A Differential Dynamic Programming Framework for Inverse Reinforcement Learning

0
Sign in to get full access
Overview
- Inverse Reinforcement Learning (IRL) is a technique that aims to infer a reward function from observed behavior.
- This paper presents a new Differential Dynamic Programming (DDP) framework for solving the IRL problem.
- The key idea is to formulate IRL as an inverse optimal control problem and solve it using a DDP approach.
- This allows the method to handle complex, non-linear dynamics and constraints, which is an improvement over previous IRL techniques.
Plain English Explanation
The paper tackles the problem of Inverse Reinforcement Learning (IRL). In IRL, the goal is to figure out the reward function that best explains the observed behavior of an agent, such as a human. This is useful for understanding what motivates people's actions and can help in designing better reinforcement learning systems.
The authors propose a new approach to solving the IRL problem. Instead of trying to directly learn the reward function, they formulate IRL as an inverse optimal control problem. This means they try to find the reward function that would lead an optimal control system to behave like the observed agent.
To solve this inverse optimal control problem, the researchers use a technique called Differential Dynamic Programming (DDP). DDP is a powerful optimization method that can handle complex, non-linear dynamics and constraints. This is an advantage over previous IRL methods, which were often limited to simpler, linear settings.
The key idea is to use DDP to efficiently search for the reward function that best explains the observed behavior. By formulating the problem in this way, the authors are able to develop a new IRL algorithm that is more flexible and can be applied to a wider range of real-world scenarios.
Technical Explanation
The paper presents a new Differential Dynamic Programming (DDP) framework for solving the Inverse Reinforcement Learning (IRL) problem.
The authors formulate the IRL problem as an inverse optimal control problem, where the goal is to find the reward function that would lead an optimal control system to behave like the observed agent. They then solve this inverse optimal control problem using a DDP approach.
DDP is a powerful optimization technique that can handle complex, non-linear dynamics and constraints. This is a key advantage over previous IRL methods, which were often limited to simpler, linear settings.
The DDP framework consists of two main components:
- Primal DDP: This component solves the forward optimal control problem, finding the optimal state and control trajectories given a reward function.
- Dual DDP: This component solves the inverse optimal control problem, finding the reward function that best explains the observed behavior.
The authors develop efficient algorithms for both the primal and dual DDP problems, allowing them to iteratively refine the estimated reward function. They demonstrate the effectiveness of their approach on several simulated benchmarks, showing that it can outperform existing IRL methods.
Critical Analysis
The paper presents a novel and promising approach to Inverse Reinforcement Learning by formulating it as an inverse optimal control problem and solving it using Differential Dynamic Programming.
One key strength of the method is its ability to handle complex, non-linear dynamics and constraints, which is an important limitation of many previous IRL techniques. This makes the approach more applicable to real-world scenarios with realistic system dynamics.
However, the paper does not discuss the scalability of the DDP-based IRL algorithm, particularly when dealing with high-dimensional state and action spaces. The computational complexity of the method may be a concern for large-scale problems.
Additionally, the paper only presents results on simulated benchmarks, and it would be valuable to see the method applied to real-world datasets and tasks to better understand its practical performance and limitations.
Finally, the authors do not provide a thorough discussion of the potential biases or errors that may arise in the estimated reward functions, and how these could impact the use of the learned models in downstream applications.
Overall, the paper presents an interesting and potentially impactful contribution to the field of Inverse Reinforcement Learning, but further research is needed to fully understand the strengths, weaknesses, and practical applicability of the proposed DDP-based framework.
Conclusion
This paper introduces a new Differential Dynamic Programming (DDP) framework for solving the Inverse Reinforcement Learning (IRL) problem. By formulating IRL as an inverse optimal control problem, the authors are able to leverage the power of DDP to handle complex, non-linear dynamics and constraints.
The proposed approach shows promise in its ability to learn reward functions that better explain observed behavior compared to previous IRL techniques. However, further research is needed to address scalability concerns and validate the method's performance on real-world datasets.
Overall, this work represents an interesting and potentially impactful contribution to the field of Inverse Reinforcement Learning, providing a new framework that could lead to improved understanding of human decision-making and more effective reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Differential Dynamic Programming Framework for Inverse Reinforcement Learning
Kun Cao, Xinhang Xu, Wanxin Jin, Karl H. Johansson, Lihua Xie
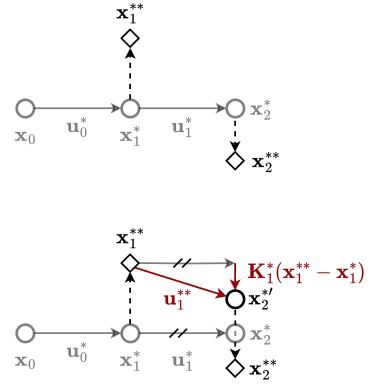
A differential dynamic programming (DDP)-based framework for inverse reinforcement learning (IRL) is introduced to recover the parameters in the cost function, system dynamics, and constraints from demonstrations. Different from existing work, where DDP was used for the inner forward problem with inequality constraints, our proposed framework uses it for efficient computation of the gradient required in the outer inverse problem with equality and inequality constraints. The equivalence between the proposed method and existing methods based on Pontryagin's Maximum Principle (PMP) is established. More importantly, using this DDP-based IRL with an open-loop loss function, a closed-loop IRL framework is presented. In this framework, a loss function is proposed to capture the closed-loop nature of demonstrations. It is shown to be better than the commonly used open-loop loss function. We show that the closed-loop IRL framework reduces to a constrained inverse optimal control problem under certain assumptions. Under these assumptions and a rank condition, it is proven that the learning parameters can be recovered from the demonstration data. The proposed framework is extensively evaluated through four numerical robot examples and one real-world quadrotor system. The experiments validate the theoretical results and illustrate the practical relevance of the approach.
Read more7/30/2024
🐍
0
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
Read more6/5/2024
🏅
0
Stable Inverse Reinforcement Learning: Policies from Control Lyapunov Landscapes
Samuel Tesfazgi, Leonhard Sprandl, Armin Lederer, Sandra Hirche
Learning from expert demonstrations to flexibly program an autonomous system with complex behaviors or to predict an agent's behavior is a powerful tool, especially in collaborative control settings. A common method to solve this problem is inverse reinforcement learning (IRL), where the observed agent, e.g., a human demonstrator, is assumed to behave according to the optimization of an intrinsic cost function that reflects its intent and informs its control actions. While the framework is expressive, it is also computationally demanding and generally lacks convergence guarantees. We therefore propose a novel, stability-certified IRL approach by reformulating the cost function inference problem to learning control Lyapunov functions (CLF) from demonstrations data. By additionally exploiting closed-form expressions for associated control policies, we are able to efficiently search the space of CLFs by observing the attractor landscape of the induced dynamics. For the construction of the inverse optimal CLFs, we use a Sum of Squares and formulate a convex optimization problem. We present a theoretical analysis of the optimality properties provided by the CLF and evaluate our approach using both simulated and real-world data.
Read more5/15/2024

0
Defining Problem from Solutions: Inverse Reinforcement Learning (IRL) and Its Applications for Next-Generation Networking
Yinqiu Liu, Ruichen Zhang, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Dong In Kim
Performance optimization is a critical concern in networking, on which Deep Reinforcement Learning (DRL) has achieved great success. Nonetheless, DRL training relies on precisely defined reward functions, which formulate the optimization objective and indicate the positive/negative progress towards the optimal. With the ever-increasing environmental complexity and human participation in Next-Generation Networking (NGN), defining appropriate reward functions become challenging. In this article, we explore the applications of Inverse Reinforcement Learning (IRL) in NGN. Particularly, if DRL aims to find optimal solutions to the problem, IRL finds a problem from the optimal solutions, where the optimal solutions are collected from experts, and the problem is defined by reward inference. Specifically, we first formally introduce the IRL technique, including its fundamentals, workflow, and difference from DRL. Afterward, we present the motivations of IRL applications in NGN and survey existing studies. Furthermore, to demonstrate the process of applying IRL in NGN, we perform a case study about human-centric prompt engineering in Generative AI-enabled networks. We demonstrate the effectiveness of using both DRL and IRL techniques and prove the superiority of IRL.
Read more4/3/2024