA tools. The results demonstrate the effectiveness of this approach, which could lead to more efficient and high-performing FPGA designs.
While the paper presents a promising solution, there are opportunities for further research to address potential limitations, such as scalability, multi-objective optimization, and alternative neural network architectures. Continued advancements in this area could have significant implications for the field of electronic design automation and the development of more powerful and energy-efficient FPGA-based systems.
Related Papers
DG-RePlAce: A Dataflow-Driven GPU-Accelerated Analytical Global Placement Framework for Machine Learning Accelerators
Andrew B. Kahng, Zhiang Wang
0
0
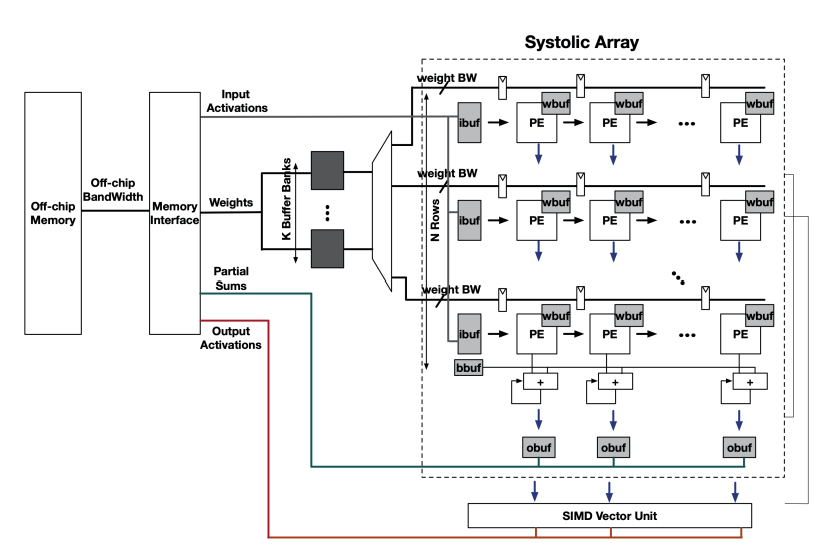
Global placement is a fundamental step in VLSI physical design. The wide use of 2D processing element (PE) arrays in machine learning accelerators poses new challenges of scalability and Quality of Results (QoR) for state-of-the-art academic global placers. In this work, we develop DG-RePlAce, a new and fast GPU-accelerated global placement framework built on top of the OpenROAD infrastructure, which exploits the inherent dataflow and datapath structures of machine learning accelerators. Experimental results with a variety of machine learning accelerators using a commercial 12nm enablement show that, compared with RePlAce (DREAMPlace), our approach achieves an average reduction in routed wirelength by 10% (7%) and total negative slack (TNS) by 31% (34%), with faster global placement and on-par total runtimes relative to DREAMPlace. Empirical studies on the TILOS MacroPlacement Benchmarks further demonstrate that post-route improvements over RePlAce and DREAMPlace may reach beyond the motivating application to machine learning accelerators.
4/23/2024
🖼️
Chiplet Placement Order Exploration Based on Learning to Rank with Graph Representation
Zhihui Deng, Yuanyuan Duan, Leilai Shao, Xiaolei Zhu
0
0
Chiplet-based systems, integrating various silicon dies manufactured at different integrated circuit technology nodes on a carrier interposer, have garnered significant attention in recent years due to their cost-effectiveness and competitive performance. The widespread adoption of reinforcement learning as a sequential placement method has introduced a new challenge in determining the optimal placement order for each chiplet. The order in which chiplets are placed on the interposer influences the spatial resources available for earlier and later placed chiplets, making the placement results highly sensitive to the sequence of chiplet placement. To address these challenges, we propose a learning to rank approach with graph representation, building upon the reinforcement learning framework RLPlanner. This method aims to select the optimal chiplet placement order for each chiplet-based system. Experimental results demonstrate that compared to placement order obtained solely based on the descending order of the chiplet area and the number of interconnect wires between the chiplets, utilizing the placement order obtained from the learning to rank network leads to further improvements in system temperature and inter-chiplet wirelength. Specifically, applying the top-ranked placement order obtained from the learning to rank network results in a 10.05% reduction in total inter-chiplet wirelength and a 1.01% improvement in peak system temperature during the chiplet placement process.
4/9/2024
Advancing Forest Fire Prevention: Deep Reinforcement Learning for Effective Firebreak Placement
Lucas Murray, Tatiana Castillo, Jaime Carrasco, Andr'es Weintraub, Richard Weber, Isaac Mart'in de Diego, Jos'e Ram'on Gonz'alez, Jordi Garc'ia-Gonzalo
0
0
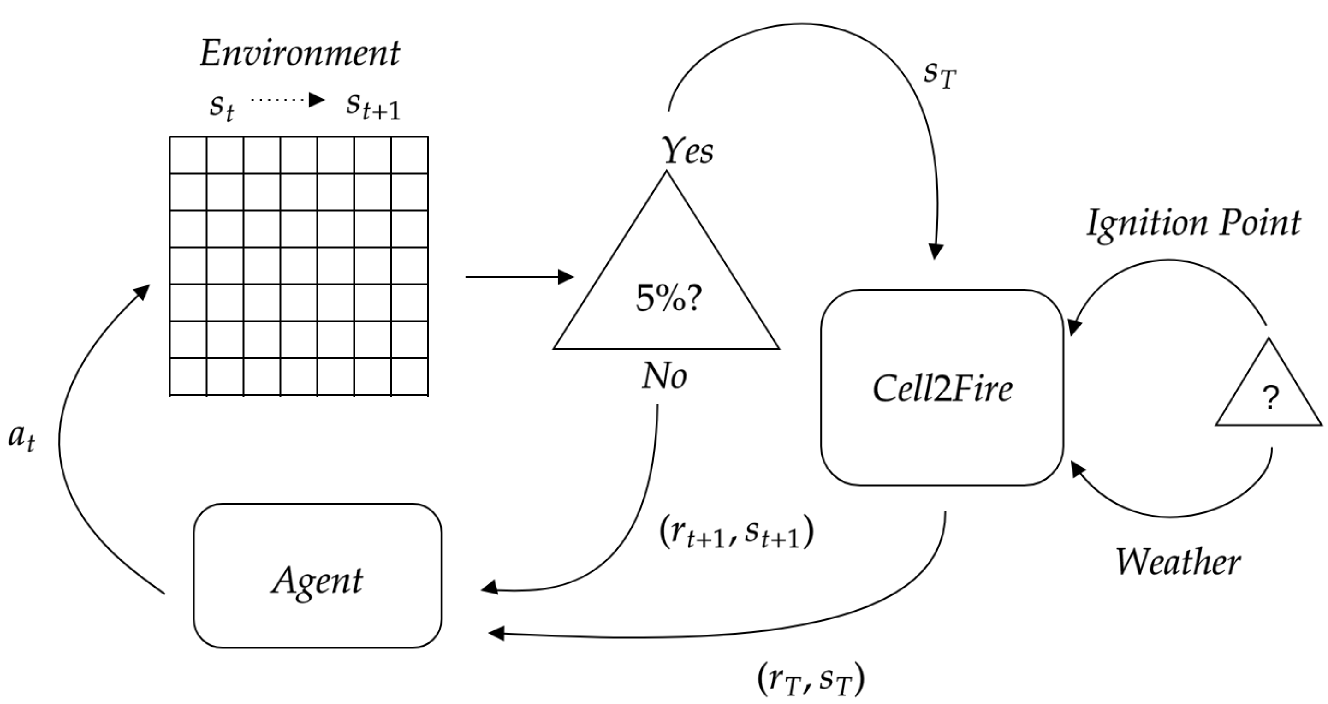
Over the past decades, the increase in both frequency and intensity of large-scale wildfires due to climate change has emerged as a significant natural threat. The pressing need to design resilient landscapes capable of withstanding such disasters has become paramount, requiring the development of advanced decision-support tools. Existing methodologies, including Mixed Integer Programming, Stochastic Optimization, and Network Theory, have proven effective but are hindered by computational demands, limiting their applicability. In response to this challenge, we propose using artificial intelligence techniques, specifically Deep Reinforcement Learning, to address the complex problem of firebreak placement in the landscape. We employ value-function based approaches like Deep Q-Learning, Double Deep Q-Learning, and Dueling Double Deep Q-Learning. Utilizing the Cell2Fire fire spread simulator combined with Convolutional Neural Networks, we have successfully implemented a computational agent capable of learning firebreak locations within a forest environment, achieving good results. Furthermore, we incorporate a pre-training loop, initially teaching our agent to mimic a heuristic-based algorithm and observe that it consistently exceeds the performance of these solutions. Our findings underscore the immense potential of Deep Reinforcement Learning for operational research challenges, especially in fire prevention. Our approach demonstrates convergence with highly favorable results in problem instances as large as 40 x 40 cells, marking a significant milestone in applying Reinforcement Learning to this critical issue. To the best of our knowledge, this study represents a pioneering effort in using Reinforcement Learning to address the aforementioned problem, offering promising perspectives in fire prevention and landscape management
4/15/2024
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner, Janis Geise
0
0
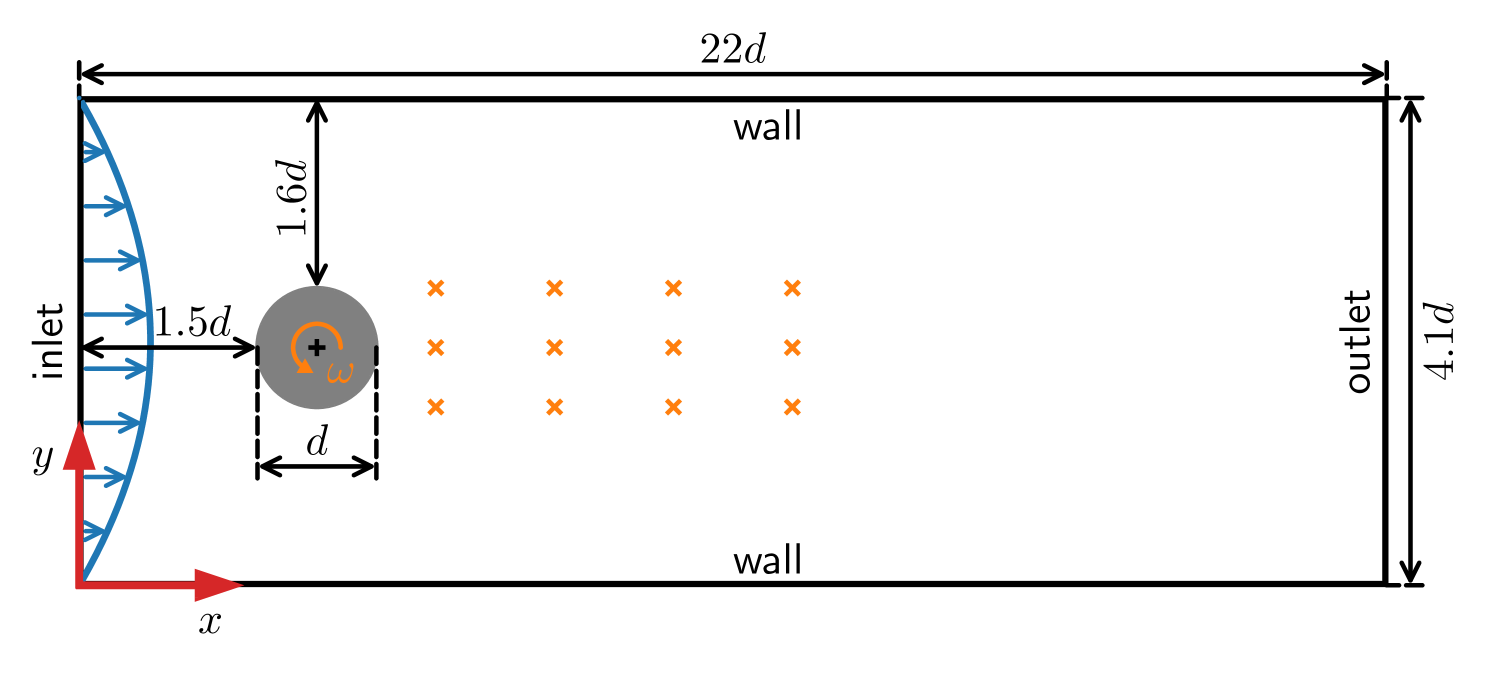
In recent years, deep reinforcement learning has emerged as a technique to solve closed-loop flow control problems. Employing simulation-based environments in reinforcement learning enables a priori end-to-end optimization of the control system, provides a virtual testbed for safety-critical control applications, and allows to gain a deep understanding of the control mechanisms. While reinforcement learning has been applied successfully in a number of rather simple flow control benchmarks, a major bottleneck toward real-world applications is the high computational cost and turnaround time of flow simulations. In this contribution, we demonstrate the benefits of model-based reinforcement learning for flow control applications. Specifically, we optimize the policy by alternating between trajectories sampled from flow simulations and trajectories sampled from an ensemble of environment models. The model-based learning reduces the overall training time by up to $85%$ for the fluidic pinball test case. Even larger savings are expected for more demanding flow simulations.
4/11/2024