Differentially Private Next-Token Prediction of Large Language Models
2403.15638
0
0

Abstract
Ensuring the privacy of Large Language Models (LLMs) is becoming increasingly important. The most widely adopted technique to accomplish this is DP-SGD, which trains a model to guarantee Differential Privacy (DP). However, DP-SGD overestimates an adversary's capabilities in having white box access to the model and, as a result, causes longer training times and larger memory usage than SGD. On the other hand, commercial LLM deployments are predominantly cloud-based; hence, adversarial access to LLMs is black-box. Motivated by these observations, we present Private Mixing of Ensemble Distributions (PMixED): a private prediction protocol for next-token prediction that utilizes the inherent stochasticity of next-token sampling and a public model to achieve Differential Privacy. We formalize this by introducing RD-mollifers which project each of the model's output distribution from an ensemble of fine-tuned LLMs onto a set around a public LLM's output distribution, then average the projected distributions and sample from it. Unlike DP-SGD which needs to consider the model architecture during training, PMixED is model agnostic, which makes PMixED a very appealing solution for current deployments. Our results show that PMixED achieves a stronger privacy guarantee than sample-level privacy and outperforms DP-SGD for privacy $epsilon = 8$ on large-scale datasets. Thus, PMixED offers a practical alternative to DP training methods for achieving strong generative utility without compromising privacy.
Create account to get full access
Overview
- This paper explores a novel approach to differentially private next-token prediction for large language models (LLMs).
- Differential privacy is a key technique for preserving user privacy in machine learning models.
- The authors propose a method to train LLMs in a differentially private manner, allowing them to make accurate predictions while protecting the privacy of the training data.
- The research has important implications for the development of privacy-preserving AI systems, as demonstrated in related work such as Can Public Large Language Models Help Private?, DP-RDM: Adapting Diffusion Models to Private, and LazyDP: Co-Designing Algorithm & Software for Scalable Training.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, training these models often requires collecting and using large amounts of personal data, which raises privacy concerns. Differential privacy is a technique that can help protect the privacy of this data by adding noise to the model's outputs, making it difficult to infer specific details about the training data.
In this paper, the researchers developed a new method for training LLMs in a differentially private way. This means the model can still make accurate predictions, but it's much harder for someone to figure out the details of the original training data. The researchers tested their approach on a next-token prediction task, where the model has to guess the next word in a sequence of text.
The key innovation is that the researchers found a way to add the necessary privacy-preserving noise to the model's predictions without significantly reducing the model's accuracy. This is important because it means the model can still be useful for practical applications, even with the added privacy protections.
Overall, this research represents an important step towards developing AI systems that can provide the benefits of LLMs while also respecting the privacy of the individuals whose data was used to train them. This could have far-reaching implications for the development of privacy-preserving AI technologies.
Technical Explanation
The paper introduces a differentially private next-token prediction method for large language models (LLMs). Differential privacy is a powerful technique for preserving the privacy of training data by adding carefully calibrated noise to the model's outputs.
The researchers developed a novel approach to differentially private next-token prediction, which involves two key components:
-
Differentially Private Token Sampling: The model's output distribution over the next token is perturbed with carefully calibrated noise to satisfy differential privacy guarantees. This ensures that the model's predictions do not reveal sensitive information about the training data.
-
Differentially Private Logit Clipping: The model's logits (the raw, pre-softmax outputs) are clipped to a fixed range before the noise is added. This helps preserve the model's accuracy while still providing strong privacy guarantees.
The researchers evaluated their method on several next-token prediction tasks using large language models. They found that their approach could achieve strong privacy protections while maintaining high prediction accuracy, outperforming previous differentially private LLM techniques.
This work builds on and complements other recent research in privacy-preserving AI, such as DP-RDM: Adapting Diffusion Models to Private, LazyDP: Co-Designing Algorithm & Software for Scalable Training, and Can Public Large Language Models Help Private?. By developing new techniques for differentially private LLM training, this research helps advance the state of the art in privacy-preserving AI systems.
Critical Analysis
The paper presents a compelling approach to differentially private next-token prediction for large language models. The authors' key innovations, such as differentially private token sampling and logit clipping, appear to be well-designed and effective at balancing privacy and utility.
However, the paper does not discuss some potential limitations or caveats of their approach. For example, it's unclear how the method would scale to extremely large language models or if there are any fundamental limits to the level of privacy that can be achieved without significantly degrading the model's performance.
Additionally, the authors do not address potential societal impacts or ethical considerations of their work. As privacy-preserving AI systems become more prevalent, it will be important to carefully consider the implications, both positive and negative, that these technologies may have on individuals and communities.
Despite these minor shortcomings, the research presented in this paper represents an important contribution to the field of privacy-preserving machine learning. The authors' novel techniques and thorough evaluations provide a solid foundation for further developments in this area, as demonstrated in related work such as PAC: Privacy-Preserving Diffusion Models.
Conclusion
This paper introduces a novel approach to differentially private next-token prediction for large language models, which is a crucial step towards developing privacy-preserving AI systems. By carefully balancing the need for privacy with the desire for accurate predictions, the researchers have devised a technique that could have significant implications for the future of language modeling and other AI applications.
As the use of large language models continues to expand, the importance of safeguarding individual privacy will only grow. The work presented in this paper, along with related research in the field, highlights the potential for AI systems to be designed with privacy in mind from the ground up. This could lead to a future where the benefits of powerful language models can be enjoyed without compromising the personal information of the individuals whose data was used to train them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LMO-DP: Optimizing the Randomization Mechanism for Differentially Private Fine-Tuning (Large) Language Models
Qin Yang, Meisam Mohammad, Han Wang, Ali Payani, Ashish Kundu, Kai Shu, Yan Yan, Yuan Hong
0
0
Differentially Private Stochastic Gradient Descent (DP-SGD) and its variants have been proposed to ensure rigorous privacy for fine-tuning large-scale pre-trained language models. However, they rely heavily on the Gaussian mechanism, which may overly perturb the gradients and degrade the accuracy, especially in stronger privacy regimes (e.g., the privacy budget $epsilon < 3$). To address such limitations, we propose a novel Language Model-based Optimal Differential Privacy (LMO-DP) mechanism, which takes the first step to enable the tight composition of accurately fine-tuning (large) language models with a sub-optimal DP mechanism, even in strong privacy regimes (e.g., $0.1leq epsilon<3$). Furthermore, we propose a novel offline optimal noise search method to efficiently derive the sub-optimal DP that significantly reduces the noise magnitude. For instance, fine-tuning RoBERTa-large (with 300M parameters) on the SST-2 dataset can achieve an accuracy of 92.20% (given $epsilon=0.3$, $delta=10^{-10}$) by drastically outperforming the Gaussian mechanism (e.g., $sim 50%$ for small $epsilon$ and $delta$). We also draw similar findings on the text generation tasks on GPT-2. Finally, to our best knowledge, LMO-DP is also the first solution to accurately fine-tune Llama-2 with strong differential privacy guarantees. The code will be released soon and available upon request.
5/30/2024
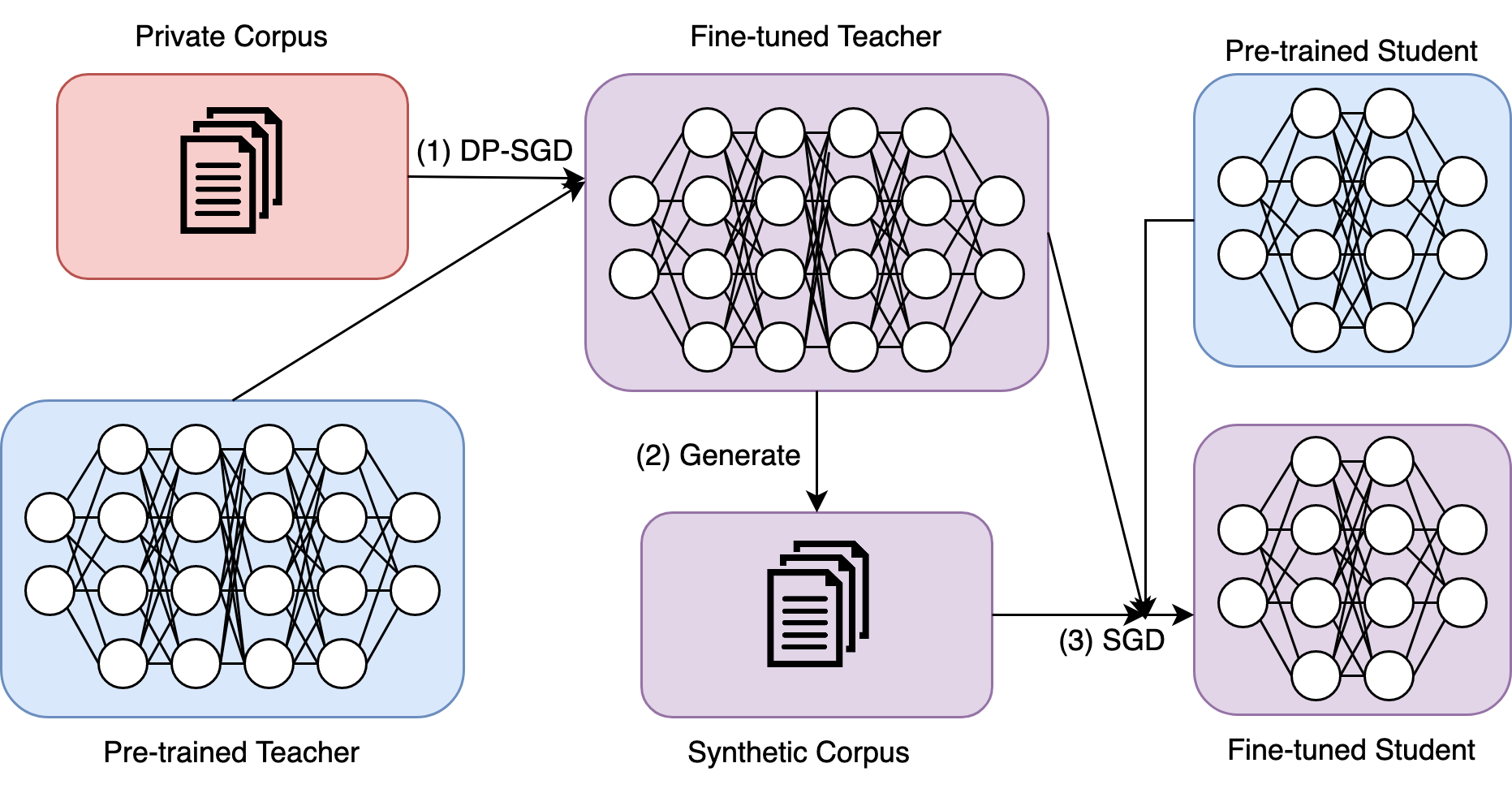
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024
🔄
Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
Dariush Wahdany, Matthew Jagielski, Adam Dziedzic, Franziska Boenisch
0
0
Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($varepsilonle1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.
6/13/2024

Mind the Privacy Unit! User-Level Differential Privacy for Language Model Fine-Tuning
Lynn Chua, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Daogao Liu, Pasin Manurangsi, Amer Sinha, Chiyuan Zhang
0
0
Large language models (LLMs) have emerged as powerful tools for tackling complex tasks across diverse domains, but they also raise privacy concerns when fine-tuned on sensitive data due to potential memorization. While differential privacy (DP) offers a promising solution by ensuring models are `almost indistinguishable' with or without any particular privacy unit, current evaluations on LLMs mostly treat each example (text record) as the privacy unit. This leads to uneven user privacy guarantees when contributions per user vary. We therefore study user-level DP motivated by applications where it necessary to ensure uniform privacy protection across users. We present a systematic evaluation of user-level DP for LLM fine-tuning on natural language generation tasks. Focusing on two mechanisms for achieving user-level DP guarantees, Group Privacy and User-wise DP-SGD, we investigate design choices like data selection strategies and parameter tuning for the best privacy-utility tradeoff.
6/21/2024