Diff3Dformer: Leveraging Slice Sequence Diffusion for Enhanced 3D CT Classification with Transformer Networks
2406.17173
0
0

Abstract
The manifestation of symptoms associated with lung diseases can vary in different depths for individual patients, highlighting the significance of 3D information in CT scans for medical image classification. While Vision Transformer has shown superior performance over convolutional neural networks in image classification tasks, their effectiveness is often demonstrated on sufficiently large 2D datasets and they easily encounter overfitting issues on small medical image datasets. To address this limitation, we propose a Diffusion-based 3D Vision Transformer (Diff3Dformer), which utilizes the latent space of the Diffusion model to form the slice sequence for 3D analysis and incorporates clustering attention into ViT to aggregate repetitive information within 3D CT scans, thereby harnessing the power of the advanced transformer in 3D classification tasks on small datasets. Our method exhibits improved performance on two different scales of small datasets of 3D lung CT scans, surpassing the state of the art 3D methods and other transformer-based approaches that emerged during the COVID-19 pandemic, demonstrating its robust and superior performance across different scales of data. Experimental results underscore the superiority of our proposed method, indicating its potential for enhancing medical image classification tasks in real-world scenarios.
Create account to get full access
Overview
- This paper introduces a new deep learning model called Diff3Dformer that leverages slice sequence diffusion for enhanced 3D CT classification with transformer networks.
- The model aims to improve the performance of 3D CT image classification tasks, such as lung disease detection, by incorporating diffusion-based techniques and transformer architectures.
- The key innovations include: 1) using slice sequence diffusion to capture the 3D structure of CT scans, 2) designing a transformer-based network to effectively process the diffused 3D information, and 3) demonstrating the model's effectiveness on 3D CT classification benchmarks.
Plain English Explanation
The paper introduces a new deep learning model called Diff3Dformer that combines two powerful techniques - diffusion models and transformer networks - to improve the classification of 3D medical images, such as CT scans of the lung.
Diffusion models are a type of generative AI that can create realistic images by gradually adding "noise" to an input and then learning to reverse that process. The authors use this technique to capture the 3D structure of the CT scans, preserving important spatial information that can be critical for medical diagnosis.
They then feed this diffused 3D data into a transformer network - an AI model that excels at processing sequential information, like the slices that make up a 3D CT scan. The transformer is able to efficiently extract relevant features and patterns from the 3D data, leading to more accurate classification of lung diseases and other conditions.
By combining these two powerful AI techniques, the Diff3Dformer model is able to outperform previous approaches on standard 3D CT classification benchmarks. This could have important implications for improving the speed and accuracy of medical diagnoses based on 3D imaging data.
Technical Explanation
The key technical innovations in the Diff3Dformer model are:
-
Slice Sequence Diffusion: The authors leverage a diffusion-based approach to capture the 3D structure of CT scans. They treat the 2D slices of a 3D CT volume as a sequence and apply a diffusion process to gradually add noise to this sequence. This allows the model to learn the underlying 3D distribution of the CT data, preserving important spatial information.
-
Transformer-based Architecture: The authors design a transformer-based network to process the diffused 3D CT data. Transformers are well-suited for this task as they can effectively extract features and patterns from sequential inputs, like the slices of a 3D volume. The transformer-based design enables the model to efficiently process the 3D information and make accurate predictions.
-
Evaluation on 3D CT Classification Tasks: The authors evaluate the Diff3Dformer model on standard 3D CT classification benchmarks, including lung disease detection. They demonstrate that the model outperforms previous state-of-the-art approaches, highlighting the benefits of combining diffusion-based techniques and transformer networks for 3D medical image analysis.
Critical Analysis
The Diff3Dformer paper presents a novel and promising approach for improving 3D CT image classification, but there are a few potential limitations and areas for further research:
-
Computational Complexity: Diffusion models and transformer networks can be computationally intensive, which may limit the practical deployment of the Diff3Dformer model, especially for real-time applications. The authors could explore ways to optimize the model's efficiency or investigate alternative architectures that maintain performance while reducing computational requirements.
-
Interpretability: As with many deep learning models, the internal workings of Diff3Dformer may be difficult to interpret, which can be a concern in high-stakes medical applications. The authors could investigate techniques to improve the model's interpretability, such as saliency maps or feature visualization, to help clinicians understand the model's decision-making process.
-
Generalization to Other Medical Imaging Modalities: The paper focuses on 3D CT classification, but the techniques could potentially be extended to other 3D medical imaging modalities, such as MRI. Further research could investigate the effectiveness of the Diff3Dformer approach on a wider range of 3D medical imaging tasks and datasets.
Overall, the Diff3Dformer paper presents a compelling approach that leverages the strengths of diffusion models and transformer networks to advance the state-of-the-art in 3D CT image classification. With further research and optimization, this model could have significant practical implications for improving medical diagnosis and treatment.
Conclusion
The Diff3Dformer paper introduces a novel deep learning model that combines diffusion-based techniques and transformer networks to enhance the performance of 3D CT image classification tasks, such as lung disease detection. By leveraging slice sequence diffusion to capture the 3D structure of CT scans and using a transformer-based architecture to effectively process the diffused 3D information, the authors demonstrate significant improvements over previous state-of-the-art approaches.
This research highlights the potential of integrating different AI techniques, like diffusion models and transformers, to tackle complex 3D medical imaging challenges. The Diff3Dformer model could have important implications for improving the speed and accuracy of medical diagnoses based on 3D imaging data, potentially leading to better patient outcomes and more efficient healthcare systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
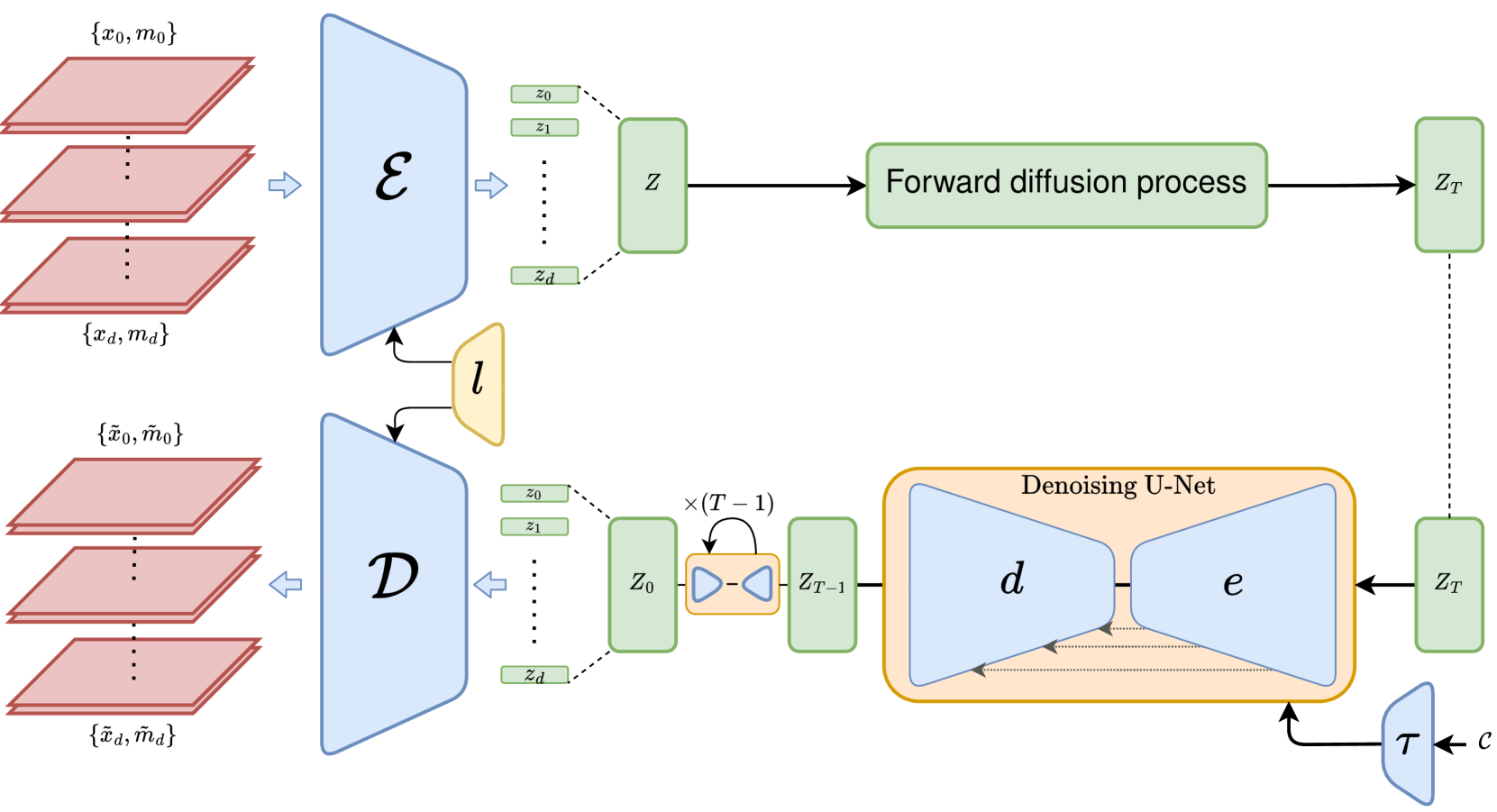
3D MRI Synthesis with Slice-Based Latent Diffusion Models: Improving Tumor Segmentation Tasks in Data-Scarce Regimes
Aghiles Kebaili, J'er^ome Lapuyade-Lahorgue, Pierre Vera, Su Ruan
0
0
Despite the increasing use of deep learning in medical image segmentation, the limited availability of annotated training data remains a major challenge due to the time-consuming data acquisition and privacy regulations. In the context of segmentation tasks, providing both medical images and their corresponding target masks is essential. However, conventional data augmentation approaches mainly focus on image synthesis. In this study, we propose a novel slice-based latent diffusion architecture designed to address the complexities of volumetric data generation in a slice-by-slice fashion. This approach extends the joint distribution modeling of medical images and their associated masks, allowing a simultaneous generation of both under data-scarce regimes. Our approach mitigates the computational complexity and memory expensiveness typically associated with diffusion models. Furthermore, our architecture can be conditioned by tumor characteristics, including size, shape, and relative position, thereby providing a diverse range of tumor variations. Experiments on a segmentation task using the BRATS2022 confirm the effectiveness of the synthesized volumes and masks for data augmentation.
6/11/2024

DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
Ziang Cao, Fangzhou Hong, Tong Wu, Liang Pan, Ziwei Liu
0
0
Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
5/15/2024
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
0
0
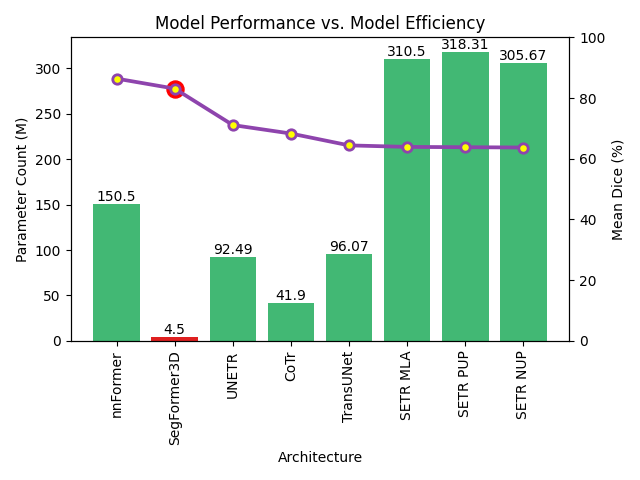
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
4/17/2024
DiffusionBlend: Learning 3D Image Prior through Position-aware Diffusion Score Blending for 3D Computed Tomography Reconstruction
Bowen Song, Jason Hu, Zhaoxu Luo, Jeffrey A. Fessler, Liyue Shen
0
0
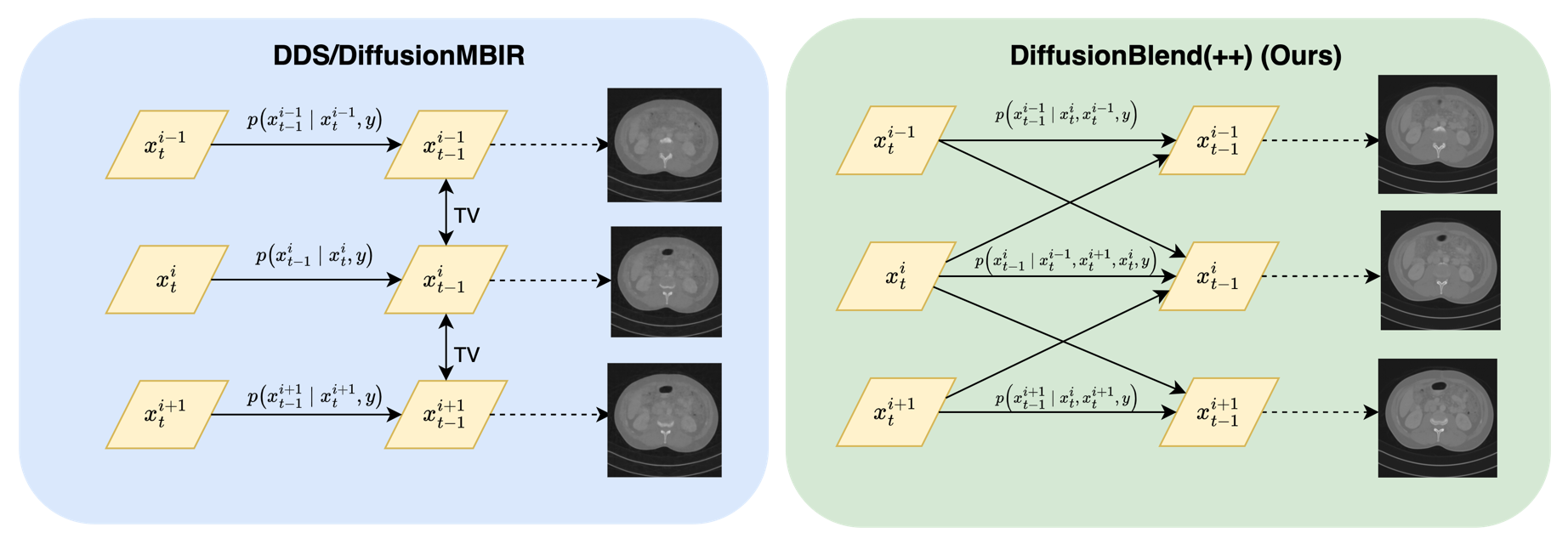
Diffusion models face significant challenges when employed for large-scale medical image reconstruction in real practice such as 3D Computed Tomography (CT). Due to the demanding memory, time, and data requirements, it is difficult to train a diffusion model directly on the entire volume of high-dimensional data to obtain an efficient 3D diffusion prior. Existing works utilizing diffusion priors on single 2D image slice with hand-crafted cross-slice regularization would sacrifice the z-axis consistency, which results in severe artifacts along the z-axis. In this work, we propose a novel framework that enables learning the 3D image prior through position-aware 3D-patch diffusion score blending for reconstructing large-scale 3D medical images. To the best of our knowledge, we are the first to utilize a 3D-patch diffusion prior for 3D medical image reconstruction. Extensive experiments on sparse view and limited angle CT reconstruction show that our DiffusionBlend method significantly outperforms previous methods and achieves state-of-the-art performance on real-world CT reconstruction problems with high-dimensional 3D image (i.e., $256 times 256 times 500$). Our algorithm also comes with better or comparable computational efficiency than previous state-of-the-art methods.
6/17/2024