DiarizationLM: Speaker Diarization Post-Processing with Large Language Models

0

Sign in to get full access
Overview
- This paper introduces "DiarizationLM," a novel approach to post-processing speaker diarization outputs using large language models (LLMs).
- Speaker diarization is the task of identifying who is speaking when in an audio recording, which is crucial for applications like meeting transcription and call center analytics.
- The authors demonstrate how LLMs can be leveraged to significantly improve the performance of existing diarization systems, especially in challenging scenarios with overlapping speech or unclear speaker turns.
Plain English Explanation
The paper describes a new method called "DiarizationLM" that uses powerful language models to improve the accuracy of speaker diarization - the process of identifying who is speaking at different points in an audio recording. Speaker diarization is an important task for applications like transcribing meetings or analyzing customer service calls, as it allows the different speakers to be separated out.
Traditionally, speaker diarization has been done using specialized speech processing algorithms. However, the authors of this paper found that by incorporating large language models - the same type of AI models that power conversational assistants like ChatGPT - they could significantly boost the performance of diarization systems, especially in challenging scenarios where there is overlapping speech or it's unclear when one speaker stops and another starts.
The key insight is that these language models have a deep understanding of natural language and conversation, which allows them to "fill in the gaps" and correct errors made by the initial diarization process. This can make the final output much more accurate and coherent.
The paper walks through a detailed example showing how DiarizationLM works and demonstrates its effectiveness on benchmark datasets. Overall, this research represents an exciting advancement in the field of speaker diarization, with the potential to enable more reliable speech processing for a wide range of real-world applications.
Technical Explanation
The authors of this paper propose a novel approach called "DiarizationLM" that leverages large language models (LLMs) to enhance the performance of speaker diarization systems. Speaker diarization is the task of identifying who is speaking when in an audio recording, which is a crucial preprocessing step for applications such as meeting transcription and call center analytics.
Traditionally, speaker diarization has been approached using specialized speech processing algorithms that analyze acoustic cues to segment the audio and cluster the resulting speaker turns. However, these methods can struggle in challenging scenarios involving overlapping speech or unclear speaker transitions. The key innovation in DiarizationLM is to incorporate the powerful language understanding capabilities of LLMs to "post-process" the output of a base diarization system and correct such errors.
The DiarizationLM architecture [^1] consists of a base diarization model that generates an initial set of speaker labels, which are then fed into an LLM-based classifier. This classifier examines the sequence of speaker labels and associated audio segments, leveraging its deep knowledge of natural language and conversational patterns to identify and fix potential inconsistencies or mistakes in the diarization output.
[^1]: The authors evaluate DiarizationLM using several different LLM backbones, including BERT, RoBERTa, and wav2vec 2.0, demonstrating the flexibility of their approach.
Through extensive experiments on benchmark datasets, the authors show that DiarizationLM can significantly outperform traditional diarization methods, reducing diarization error rates by up to 30% in some cases. They attribute this performance boost to the LLM's ability to leverage higher-level linguistic cues and contextual information that would be difficult to capture using only acoustic features.
Critical Analysis
The DiarizationLM approach represents an exciting and promising direction in the field of speaker diarization. By seamlessly integrating powerful language models, the authors have demonstrated a novel way to enhance the capabilities of existing diarization systems, particularly in challenging scenarios.
That said, the paper does acknowledge some limitations of the proposed method. For example, the authors note that DiarizationLM may be less effective in situations with a large number of speakers or very short speaker turns, as the LLM may have difficulty learning reliable patterns from the limited input data. Additionally, the computational cost of running the LLM inference as a post-processing step could be a concern for real-time applications.
Further research could explore ways to address these limitations, such as investigating more efficient LLM architectures or exploring alternative integration strategies between the base diarization model and the language-based post-processor. It would also be valuable to see how DiarizationLM performs on a wider range of real-world datasets and application scenarios.
Overall, this paper makes a compelling case for the potential of leveraging large language models to advance the state of the art in speaker diarization. As LLMs continue to grow in capability and become more widely accessible, approaches like DiarizationLM are likely to play an increasingly important role in enabling more accurate and robust speech processing systems.
Conclusion
The DiarizationLM paper introduces a novel method for improving speaker diarization by incorporating large language models (LLMs) as a post-processing step. By taking advantage of LLMs' deep understanding of natural language and conversational patterns, the authors demonstrate that they can significantly enhance the performance of existing diarization systems, particularly in challenging scenarios involving overlapping speech or unclear speaker transitions.
This research represents an exciting advancement in the field of speaker diarization, with the potential to enable more reliable speech processing for a wide range of real-world applications, from meeting transcription to call center analytics. While the approach has some limitations, the authors' work highlights the promising opportunities that arise from integrating the latest breakthroughs in language modeling with specialized speech processing tasks.
As LLMs continue to evolve and become more widely accessible, we can expect to see further innovations at the intersection of speech and language technologies, with DiarizationLM serving as an inspiring example of how these powerful AI models can be leveraged to push the boundaries of what's possible in real-world speech processing applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DiarizationLM: Speaker Diarization Post-Processing with Large Language Models
Quan Wang, Yiling Huang, Guanlong Zhao, Evan Clark, Wei Xia, Hank Liao
In this paper, we introduce DiarizationLM, a framework to leverage large language models (LLM) to post-process the outputs from a speaker diarization system. Various goals can be achieved with the proposed framework, such as improving the readability of the diarized transcript, or reducing the word diarization error rate (WDER). In this framework, the outputs of the automatic speech recognition (ASR) and speaker diarization systems are represented as a compact textual format, which is included in the prompt to an optionally finetuned LLM. The outputs of the LLM can be used as the refined diarization results with the desired enhancement. As a post-processing step, this framework can be easily applied to any off-the-shelf ASR and speaker diarization systems without retraining existing components. Our experiments show that a finetuned PaLM 2-S model can reduce the WDER by rel. 55.5% on the Fisher telephone conversation dataset, and rel. 44.9% on the Callhome English dataset.
Read more6/5/2024
0
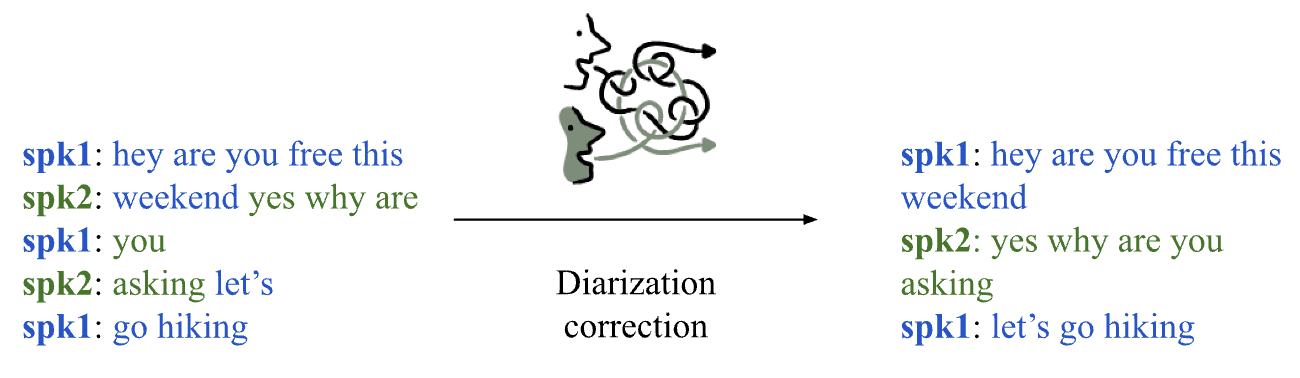
LLM-based speaker diarization correction: A generalizable approach
Georgios Efstathiadis, Vijay Yadav, Anzar Abbas
Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We hope to make these models accessible through public-facing APIs for use by third-party applications.
Read more6/10/2024

0
Multi-stage Large Language Model Correction for Speech Recognition
Jie Pu, Thai-Son Nguyen, Sebastian Stuker
In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from previous LLM-based ASR error correction methods, we propose a novel multi-stage approach that utilizes uncertainty estimation of ASR outputs and reasoning capability of LLMs. Specifically, the proposed approach has two stages: the first stage is about ASR uncertainty estimation and exploits N-best list hypotheses to identify less reliable transcriptions; The second stage works on these identified transcriptions and performs LLM-based corrections. This correction task is formulated as a multi-step rule-based LLM reasoning process, which uses explicitly written rules in prompts to decompose the task into concrete reasoning steps. Our experimental results demonstrate the effectiveness of the proposed method by showing 10% ~ 20% relative improvement in WER over competitive ASR systems -- across multiple test domains and in zero-shot settings.
Read more6/18/2024
0
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
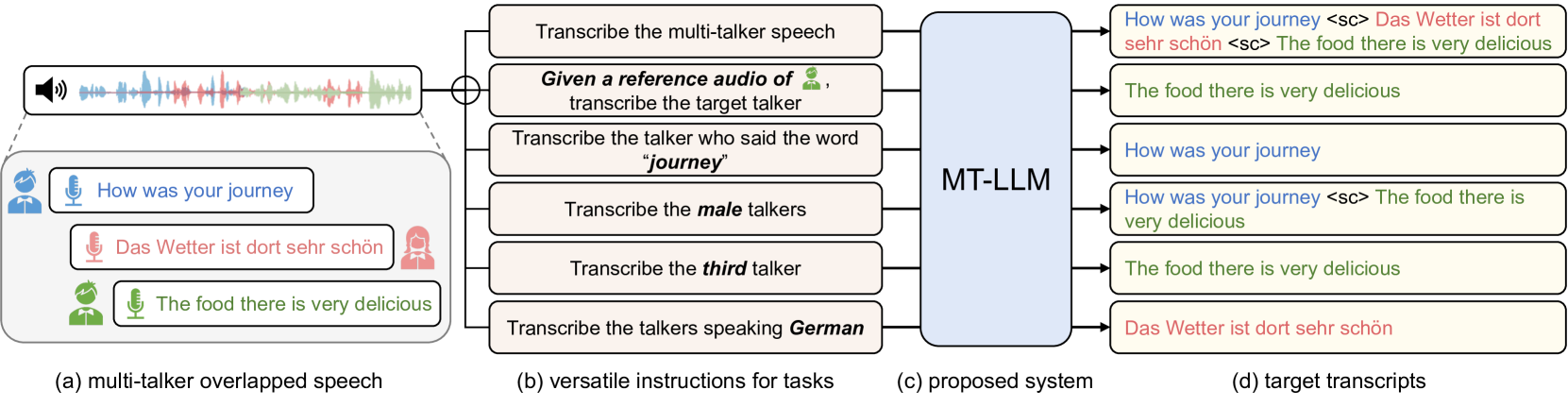
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024