DGD: Dynamic 3D Gaussians Distillation
2405.19321
0
0
Abstract
We tackle the task of learning dynamic 3D semantic radiance fields given a single monocular video as input. Our learned semantic radiance field captures per-point semantics as well as color and geometric properties for a dynamic 3D scene, enabling the generation of novel views and their corresponding semantics. This enables the segmentation and tracking of a diverse set of 3D semantic entities, specified using a simple and intuitive interface that includes a user click or a text prompt. To this end, we present DGD, a unified 3D representation for both the appearance and semantics of a dynamic 3D scene, building upon the recently proposed dynamic 3D Gaussians representation. Our representation is optimized over time with both color and semantic information. Key to our method is the joint optimization of the appearance and semantic attributes, which jointly affect the geometric properties of the scene. We evaluate our approach in its ability to enable dense semantic 3D object tracking and demonstrate high-quality results that are fast to render, for a diverse set of scenes. Our project webpage is available on https://isaaclabe.github.io/DGD-Website/
Create account to get full access
Overview
- This paper introduces a novel method called "Dynamic 3D Gaussians Distillation" (DGD) for representing and reconstructing dynamic 3D scenes from multi-view video inputs.
- The key idea is to represent the 3D scene as a set of dynamic 3D Gaussian primitives, which can capture both the geometry and appearance of dynamic objects.
- The authors propose a distillation-based training approach to efficiently learn the dynamic 3D Gaussian representations from real-world multi-view video data.
- The DGD method is shown to outperform state-of-the-art techniques for high-quality dynamic 3D reconstruction and enables real-time rendering of the reconstructed scenes.
Plain English Explanation
The paper presents a new way to capture and reconstruct 3D scenes that contain moving objects. Rather than representing the scene as a static 3D model, the researchers use a collection of dynamic 3D Gaussian shapes to model both the geometry and appearance of the objects. This allows the system to better capture the motion and changing properties of the objects over time.
The key innovation is the "distillation-based training approach" which efficiently learns these dynamic 3D Gaussian representations from real-world multi-view video data. This makes the system practical for working with actual video footage, rather than relying on specialized 3D scanning hardware.
The DGD: Dynamic 3D Gaussians Distillation method is shown to produce higher quality 3D reconstructions of dynamic scenes compared to previous techniques. It can also render these reconstructions in real-time, which opens up new applications in areas like AR/VR, robotics, and video editing.
Technical Explanation
The paper introduces the Dynamic 3D Gaussians Distillation (DGD) method for representing and reconstructing dynamic 3D scenes from multi-view video inputs. The key insight is to model the 3D scene as a collection of dynamic 3D Gaussian primitives, which can capture both the geometry and appearance of moving objects.
To efficiently learn these dynamic 3D Gaussian representations, the authors propose a distillation-based training approach. This involves first training a teacher network to predict the dynamic 3D scene from the multi-view video input. The student network then learns to mimic the teacher's outputs, but with a more compact representation using the dynamic 3D Gaussians.
The DGD method is evaluated on several challenging real-world multi-view video datasets. The results show that it outperforms state-of-the-art techniques like Dynamic Gaussians for Mesh-Consistent Mesh Reconstruction from and 3D Geometry-Aware Deformable Gaussian Splatting for Dynamic in terms of reconstruction quality and rendering speed. The dynamic 3D Gaussian representation also enables applications like RT-GS2: Real-Time Generalizable Semantic Segmentation and Feature-3DGS: Supercharging 3D Gaussian Splatting To.
Critical Analysis
The paper presents a compelling approach to dynamic 3D scene reconstruction that addresses some key limitations of prior methods. The use of dynamic 3D Gaussian primitives allows the DGD method to faithfully capture both the geometry and time-varying appearance of moving objects.
However, the paper does not discuss the scalability of the approach as the complexity of the scene increases. It's unclear how well the dynamic 3D Gaussian representations would scale to large, crowded scenes with many interacting objects. Additionally, the distillation-based training process, while efficient, may limit the method's ability to generalize to completely novel scenes and object types.
Further research could explore ways to make the dynamic 3D Gaussian representations more flexible and generalizable, perhaps through the use of more advanced neural architectures or training strategies. Investigating the computational and memory requirements of the approach at scale would also be an important avenue for future work.
Overall, the DGD method represents an intriguing step forward in dynamic 3D scene reconstruction, with the potential to enable a new generation of immersive AR/VR experiences and advanced robotic systems. However, there are still some open challenges that need to be addressed before the technique can be widely adopted.
Conclusion
The DGD: Dynamic 3D Gaussians Distillation paper presents a novel approach for reconstructing and representing dynamic 3D scenes from multi-view video inputs. By modeling the scene as a set of dynamic 3D Gaussian primitives, the method can capture both the geometry and time-varying appearance of moving objects.
The key innovation is the distillation-based training process, which efficiently learns these dynamic 3D Gaussian representations from real-world data. This makes the DGD method practical for working with actual video footage, rather than relying on specialized 3D scanning hardware.
The results show that DGD outperforms state-of-the-art techniques in terms of reconstruction quality and rendering speed. This opens up new possibilities for applications in areas like AR/VR, robotics, and video editing, where high-fidelity, real-time 3D scene reconstruction is crucial.
While the paper presents a compelling approach, there are still some open challenges around scalability and generalization that warrant further research. Nonetheless, the DGD method represents a significant step forward in dynamic 3D scene understanding and reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Dynamic 3D Gaussian Fields for Urban Areas
Tobias Fischer, Jonas Kulhanek, Samuel Rota Bul`o, Lorenzo Porzi, Marc Pollefeys, Peter Kontschieder
0
0
We present an efficient neural 3D scene representation for novel-view synthesis (NVS) in large-scale, dynamic urban areas. Existing works are not well suited for applications like mixed-reality or closed-loop simulation due to their limited visual quality and non-interactive rendering speeds. Recently, rasterization-based approaches have achieved high-quality NVS at impressive speeds. However, these methods are limited to small-scale, homogeneous data, i.e. they cannot handle severe appearance and geometry variations due to weather, season, and lighting and do not scale to larger, dynamic areas with thousands of images. We propose 4DGF, a neural scene representation that scales to large-scale dynamic urban areas, handles heterogeneous input data, and substantially improves rendering speeds. We use 3D Gaussians as an efficient geometry scaffold while relying on neural fields as a compact and flexible appearance model. We integrate scene dynamics via a scene graph at global scale while modeling articulated motions on a local level via deformations. This decomposed approach enables flexible scene composition suitable for real-world applications. In experiments, we surpass the state-of-the-art by over 3 dB in PSNR and more than 200 times in rendering speed.
6/6/2024
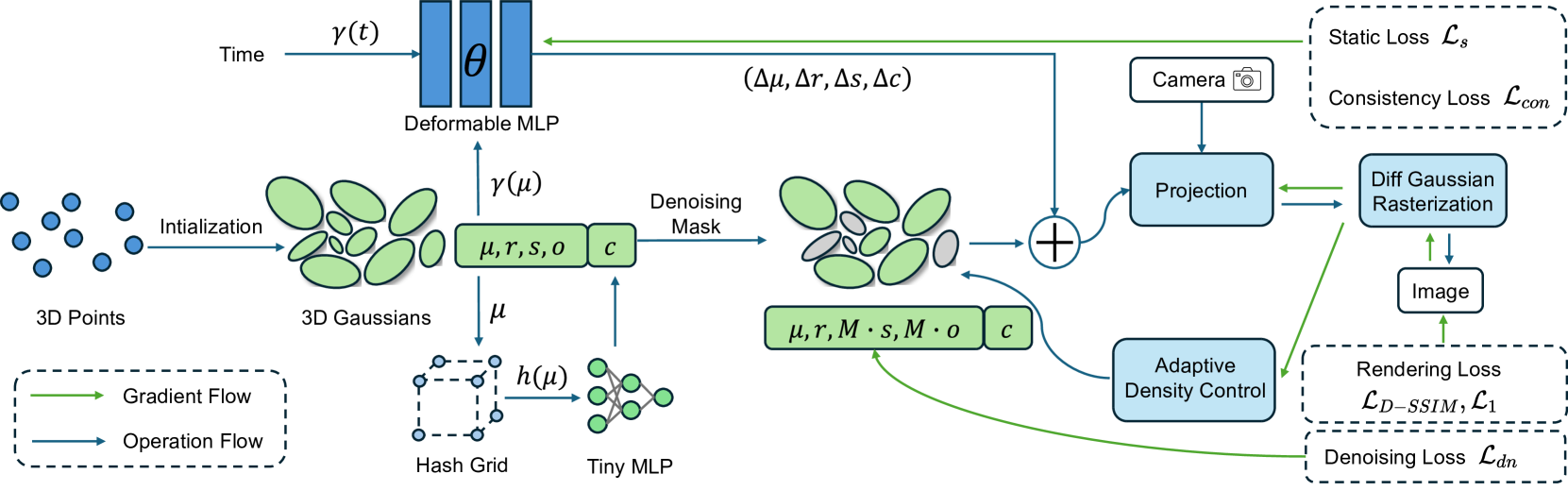
A Refined 3D Gaussian Representation for High-Quality Dynamic Scene Reconstruction
Bin Zhang, Bi Zeng, Zexin Peng
0
0
In recent years, Neural Radiance Fields (NeRF) has revolutionized three-dimensional (3D) reconstruction with its implicit representation. Building upon NeRF, 3D Gaussian Splatting (3D-GS) has departed from the implicit representation of neural networks and instead directly represents scenes as point clouds with Gaussian-shaped distributions. While this shift has notably elevated the rendering quality and speed of radiance fields but inevitably led to a significant increase in memory usage. Additionally, effectively rendering dynamic scenes in 3D-GS has emerged as a pressing challenge. To address these concerns, this paper purposes a refined 3D Gaussian representation for high-quality dynamic scene reconstruction. Firstly, we use a deformable multi-layer perceptron (MLP) network to capture the dynamic offset of Gaussian points and express the color features of points through hash encoding and a tiny MLP to reduce storage requirements. Subsequently, we introduce a learnable denoising mask coupled with denoising loss to eliminate noise points from the scene, thereby further compressing 3D Gaussian model. Finally, motion noise of points is mitigated through static constraints and motion consistency constraints. Experimental results demonstrate that our method surpasses existing approaches in rendering quality and speed, while significantly reducing the memory usage associated with 3D-GS, making it highly suitable for various tasks such as novel view synthesis, and dynamic mapping.
5/29/2024
🤷
Dynamic Gaussians Mesh: Consistent Mesh Reconstruction from Monocular Videos
Isabella Liu, Hao Su, Xiaolong Wang
0
0
Modern 3D engines and graphics pipelines require mesh as a memory-efficient representation, which allows efficient rendering, geometry processing, texture editing, and many other downstream operations. However, it is still highly difficult to obtain high-quality mesh in terms of structure and detail from monocular visual observations. The problem becomes even more challenging for dynamic scenes and objects. To this end, we introduce Dynamic Gaussians Mesh (DG-Mesh), a framework to reconstruct a high-fidelity and time-consistent mesh given a single monocular video. Our work leverages the recent advancement in 3D Gaussian Splatting to construct the mesh sequence with temporal consistency from a video. Building on top of this representation, DG-Mesh recovers high-quality meshes from the Gaussian points and can track the mesh vertices over time, which enables applications such as texture editing on dynamic objects. We introduce the Gaussian-Mesh Anchoring, which encourages evenly distributed Gaussians, resulting better mesh reconstruction through mesh-guided densification and pruning on the deformed Gaussians. By applying cycle-consistent deformation between the canonical and the deformed space, we can project the anchored Gaussian back to the canonical space and optimize Gaussians across all time frames. During the evaluation on different datasets, DG-Mesh provides significantly better mesh reconstruction and rendering than baselines. Project page: https://www.liuisabella.com/DG-Mesh/
4/23/2024

VDG: Vision-Only Dynamic Gaussian for Driving Simulation
Hao Li, Jingfeng Li, Dingwen Zhang, Chenming Wu, Jieqi Shi, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, Junwei Han
0
0
Dynamic Gaussian splatting has led to impressive scene reconstruction and image synthesis advances in novel views. Existing methods, however, heavily rely on pre-computed poses and Gaussian initialization by Structure from Motion (SfM) algorithms or expensive sensors. For the first time, this paper addresses this issue by integrating self-supervised VO into our pose-free dynamic Gaussian method (VDG) to boost pose and depth initialization and static-dynamic decomposition. Moreover, VDG can work with only RGB image input and construct dynamic scenes at a faster speed and larger scenes compared with the pose-free dynamic view-synthesis method. We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods. Additional video and source code will be posted on our project page at https://3d-aigc.github.io/VDG.
6/27/2024