Differential contributions of machine learning and statistical analysis to language and cognitive sciences
2404.14052
0
0
Abstract
Data-driven approaches have revolutionized scientific research. Machine learning and statistical analysis are commonly utilized in this type of research. Despite their widespread use, these methodologies differ significantly in their techniques and objectives. Few studies have utilized a consistent dataset to demonstrate these differences within the social sciences, particularly in language and cognitive sciences. This study leverages the Buckeye Speech Corpus to illustrate how both machine learning and statistical analysis are applied in data-driven research to obtain distinct insights. This study significantly enhances our understanding of the diverse approaches employed in data-driven strategies.
Create account to get full access
Overview
- Compares the contributions of machine learning and statistical analysis to language and cognitive sciences
- Discusses the relationship and differences between statistics and machine learning
- Examines the applications of these techniques in language and cognitive research
- Provides insights into how they can complement each other to advance scientific understanding
Plain English Explanation
This paper explores the distinct contributions that machine learning and statistical analysis can make to language and cognitive science research. Machine learning is a field of artificial intelligence that allows computers to learn patterns from data without being explicitly programmed, while statistical analysis involves using mathematical techniques to analyze and interpret data.
The authors explain that while these two approaches are related, they have important differences. Machine learning is often focused on making accurate predictions, while statistical analysis is more concerned with understanding the underlying relationships and causal mechanisms in the data. They discuss how each technique can be valuable in different types of language and cognitive research, such as modeling language or understanding large datasets.
The paper also examines how machine learning and statistical analysis can complement each other, with machine learning providing powerful predictive models and statistical analysis offering insights into the interpretability and significance of the results. By using a combination of these approaches, researchers may be able to gain a more comprehensive understanding of the complex phenomena in language and cognitive science.
Technical Explanation
The paper begins by discussing the relationship and differences between statistics and machine learning. While both involve the analysis of data, the authors explain that statistics is primarily focused on understanding the underlying processes and causal relationships, while machine learning is more concerned with making accurate predictions. They highlight how these two approaches can be complementary, with statistical analysis providing insights into the interpretability and significance of machine learning models.
The paper then explores the applications of machine learning and statistical analysis in language and cognitive science research. For example, the authors discuss how machine learning techniques can be used to model language and analyze large datasets, while statistical analysis can help researchers understand the underlying mechanisms and combine experimental data.
The key insight of the paper is that by leveraging the strengths of both machine learning and statistical analysis, researchers in language and cognitive science can gain a more comprehensive understanding of the complex phenomena they study. The authors suggest that a combination of these approaches can lead to more robust and interpretable findings, ultimately advancing the field.
Critical Analysis
The paper provides a thoughtful and balanced perspective on the contributions of machine learning and statistical analysis to language and cognitive science research. The authors acknowledge the distinct strengths and limitations of each approach, and they make a compelling case for the value of integrating these techniques.
One potential limitation of the research is that it does not delve deeply into the specific methodologies or case studies that demonstrate the complementary nature of machine learning and statistical analysis. While the conceptual framework is well-explained, some readers may have wished for more concrete examples or empirical evidence to support the claims.
Additionally, the paper does not address some of the potential challenges or ethical considerations that may arise when applying these techniques, such as the interpretability of complex machine learning models or the potential for biases in large datasets. Addressing these issues could have strengthened the critical analysis and encouraged readers to think more broadly about the implications of these powerful tools.
Overall, the paper offers a valuable contribution to the ongoing discussion about the role of data-driven techniques in language and cognitive science. By highlighting the unique strengths of machine learning and statistical analysis, the authors encourage researchers to adopt a more holistic and interdisciplinary approach to their work, ultimately leading to richer and more impactful insights.
Conclusion
This paper provides a nuanced exploration of the differential contributions of machine learning and statistical analysis to language and cognitive science research. The authors elucidate the relationship and key differences between these two approaches, demonstrating how they can be leveraged in complementary ways to advance scientific understanding.
By highlighting the unique strengths of each technique, the paper encourages researchers to adopt a more holistic and interdisciplinary approach to their work. This can lead to more robust and interpretable findings, ultimately driving progress in these important fields of study.
While the paper could have delved deeper into specific methodologies and case studies, it nevertheless offers a valuable conceptual framework for thinking about the role of data-driven techniques in language and cognitive science. As these fields continue to evolve, the insights provided in this paper will undoubtedly inform and shape future research endeavors.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Opportunities for machine learning in scientific discovery
Ricardo Vinuesa, Jean Rabault, Hossein Azizpour, Stefan Bauer, Bingni W. Brunton, Arne Elofsson, Elias Jarlebring, Hedvig Kjellstrom, Stefano Markidis, David Marlevi, Paola Cinnella, Steven L. Brunton
0
0
Technological advancements have substantially increased computational power and data availability, enabling the application of powerful machine-learning (ML) techniques across various fields. However, our ability to leverage ML methods for scientific discovery, {it i.e.} to obtain fundamental and formalized knowledge about natural processes, is still in its infancy. In this review, we explore how the scientific community can increasingly leverage ML techniques to achieve scientific discoveries. We observe that the applicability and opportunity of ML depends strongly on the nature of the problem domain, and whether we have full ({it e.g.}, turbulence), partial ({it e.g.}, computational biochemistry), or no ({it e.g.}, neuroscience) {it a-priori} knowledge about the governing equations and physical properties of the system. Although challenges remain, principled use of ML is opening up new avenues for fundamental scientific discoveries. Throughout these diverse fields, there is a theme that ML is enabling researchers to embrace complexity in observational data that was previously intractable to classic analysis and numerical investigations.
5/8/2024

Automated Statistical Model Discovery with Language Models
Michael Y. Li, Emily B. Fox, Noah D. Goodman
0
0
Statistical model discovery is a challenging search over a vast space of models subject to domain-specific constraints. Efficiently searching over this space requires expertise in modeling and the problem domain. Motivated by the domain knowledge and programming capabilities of large language models (LMs), we introduce a method for language model driven automated statistical model discovery. We cast our automated procedure within the principled framework of Box's Loop: the LM iterates between proposing statistical models represented as probabilistic programs, acting as a modeler, and critiquing those models, acting as a domain expert. By leveraging LMs, we do not have to define a domain-specific language of models or design a handcrafted search procedure, which are key restrictions of previous systems. We evaluate our method in three settings in probabilistic modeling: searching within a restricted space of models, searching over an open-ended space, and improving expert models under natural language constraints (e.g., this model should be interpretable to an ecologist). Our method identifies models on par with human expert designed models and extends classic models in interpretable ways. Our results highlight the promise of LM-driven model discovery.
6/26/2024

Are Large Language Models Good Statisticians?
Yizhang Zhu, Shiyin Du, Boyan Li, Yuyu Luo, Nan Tang
0
0
Large Language Models (LLMs) have demonstrated impressive capabilities across a range of scientific tasks including mathematics, physics, and chemistry. Despite their successes, the effectiveness of LLMs in handling complex statistical tasks remains systematically under-explored. To bridge this gap, we introduce StatQA, a new benchmark designed for statistical analysis tasks. StatQA comprises 11,623 examples tailored to evaluate LLMs' proficiency in specialized statistical tasks and their applicability assessment capabilities, particularly for hypothesis testing methods. We systematically experiment with representative LLMs using various prompting strategies and show that even state-of-the-art models such as GPT-4o achieve a best performance of only 64.83%, indicating significant room for improvement. Notably, while open-source LLMs (e.g. LLaMA-3) show limited capability, those fine-tuned ones exhibit marked improvements, outperforming all in-context learning-based methods (e.g. GPT-4o). Moreover, our comparative human experiments highlight a striking contrast in error types between LLMs and humans: LLMs primarily make applicability errors, whereas humans mostly make statistical task confusion errors. This divergence highlights distinct areas of proficiency and deficiency, suggesting that combining LLM and human expertise could lead to complementary strengths, inviting further investigation into their collaborative potential.
6/13/2024
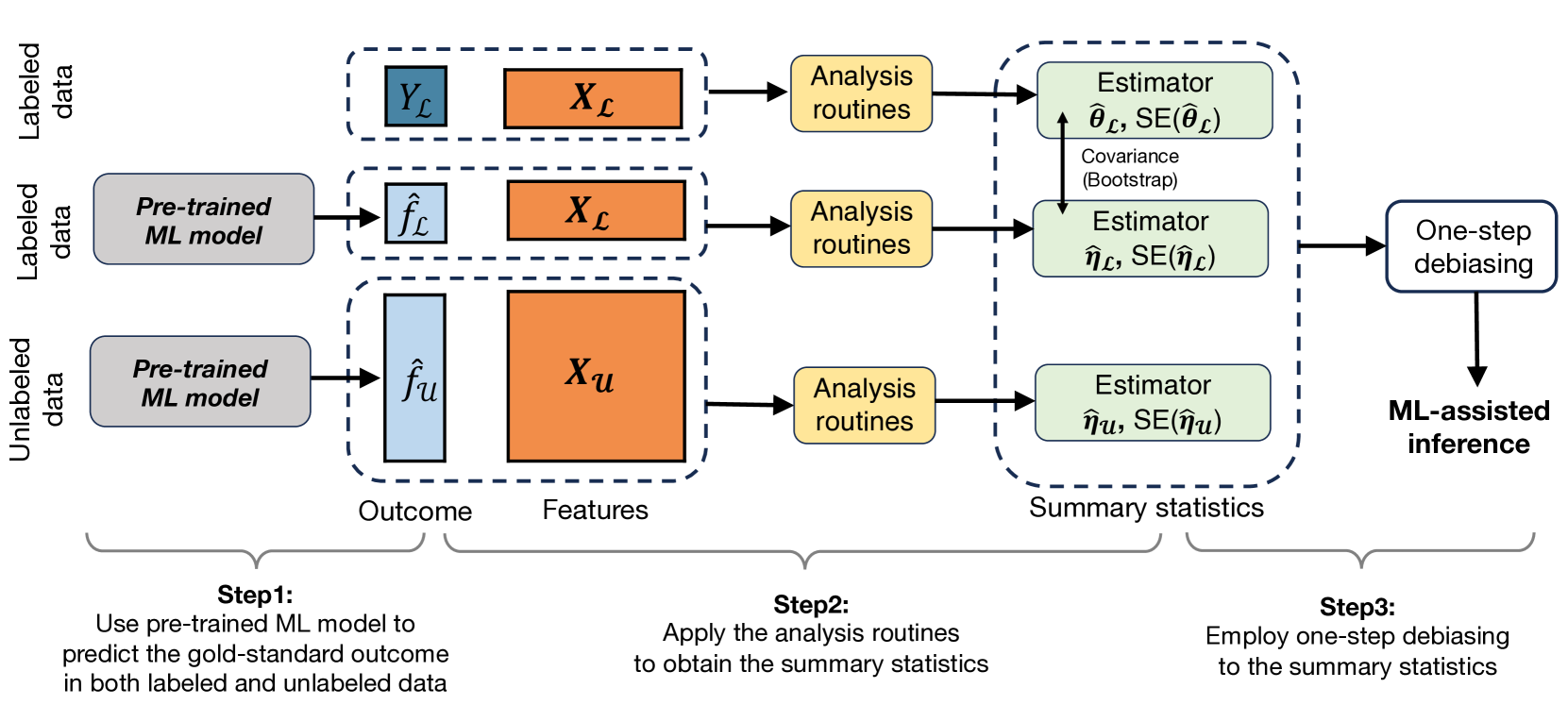
Task-Agnostic Machine Learning-Assisted Inference
Jiacheng Miao, Qiongshi Lu
0
0
Machine learning (ML) is playing an increasingly important role in scientific research. In conjunction with classical statistical approaches, ML-assisted analytical strategies have shown great promise in accelerating research findings. This has also opened up a whole new field of methodological research focusing on integrative approaches that leverage both ML and statistics to tackle data science challenges. One type of study that has quickly gained popularity employs ML to predict unobserved outcomes in massive samples and then uses the predicted outcomes in downstream statistical inference. However, existing methods designed to ensure the validity of this type of post-prediction inference are limited to very basic tasks such as linear regression analysis. This is because any extension of these approaches to new, more sophisticated statistical tasks requires task-specific algebraic derivations and software implementations, which ignores the massive library of existing software tools already developed for complex inference tasks and severely constrains the scope of post-prediction inference in real applications. To address this challenge, we propose a novel statistical framework for task-agnostic ML-assisted inference. It provides a post-prediction inference solution that can be easily plugged into almost any established data analysis routine. It delivers valid and efficient inference that is robust to arbitrary choices of ML models, while allowing nearly all existing analytical frameworks to be incorporated into the analysis of ML-predicted outcomes. Through extensive experiments, we showcase the validity, versatility, and superiority of our method compared to existing approaches.
5/31/2024